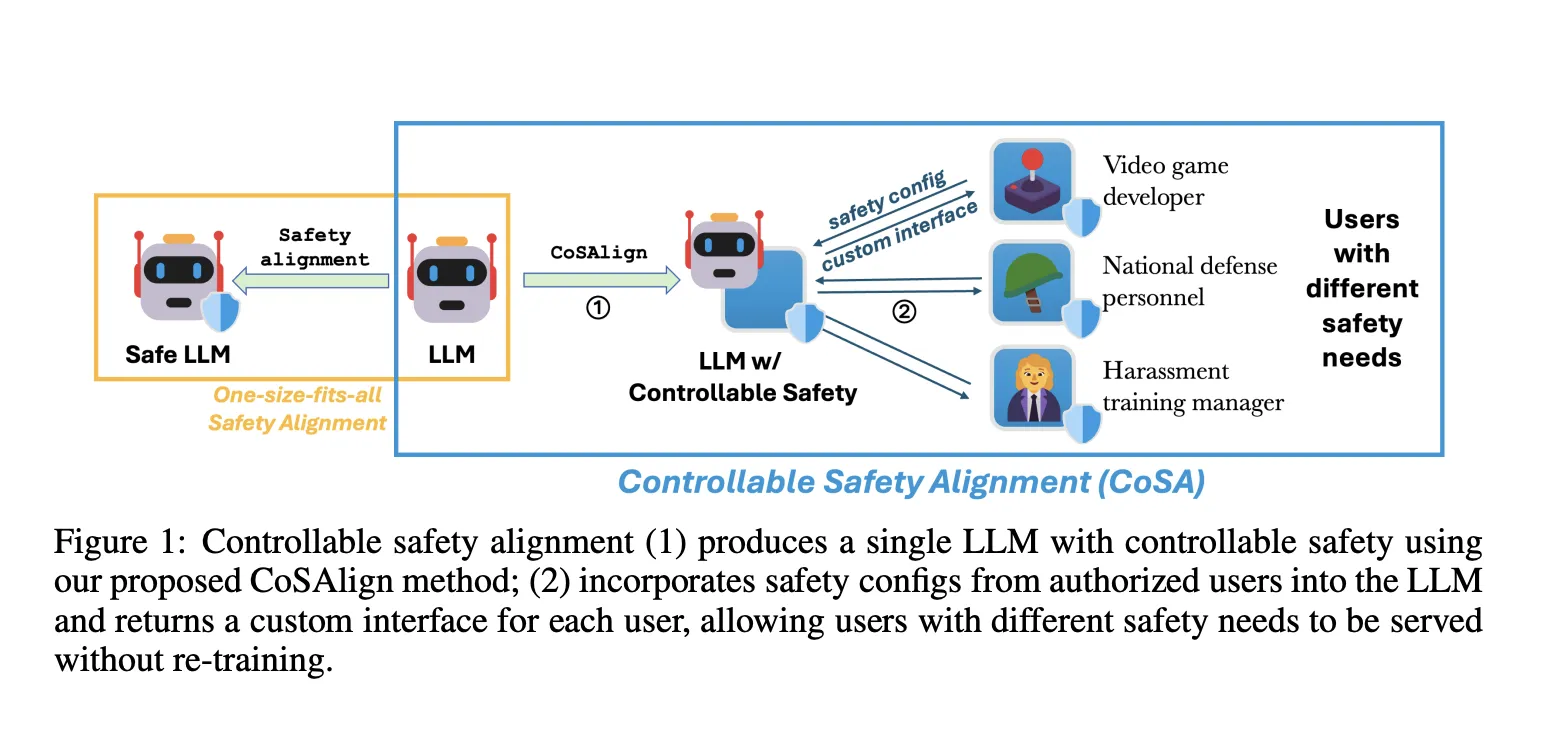
As massive language fashions (LLMs) change into more and more succesful and higher day-to-day, their security has change into a important matter for analysis. To create a secure mannequin, mannequin suppliers normally pre-define a coverage or a algorithm. These guidelines assist to make sure the mannequin follows a hard and fast set of rules, leading to a mannequin that works the identical for everybody. Whereas the present method works for common use circumstances, it essentially ignores the variability of security throughout cultures, purposes, or customers. Due to this fact, the plurality of human values, i.e., the present paradigm for security alignment of huge language fashions (LLMs) follows a one-size-fits-all method: the mannequin merely avoids interacting with any content material that the builders think about unsafe. In numerous circumstances, an ordinary one-size-fits-all secure mannequin is simply too restrictive to be useful. As well as, customers might have numerous security wants, making a mannequin with static security requirements too restrictive to be helpful, in addition to too expensive to be re-aligned. Therefore, this method lacks flexibility within the face of various social norms throughout cultures and areas. Customers might also have totally different security wants, which makes a mannequin with fastened security guidelines too limiting and costly to regulate.
Present strategies contain pre-defining a hard and fast set of security rules that the mannequin should observe, which doesn’t adapt to totally different cultural or user-specific security wants. Pluralistic alignment Current works have underscored the importance of incorporating pluralistic human values and cultures in AI alignment. Some work explores enhancing pluralism normally or research the reliability of the one-size-fits-all mannequin in pluralistic settings, however none of them centered on pluralistic security alignment. Some researchers highlighted that AI ought to have “normative competence,” that means the flexibility to grasp and alter to numerous norms, selling security pluralism. Constitutional AI develops a single “structure,” i.e., a set of common guidelines that fashions ought to observe, after which trains the structure right into a one-size-fits-all mannequin, which nonetheless requires re-training the mannequin if the structure adjustments.
