
Giant Language Fashions (LLMs) have demonstrated exceptional progress in pure language processing duties, inspiring researchers to discover related approaches for text-to-image synthesis. On the similar time, diffusion fashions have turn into the dominant strategy in visible technology. Nonetheless, the operational variations between the 2 approaches current a big problem in growing a unified methodology for language and imaginative and prescient duties. Current developments like LlamaGen have ventured into autoregressive picture technology utilizing discrete picture tokens; nonetheless, it’s inefficient because of the giant variety of picture tokens in comparison with textual content tokens. Non-autoregressive strategies like MaskGIT and MUSE have emerged, reducing down on the variety of decoding steps, however failing to provide high-quality, high-resolution pictures.
Current makes an attempt to unravel the challenges in text-to-image synthesis have primarily targeted on two approaches: diffusion-based and token-based picture technology. Diffusion fashions, like Steady Diffusion and SDXL, have made important progress by working inside compressed latent areas and introducing methods like micro-conditions and multi-aspect coaching. The combination of transformer architectures, as seen in DiT and U-ViT, has additional enhanced the potential of diffusion fashions. Nonetheless, these fashions nonetheless face challenges in real-time purposes and quantization. Token-based approaches like MaskGIT and MUSE, have launched masked picture modeling (MIM) to beat the computational calls for of autoregressive strategies.
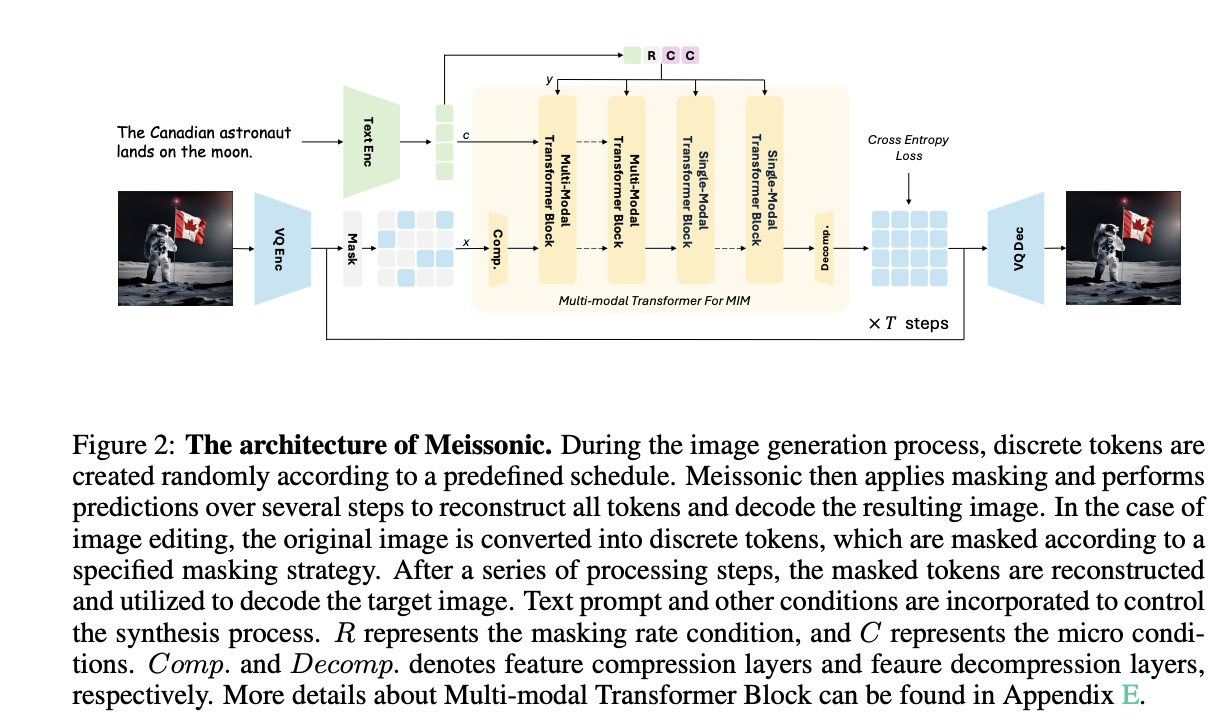
Researchers from Alibaba Group, Skywork AI, HKUST(GZ), HKUST, Zhejiang College, and UC Berkeley have proposed Meissonic, an revolutionary technique to raise non-autoregressive MIM text-to-image synthesis to a stage comparable with state-of-the-art diffusion fashions like SDXL. Meissonic makes use of a complete suite of architectural improvements, superior positional encoding methods, and optimized sampling circumstances to reinforce MIM’s efficiency and effectivity. The mannequin makes use of high-quality coaching information, micro-conditions knowledgeable by human desire scores, and have compression layers to enhance picture constancy and backbone. The Meissonic can produce 1024 × 1024 decision pictures and sometimes outperforms present fashions in producing high-quality, high-resolution pictures.
Meissonic’s structure integrates a CLIP textual content encoder, a vector-quantized (VQ) picture encoder and decoder, and a multi-modal Transformer spine for environment friendly high-performance text-to-image synthesis:
- The VQ-VAE mannequin converts uncooked picture pixels into discrete semantic tokens utilizing a realized codebook.
- A fine-tuned CLIP textual content encoder with a 1024 latent dimension is used for optimum efficiency.
- The multi-modal Transformer spine makes use of sampling parameters and Rotary Place Embeddings for spatial data encoding.
- Function compression layers are used to deal with high-resolution technology effectively.
The structure additionally consists of QK-Norm layers and implements gradient clipping to reinforce coaching stability and cut back NaN Loss points throughout distributed coaching.
Meissonic, optimized to 1 billion parameters, runs effectively on 8GB VRAM, making inference and fine-tuning handy. Qualitative comparisons present Meissonic’s picture high quality and text-image alignment capabilities. Human evaluations utilizing Ok-Type Area and GPT-4 assessments point out that Meissonic achieves efficiency akin to DALL-E 2 and SDXL in human desire and textual content alignment, with improved effectivity. Meissonic is benchmarked towards state-of-the-art fashions utilizing the EMU-Edit dataset in picture modifying duties, masking seven completely different operations. The mannequin demonstrated versatility in each mask-guided and mask-free modifying, attaining nice efficiency with out particular coaching on picture modifying information or instruction datasets.
In conclusion, researchers launched Meissonic, an strategy to raise non-autoregressive MIM text-to-image synthesis. The mannequin incorporates revolutionary components akin to a blended transformer structure, superior positional encoding, and adaptive masking charges to realize superior efficiency in high-resolution picture technology. Regardless of its compact 1B parameter measurement, Meissonic outperforms bigger diffusion fashions whereas remaining accessible on consumer-grade GPUs. Furthermore, Meissonic aligns with the rising pattern of offline text-to-image purposes on cell units, exemplified by current improvements from Google and Apple. It enhances the person expertise and privateness in cell imaging know-how, empowering customers with inventive instruments whereas making certain information safety.
Take a look at the Paper and Mannequin. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Advantageous-Tuned Fashions: Predibase Inference Engine (Promoted)

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


