
Massive vision-language fashions have emerged as highly effective instruments for multimodal understanding, demonstrating spectacular capabilities in deciphering and producing content material that mixes visible and textual data. These fashions, equivalent to LLaVA and its variants, fine-tune giant language fashions (LLMs) on visible instruction information to carry out advanced imaginative and prescient duties. Nevertheless, growing high-quality visible instruction datasets presents vital challenges. These datasets require numerous photos and texts from numerous duties to generate numerous questions, protecting areas like object detection, visible reasoning, and picture captioning. The standard and variety of those datasets instantly influence the mannequin’s efficiency, as evidenced by LLaVA’s substantial enhancements over earlier state-of-the-art strategies on duties like GQA and VizWiz. Regardless of these developments, present fashions face limitations as a result of modality hole between pre-trained imaginative and prescient encoders and language fashions, which restricts their generalization skill and have illustration.
Researchers have made vital strides in addressing the challenges of vision-language fashions via numerous approaches. Instruction tuning has emerged as a key methodology, enabling LLMs to interpret and execute human language directions throughout numerous duties. This strategy has advanced from closed-domain instruction tuning, which makes use of publicly obtainable datasets, to open-domain instruction tuning, which makes use of real-world question-answer datasets to boost mannequin efficiency in genuine person situations.
In vision-language integration, strategies like LLaVA have pioneered the mix of LLMs with CLIP imaginative and prescient encoders, demonstrating exceptional capabilities in image-text dialogue duties. Subsequent analysis has targeted on refining visible instruction tuning by enhancing dataset high quality and selection throughout pre-training and fine-tuning phases. Fashions equivalent to LLaVA-v1.5 and ShareGPT4V have achieved notable success typically vision-language comprehension, showcasing their skill to deal with advanced question-answering duties.
These developments spotlight the significance of refined information dealing with and model-tuning methods in growing efficient vision-language fashions. Nevertheless, challenges stay in bridging the modality hole between imaginative and prescient and language domains, necessitating continued innovation in mannequin structure and coaching methodologies.
Researchers from Rochester Institute of Expertise and Salesforce AI Analysis suggest a singular framework, SQ-LLaVA based mostly on a visible self-questioning strategy, carried out in a mannequin named SQ-LLaVA (Self-Questioning LLaVA). This technique goals to boost vision-language understanding by coaching the LLM to ask questions and uncover visible clues with out requiring extra exterior information. Not like current visible instruction tuning strategies that focus totally on reply prediction, SQ-LLaVA extracts related query context from photos.
The strategy is predicated on the statement that questions typically include extra image-related data than solutions, as evidenced by greater CLIPScores for image-question pairs in comparison with image-answer pairs in current datasets. By using this perception, SQ-LLaVA makes use of questions inside instruction information as an extra studying useful resource, successfully enhancing the mannequin’s curiosity and questioning skill.
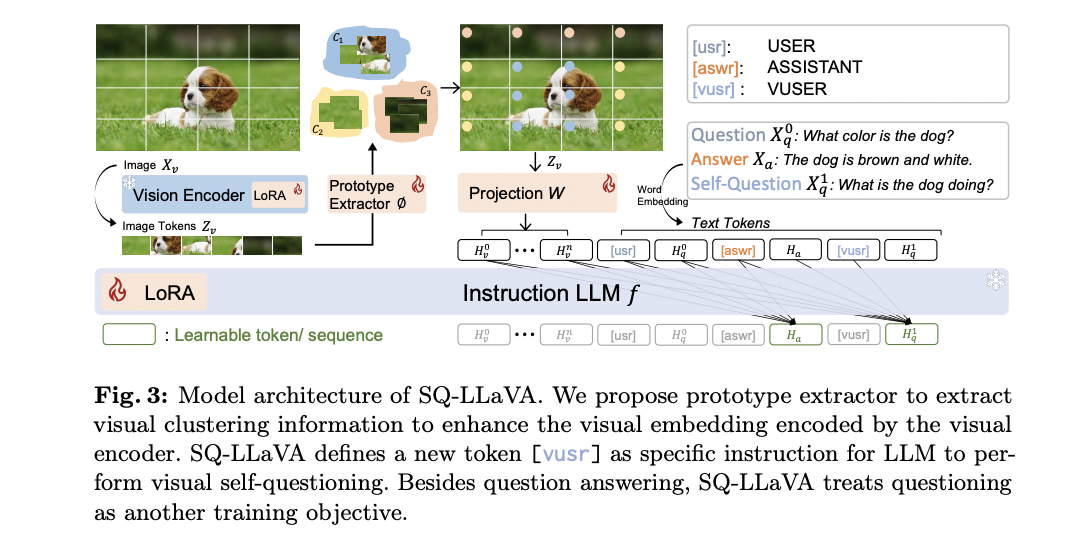
To effectively align imaginative and prescient and language domains, SQ-LLaVA employs Low-Rank Diversifications (LoRAs) to optimize each the imaginative and prescient encoder and the educational LLM. Additionally, a prototype extractor is developed to boost visible illustration by using realized clusters with significant semantic data. This complete strategy goals to enhance vision-language alignment and general efficiency in numerous visible understanding duties with out the necessity for brand new information assortment or in depth computational assets.
