
Massive language fashions (LLMs) have advanced to turn out to be highly effective instruments able to understanding and responding to consumer directions. Primarily based on the transformer structure, these fashions predict the following phrase or token in a sentence, producing responses with outstanding fluency. Nevertheless, they sometimes reply with out participating in inside thought processes that would assist enhance the accuracy of their solutions, particularly in additional advanced duties. Whereas strategies like Chain-of-Thought (CoT) prompting have been developed to enhance reasoning, these methods have wanted extra success exterior of logical and mathematical duties. Researchers are actually specializing in equipping LLMs to suppose earlier than responding, enhancing their efficiency throughout varied features, together with artistic writing and normal information queries.
One of many predominant challenges with LLMs is their tendency to reply with out contemplating the complexity of the directions. For easy duties, quick responses could also be enough, however these fashions usually fall brief for extra intricate issues requiring logical reasoning or problem-solving. The problem lies in coaching fashions to pause, generate inside ideas, and consider these ideas earlier than delivering a ultimate response. This sort of coaching is historically resource-intensive and requires giant datasets of human-annotated ideas, that are solely generally accessible for some domains. Because of this, the issue researchers face is find out how to create extra clever LLMs that may apply reasoning throughout varied duties with out counting on in depth human-labeled knowledge.
A number of approaches have been developed to deal with this challenge and immediate LLMs to interrupt down advanced issues. Chain-of-thought (CoT) prompting is one such technique the place the mannequin is requested to put in writing out intermediate reasoning steps, permitting it to deal with duties extra structured. Nevertheless, CoT strategies have primarily been profitable in fields similar to arithmetic and logic, the place clear reasoning steps are required. In domains like advertising and marketing or artistic writing, the place solutions are extra subjective, CoT usually fails to offer vital enhancements. This limitation is compounded by the truth that the datasets used to coach LLMs usually include human responses slightly than the interior thought processes behind these responses, making it tough to refine the reasoning talents of the fashions in numerous areas.
Researchers from Meta FAIR, the College of California, Berkeley, and New York College launched a novel coaching technique referred to as Thought Desire Optimization (TPO). TPO goals to equip present LLMs with the power to generate and refine inside ideas earlier than producing a response. In contrast to conventional strategies that depend on human-labeled knowledge, TPO requires no further human annotation, making it an economical answer. The TPO technique begins by instructing the mannequin to divide its output into two distinct elements: the thought course of and the ultimate response. A number of ideas are generated for every consumer instruction, and these thought-response pairs are evaluated by way of choice optimization. One of the best thought-response pairs are chosen for additional coaching iterations, step by step permitting the mannequin to enhance its reasoning capabilities.
On the core of TPO is a reinforcement studying (RL) method that permits the mannequin to study from its thought era. The mannequin is prompted to generate ideas earlier than answering, and a decide mannequin scores the ensuing responses. By iterating on this course of and optimizing the ideas that result in higher-quality responses, the mannequin turns into higher at understanding advanced queries and delivering well-thought-out solutions. This iterative method is essential as a result of it permits the mannequin to refine its reasoning with out requiring direct human intervention, making it a scalable answer for enhancing LLMs throughout varied domains.
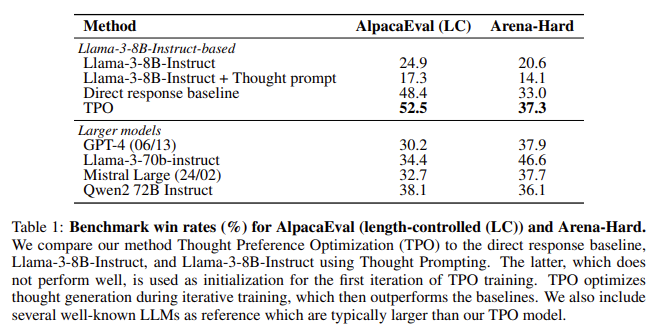
The effectiveness of TPO was examined on two outstanding benchmarks: AlpacaEval and Enviornment-Exhausting. On AlpacaEval, the TPO mannequin achieved a win fee of 52.5%, outperforming the direct response baseline by 4.1%. Equally, it registered a win fee of 37.3% on Enviornment-Exhausting, outperforming conventional strategies by 4.3%. These notable enhancements exhibit that TPO is efficient in logic-based duties and areas sometimes not related to reasoning, similar to advertising and marketing and health-related queries. The researchers noticed that LLMs geared up with TPO confirmed good points even in artistic writing and normal information duties, indicating the broad applicability of the tactic.
Some of the vital findings of the analysis is that thinking-based fashions carried out higher than direct response fashions throughout varied domains. Even in non-reasoning duties like artistic writing, TPO-enabled fashions may plan their responses extra successfully, leading to higher outcomes. The iterative nature of TPO coaching additionally signifies that the mannequin continues to enhance with every iteration, as seen within the rising win charges throughout a number of benchmarks. As an example, after 4 iterations of TPO coaching, the mannequin achieved a 52.5% win fee on AlpacaEval, a 27.6% improve from the preliminary seed mannequin. The Enviornment-Exhausting benchmark noticed comparable traits, with the mannequin matching and finally surpassing the direct baseline after a number of iterations.
Key Takeaways from the Analysis:
- TPO elevated the win fee of LLMs by 52.5% on AlpacaEval and 37.3% on Enviornment-Exhausting.
- The tactic eliminates the necessity for human-labeled knowledge, making it cost-effective and scalable.
- TPO improved non-reasoning duties similar to advertising and marketing, artistic writing, and health-related queries.
- After 4 iterations, TPO fashions achieved a 27.6% enchancment over the preliminary seed mannequin on AlpacaEval.
- The method has broad applicability, extending past conventional reasoning duties to normal instruction following.

In conclusion, Thought Desire Optimization (TPO) permits fashions to suppose earlier than responding. TPO addresses one of many key limitations of conventional LLMs: their lack of ability to deal with advanced duties that require logical reasoning or multi-step problem-solving. The analysis demonstrates that TPO can enhance efficiency throughout varied duties, from logic-based issues to artistic and subjective queries. TPO’s iterative, self-improving nature makes it a promising method for future developments in LLMs, providing broader purposes in fields past conventional reasoning duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Fantastic-Tuned Fashions: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.



