
A Mannequin Inversion (MI) assault is a kind of privateness assault on machine studying and deep studying fashions, the place an attacker tries to invert the mannequin’s outputs to recreate privacy-sensitive coaching knowledge that was used throughout coaching together with the leakage of personal photos in face recognition fashions, delicate well being particulars in medical knowledge, monetary info corresponding to transaction information and account balances, and private preferences and social connections in social media knowledge, and so on. elevating widespread issues about privateness threats of Deep Neural Networks (DNNs). Sadly, as MI assaults have grow to be superior, there hasn’t been a whole and dependable solution to check and examine these assaults, making it troublesome to judge the safety of the mannequin. This deficiency results in insufficient comparisons between completely different assault strategies and inconsistent experimental setups. Moreover, the absence of unified experimental protocols ends in a fragmented panorama the place there may be much less validity and equity within the comparative research.
Till now it was very exhausting to search out any such benchmark that might measure a mannequin’s potential to defend itself towards such threats. Though to defend towards MI assaults, most present strategies may be categorized into two sorts: mannequin output processing and strong mannequin coaching. Mannequin output processing refers to decreasing the personal info carried within the sufferer mannequin’s output to advertise privateness. Yang et al. suggest to coach an autoencoder to purify the output vector by reducing its diploma of dispersion. Wen et al. apply adversarial noises to the mannequin output and confuse the attackers. Ye et al. leverage a differential privateness mechanism to divide the output vector into a number of sub-ranges. Strong mannequin coaching refers to incorporating protection methods in the course of the coaching course of. MID Wang et al. penalizes the mutual info between mannequin inputs and outputs within the coaching loss, thus decreasing the redundant info carried within the mannequin output that could be abused by the attackers.
Current MI assaults and defenses lack a complete, aligned, and dependable benchmark, leading to insufficient comparisons and inconsistent experimental setups. Thus researchers launched a benchmark to measure the potential and decide the vulnerability of the mannequin towards such Mannequin Inversion assaults.
To alleviate these issues, researchers from the UniHarbin Institute of Expertise (Shenzhen) and Tsinghua College launched the primary benchmark within the MI area, named MIBench. For constructing an extensible modular-based toolbox, they disassemble the pipeline of MI assaults and defenses into 4 fundamental modules, every designated for knowledge preprocessing, assault strategies, protection methods, and analysis, enhancing this merged framework’s extensibility. The proposed MIBench has encompassed a complete of 16 strategies comprising 11 assault strategies and 4 protection methods, coupled with 9 prevalent analysis protocols to adequately measure the excellent efficiency of particular person MI strategies and with a give attention to Generative Adversarial Community (GAN)-based MI assaults. Primarily based on the accessibility to the goal mannequin’s parameters, researchers categorized MI assaults into white-box and black-box assaults. White-box assaults can entail full information of the goal mannequin, enabling the computation of gradients for performing backpropagation, whereas black-box assaults are constrained to merely acquiring the prediction confidence vectors of the goal mannequin. The MIBench benchmark contains 8 white-box assault strategies and 4 black-box assault strategies.
Overview of the fundamental construction of modular-based toolbox for MIB benchmark
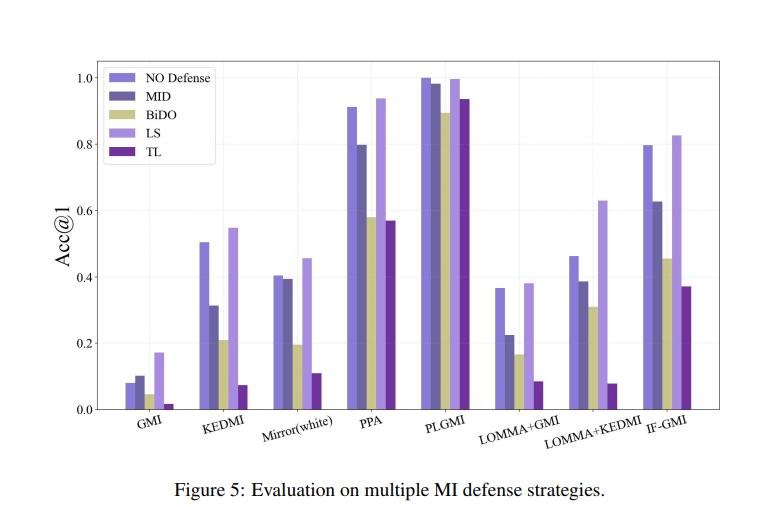
The researchers examined MI assault methods on two fashions (IR-152 for low and ResNet-152 for top decision) utilizing private and non-private datasets. Parameters like Accuracy, Function Distance, and FID had been used to match white-box and black-box assaults to validate the tactic. Robust strategies like PLGMI and LOKT confirmed excessive accuracy, whereas PPA and C2FMI produced extra reasonable photos, particularly in greater decision. It was noticed by the researchers that the effectiveness of MI assaults elevated with the mannequin’s predictive energy. Present protection methods weren’t totally efficient, highlighting the necessity for higher strategies to guard privateness with out decreasing mannequin accuracy.

In conclusion, the reproducible benchmark will facilitate the additional improvement of the MI area and produce extra revolutionary explorations within the subsequent research. Sooner or later, MIBench might present a unified, sensible and extensible toolbox and is broadly utilized by researchers within the area to scrupulously check and examine their novel strategies, guaranteeing equitable evaluations and thereby propelling additional developments in future improvement.
Nonetheless, a attainable destructive influence of the MIB benchmark is that dangerous customers might use the assault strategies to recreate personal knowledge from public programs. To handle this, knowledge customers want to use robust and dependable protection methods and strategies. Moreover, organising entry controls and limiting how usually every person can entry the information is vital for constructing accountable AI programs, and decreasing potential conflicts with folks’s personal knowledge.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving High quality-Tuned Fashions: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and remedy challenges.


