
Giant language fashions (LLMs) have demonstrated constant scaling legal guidelines, revealing a power-law relationship between pretraining efficiency and computational sources. This relationship, expressed as C = 6ND (the place C is compute, N is mannequin measurement, and D is information amount), has confirmed invaluable for optimizing useful resource allocation and maximizing computational effectivity. Nevertheless, the sphere of diffusion fashions, notably diffusion transformers (DiT), lacks related complete scaling legal guidelines. Whereas bigger diffusion fashions have proven improved visible high quality and text-image alignment, the exact nature of their scaling properties stays unclear. This hole in understanding hinders the power to precisely predict coaching outcomes, decide optimum mannequin and information sizes for given compute budgets, and comprehend the intricate relationships between coaching sources, mannequin structure, and efficiency. Consequently, researchers should depend on pricey and probably suboptimal heuristic configuration searches, impeding environment friendly progress within the subject.
Earlier analysis has explored scaling legal guidelines in varied domains, notably in language fashions and autoregressive generative fashions. These research have established predictable relationships between mannequin efficiency, measurement, and dataset amount. Within the realm of diffusion fashions, latest work has empirically demonstrated scaling properties, exhibiting that bigger compute budgets typically yield higher fashions. Researchers have additionally in contrast scaling behaviors throughout completely different architectures and investigated sampling effectivity. Nevertheless, the sphere lacks an express formulation of scaling legal guidelines for diffusion transformers that captures the intricate relationships between compute finances, mannequin measurement, information amount, and loss. This hole in understanding has restricted the power to optimize useful resource allocation and predict efficiency in diffusion transformer fashions.
Researchers from Shanghai Synthetic Intelligence Laboratory, The Chinese language College of Hong Kong, ByteDance, and The College of Hong Kong characterize the scaling habits of diffusion fashions for text-to-image synthesis, establishing express scaling legal guidelines for DiT. The examine explores a variety of compute budgets from 1e17 to 6e18 FLOPs, coaching fashions from 1M to 1B parameters. By becoming parabolas for every compute finances, optimum configurations are recognized, resulting in power-law relationships between compute budgets, mannequin measurement, consumed information, and coaching loss. The derived scaling legal guidelines are validated by way of extrapolation to larger compute budgets. Additionally, the analysis demonstrates that era efficiency metrics, corresponding to FID, observe related power-law relationships, enabling predictable synthesis high quality throughout varied datasets.
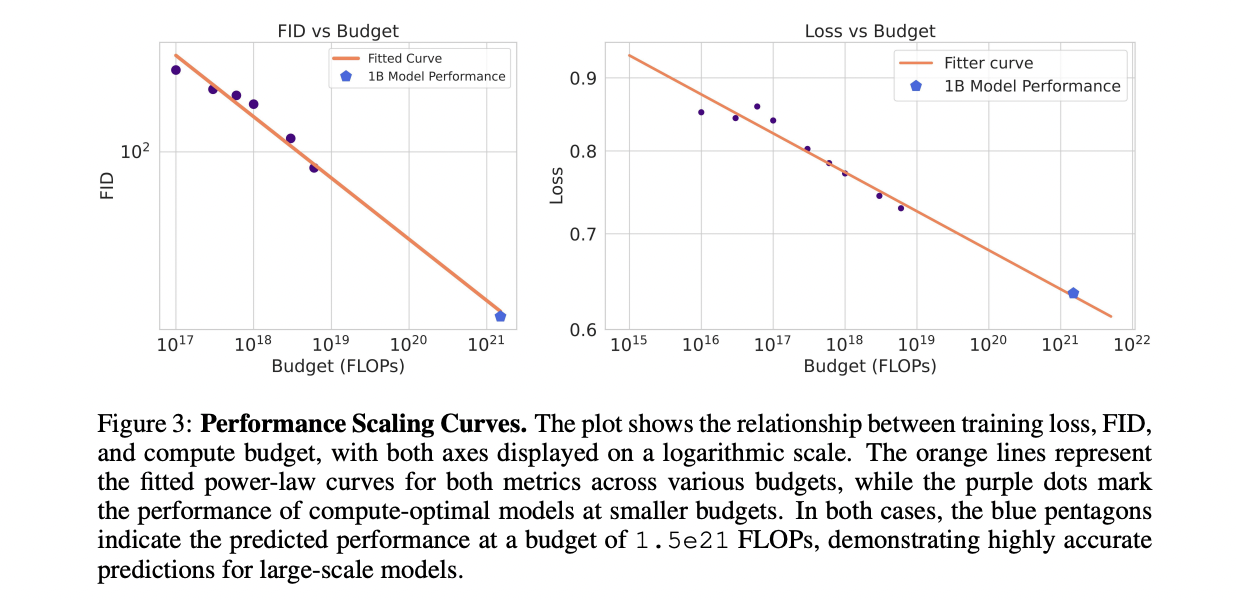