An in-context alignment is an method that adjusts the mannequin’s conduct based mostly on context. Nonetheless, it has limitations as a result of complexity of the security configurations and the problem of constructing high quality demonstrations. Different strategies embrace retraining and parameter merging to attain multi-objective alignment. Some strategies management the mannequin by utilizing instruction hierarchy (IH), which provides totally different significance to directions. Nonetheless, IH has its limitations and various approaches, akin to rule-based rewards i.e. it fails to supply real-time adaptation.
A workforce of researchers from Microsoft Accountable AI Analysis and Johns Hopkins College proposed Controllable Security Alignment (CoSA), a framework for environment friendly inference-time adaptation to numerous security necessities.
The tailored technique first produces an LLM that’s simply controllable for security. Fashions are adjusted to observe particular “security configs,” which describe what content material is allowed or not allowed. To satisfy the distinctive security wants of customers, the mannequin makes use of security configs supplied by trusted folks, like security consultants in a online game firm, as a part of its setup. A overview course of ensures the safety of the mannequin. This permits the mannequin to adapt its security settings throughout use with out retraining, and customers can entry the custom-made mannequin by way of particular interfaces, like particular API endpoints.
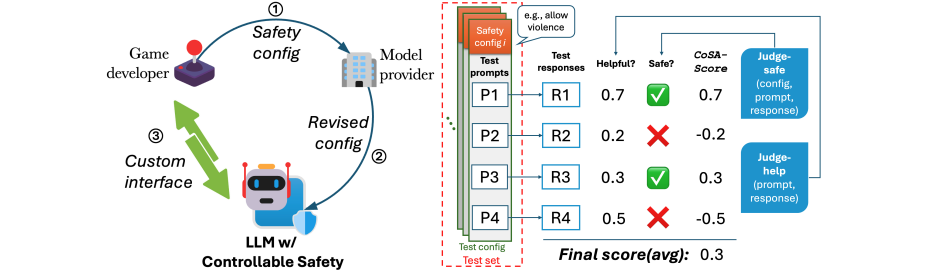
The CoSA mission goals to develop AI fashions that may meet particular security necessities, particularly for content material associated to online game improvement. They created a brand new technique to judge and assess the mannequin’s helpfulness and security, utilizing take a look at configurations with security pointers and prompts that fall into three classes: absolutely allowed, absolutely disallowed, and combined. The responses of the mannequin are scored on these standards. The researchers developed CoSApien, a manually crafted analysis dataset designed to carefully replicate real-world security situations. CoSApien is a benchmark designed to carefully take a look at the mannequin’s security management, using 5 security pointers and 40 take a look at prompts for every guideline, addressing numerous security and cultural wants with clear pointers on acceptable dangerous content material.
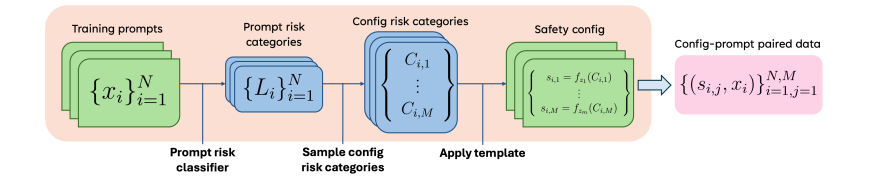
To facilitate the reproducible analysis of CoSA, they suggest a novel analysis protocol that considers each the helpfulness and configured security of mannequin responses, summarizing them right into a single CoSA-Rating that represents the general mannequin controllability. The evaluation discovered that utilizing in-context alignment for fashions with controllable security doesn’t work nicely as a result of security configs are complicated and it’s exhausting to create good examples for them on a big scale. This made researchers current CoSAlign, a data-centric technique that improves the controllability of mannequin security. CoSAlign begins by creating a listing of threat classes from the coaching prompts and makes use of a system with a choose mannequin and error scoring to generate assorted choice knowledge. It then builds extra controllable fashions by way of choice optimization. In comparison with sturdy baseline fashions, CoSAlign tremendously enhances the flexibility to regulate security configurations that had been used throughout coaching and in addition performs nicely with new security configurations that it hasn’t seen earlier than.
The CoSAlign technique considerably outperforms present strategies, together with sturdy cascade strategies utilizing a GPT-4o evaluator, by attaining larger CoSA-Scores and generalizing nicely to new security configurations. It will increase the variety of useful and secure responses whereas it reduces useful however unsafe ones. The preliminary fine-tuning stage (SFT) improves the efficiency of the mannequin however might enhance unsafe responses, making the following choice optimization stage (DPO) important for additional enhancing security. Evaluations with the CoSApien benchmark present CoSAlign persistently surpassing all strategies, together with the Cascade-Oracle method. General, CoSAlign proves simpler than security elimination, with the potential for even higher controllability by way of choice optimization.
In abstract, the present security alignment paradigm proposes the controllable security alignment framework, a blueprint towards inference-time LLM security adjustment with out re-training. The researchers introduced a set of contributions, together with our human-authored benchmark (CoSApien), analysis protocol (CoSA-Rating), and technique towards improved controllability (CoSAlign). After conducting in depth common security evaluations, they discover CoSAlign fashions sturdy. The principle limitation is that the researchers didn’t systematically discover how CoSAlign scales with totally different mannequin sizes. The framework is proscribed to security and cultural alignment that may be described in pure language, which excludes implicit cultural and social norms. In the long run, this framework encourages higher illustration and adaptation to pluralistic human values in LLMs, thereby rising their practicality.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.


