
Giant language fashions (LLMs) have revolutionized numerous fields by enabling more practical information processing, complicated problem-solving, and pure language understanding. One main innovation is retrieval-augmented technology (RAG), which permits LLMs to retrieve related data from exterior sources, resembling massive information databases, to generate higher solutions. Nevertheless, the combination of long-context LLMs with RAG presents sure challenges. Particularly, whereas LLMs have gotten able to dealing with longer enter sequences, the rise in retrieved data can overwhelm the system. The problem lies in ensuring that the extra context improves the accuracy of the LLM’s outputs reasonably than complicated the mannequin with irrelevant data.
The issue confronted by long-context LLMs stems from a phenomenon the place rising the variety of retrieved passages doesn’t essentially enhance efficiency. As a substitute, it typically results in efficiency degradation, primarily as a result of together with irrelevant or deceptive paperwork referred to as “onerous negatives.” These onerous negatives seem related based mostly on sure retrieval standards however introduce noise that misguides the LLM in producing the right reply. In consequence, the mannequin’s accuracy declines regardless of gaining access to extra data. That is notably problematic for knowledge-intensive duties the place accurately figuring out related data is essential.
Present RAG methods make use of a retriever to pick probably the most related passages from a database, which the LLM then processes. Customary RAG implementations, nonetheless, usually restrict the variety of retrieved passages to round ten. This works nicely for shorter contexts however solely scales effectively when the variety of passages will increase. The problem turns into extra pronounced when coping with complicated datasets with a number of related passages. Present approaches should adequately tackle the dangers of introducing deceptive or irrelevant data, which might diminish the standard of LLM responses.
Researchers from Google Cloud AI and the College of Illinois launched modern strategies to enhance the robustness and efficiency of RAG methods when utilizing long-context LLMs. Their method encompasses training-free and training-based strategies designed to mitigate the impression of onerous negatives. One of many key improvements is retrieval reordering, a training-free methodology that improves the sequence wherein the retrieved passages are fed to the LLM. The researchers suggest prioritizing passages with larger relevance scores firstly and finish of the enter sequence, thus focusing the LLM’s consideration on a very powerful data. Additionally, training-based strategies have been launched to reinforce additional the mannequin’s capacity to deal with irrelevant information. These embody implicit robustness fine-tuning and express relevance fine-tuning, each of which practice the LLM to discern related data higher and filter out deceptive content material.
Retrieval reordering is a comparatively easy however efficient method that addresses the “lost-in-the-middle” phenomenon generally noticed in LLMs, the place the mannequin tends to focus extra on the start and finish of an enter sequence whereas shedding consideration to the center parts. By restructuring the enter in order that extremely related data is positioned on the edges of the sequence, the researchers improved the mannequin’s capacity to generate correct responses. As well as, they explored implicit fine-tuning, which entails coaching the LLM with datasets containing noisy and probably deceptive data. This methodology encourages the mannequin to turn into extra resilient to such noise, making it extra strong in sensible functions. Express relevance fine-tuning goes one step additional by instructing the LLM to actively analyze retrieved paperwork and establish probably the most related passages earlier than producing a solution. This methodology enhances the LLM’s capacity to tell apart between precious and irrelevant data in complicated, multi-document contexts.
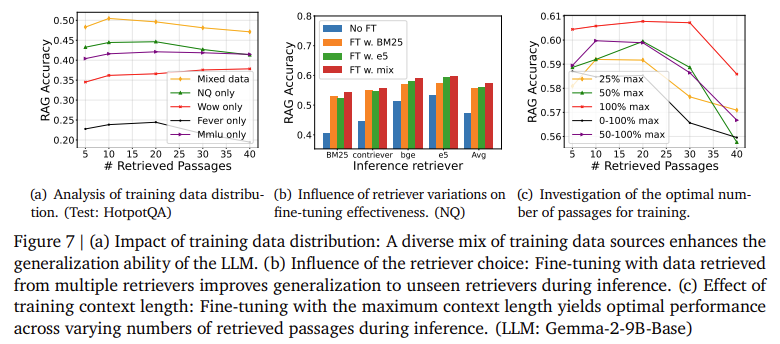
The proposed strategies demonstrated notable enhancements in accuracy and robustness. The analysis confirmed that retrieval reordering improved the LLM’s accuracy by a number of proportion factors, notably when dealing with massive units of retrieved passages. For instance, experiments on the Pure Questions dataset confirmed that rising the variety of retrieved passages initially improved accuracy. Nonetheless, efficiency declined after a sure level when onerous negatives turned too prevalent. The introduction of reordering and fine-tuning mitigated this subject, sustaining larger accuracy even because the variety of passages elevated. Notably, the accuracy with the Gemma-2-9B-Chat mannequin improved by 5% when the reordering approach was utilized to bigger retrieval units, demonstrating the approach’s effectiveness in real-world situations.
Key Takeaways from the Analysis:
- A 5% enchancment in accuracy was achieved by making use of retrieval reordering to massive units of retrieved passages.
- Express relevance fine-tuning permits the mannequin to research and establish probably the most related data, enhancing accuracy in complicated retrieval situations.
- Implicit fine-tuning makes the LLM extra strong in opposition to noisy and deceptive information by coaching it with difficult datasets.
- Retrieval reordering mitigates the “lost-in-the-middle” impact, serving to the LLM deal with a very powerful passages firstly and finish of the enter sequence.
- The strategies launched might be utilized to enhance the efficiency of long-context LLMs throughout numerous datasets, together with Pure Questions and PopQA, the place they have been proven to enhance accuracy constantly.

In conclusion, this analysis provides sensible options to the challenges of long-context LLMs in RAG methods. By introducing modern strategies like retrieval reordering and fine-tuning approaches, the researchers have demonstrated a scalable option to improve the accuracy and robustness of those methods, making them extra dependable for dealing with complicated, real-world information.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Overlook to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving High quality-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