The examine explores scaling legal guidelines in diffusion transformers throughout compute budgets from 1e17 to 6e18 FLOPs. Researchers differ In-context Transformers from 2 to fifteen layers, utilizing AdamW optimizer with particular studying price schedules and hyperparameters. For every finances, they match a parabola to establish optimum loss, mannequin measurement, and information allocation. Energy legislation relationships are established between compute budgets and optimum mannequin measurement, information amount, and loss. The derived equations reveal that mannequin measurement grows barely sooner than information measurement as coaching finances will increase. To validate these legal guidelines, they extrapolate to a 1.5e21 FLOPs finances, coaching a 958.3M parameter mannequin that carefully matches predicted loss.
The examine validates scaling legal guidelines on out-of-domain datasets utilizing the COCO 2014 validation set. 4 metrics—validation loss, Variational Decrease Certain (VLB), precise chance, and Frechet Inception Distance (FID)—are evaluated on 10,000 information factors. Outcomes present constant developments throughout each Laion5B subset and COCO validation dataset, with efficiency bettering as coaching finances will increase. A vertical offset is noticed between metrics for the 2 datasets, with COCO constantly exhibiting larger values. This offset stays comparatively fixed for validation loss, VLB, and precise chance throughout budgets. For FID, the hole widens with growing finances, however nonetheless follows a power-law pattern.

Scaling legal guidelines present a sturdy framework for evaluating mannequin and dataset high quality. By analyzing isoFLOP curves at smaller compute budgets, researchers can assess the impression of modifications to mannequin structure or information pipeline. Extra environment friendly fashions exhibit decrease mannequin scaling exponents and better information scaling exponents, whereas higher-quality datasets lead to decrease information scaling exponents and better mannequin scaling exponents. Improved coaching pipelines are mirrored in smaller loss scaling exponents. The examine compares In-Context and Cross-Consideration Transformers, revealing that Cross-Consideration Transformers obtain higher efficiency with the identical compute finances. This method presents a dependable benchmark for evaluating design selections in mannequin and information pipelines.
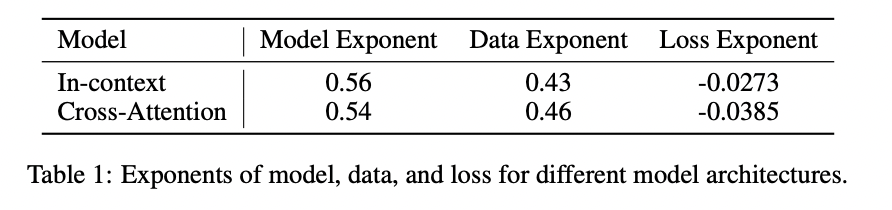
This examine establishes scaling legal guidelines for DiT throughout a variety of compute budgets. The analysis confirms a power-law relationship between pretraining loss and compute, enabling correct predictions of optimum mannequin measurement, information necessities, and efficiency. The scaling legal guidelines reveal robustness throughout completely different datasets and may predict picture era high quality utilizing metrics like FID. By evaluating In-context and Cross-Consideration Transformers, the examine validates using scaling legal guidelines as a benchmark for evaluating mannequin and information design. These findings present worthwhile steering for future developments in text-to-image era utilizing DiT, providing a framework for optimizing useful resource allocation and efficiency.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