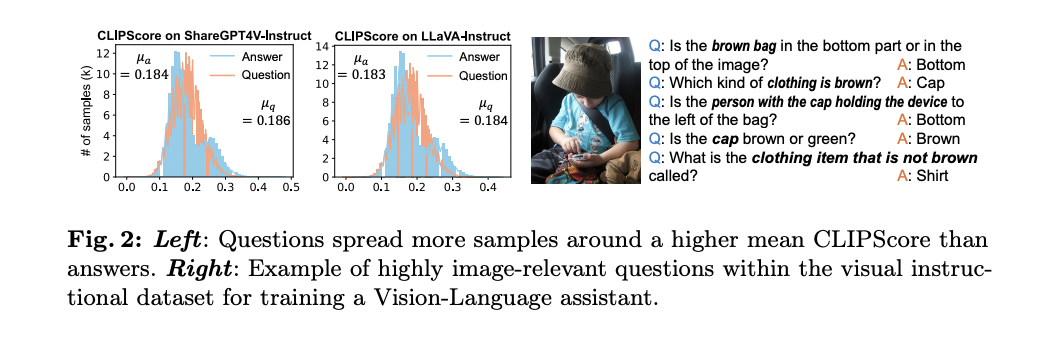
The SQ-LLaVA mannequin structure includes 4 predominant parts designed to boost vision-language understanding. At its core is a pre-trained CLIP-ViT imaginative and prescient encoder that extracts sequence embeddings from enter photos. That is complemented by a strong prototype extractor that learns visible clusters to complement the unique picture tokens, enhancing the mannequin’s skill to acknowledge and group related visible patterns.
A trainable projection block, consisting of two linear layers, maps the improved picture tokens to the language area, addressing the dimension mismatch between visible and linguistic representations. The spine of the mannequin is a pre-trained Vicuna LLM, which predicts subsequent tokens based mostly on the earlier embedding sequence.
The mannequin introduces a visible self-questioning strategy, using a singular [vusr] token to instruct the LLM to generate questions concerning the picture. This course of is designed to make the most of the wealthy semantic data typically current in questions, doubtlessly surpassing that of solutions. The structure additionally contains an enhanced visible illustration part that includes a prototype extractor that makes use of clustering strategies to seize consultant semantics within the latent house. This extractor iteratively updates cluster assignments and facilities, adaptively mapping visible cluster data to the uncooked picture embeddings.
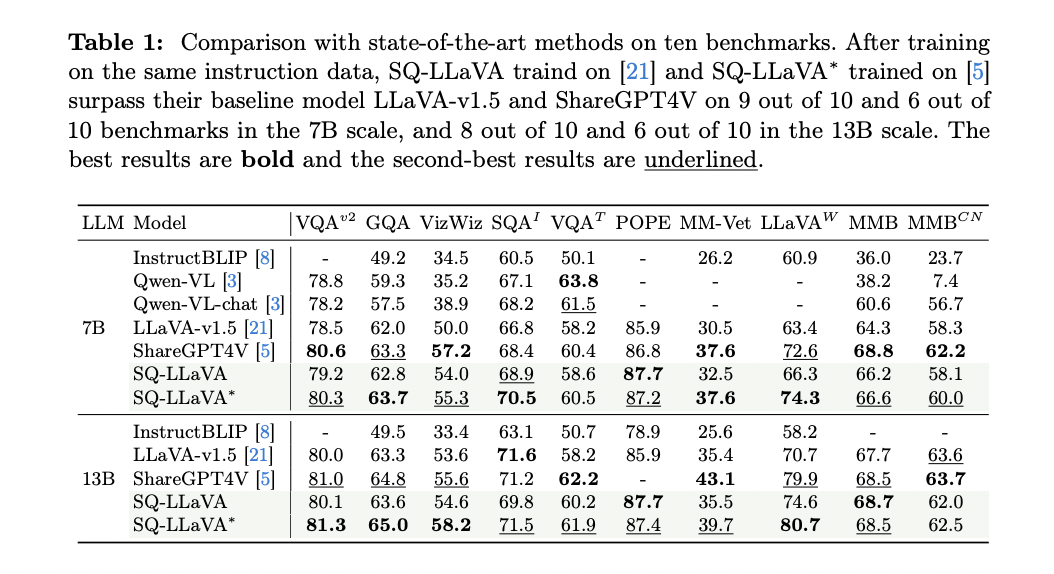
The researchers evaluated SQ-LLaVA on a complete set of ten visible question-answering benchmarks, protecting a variety of duties from tutorial VQA to instruction tuning duties designed for big vision-language fashions. The mannequin demonstrated vital enhancements over current strategies in a number of key areas:
1. Efficiency: SQ-LLaVA-7B and SQ-LLaVA-13B outperformed earlier strategies in six out of ten visible instruction tuning duties. Notably, SQ-LLaVA-7B achieved a 17.2% enchancment over LLaVA-v1.5-7B on the LLaVA (within the wild) benchmark, indicating superior capabilities in detailed description and complicated reasoning.
2. Scientific reasoning: The mannequin confirmed improved efficiency on ScienceQA, suggesting robust capabilities in multi-hop reasoning and comprehension of advanced scientific ideas.
3. Reliability: SQ-LLaVA-7B demonstrated a 2% and 1% enchancment over LLaVA-v1.5-7B and ShareGPT4V-7B on the POPE benchmark, indicating higher reliability and diminished object hallucination.
4. Scalability: SQ-LLaVA-13B surpassed earlier works in six out of ten benchmarks, demonstrating the strategy’s effectiveness with bigger language fashions.
5. Visible data discovery: The mannequin confirmed superior capabilities in detailed picture description, visible data abstract, and visible self-questioning. It generated numerous and significant questions on given photos with out requiring human textual directions.
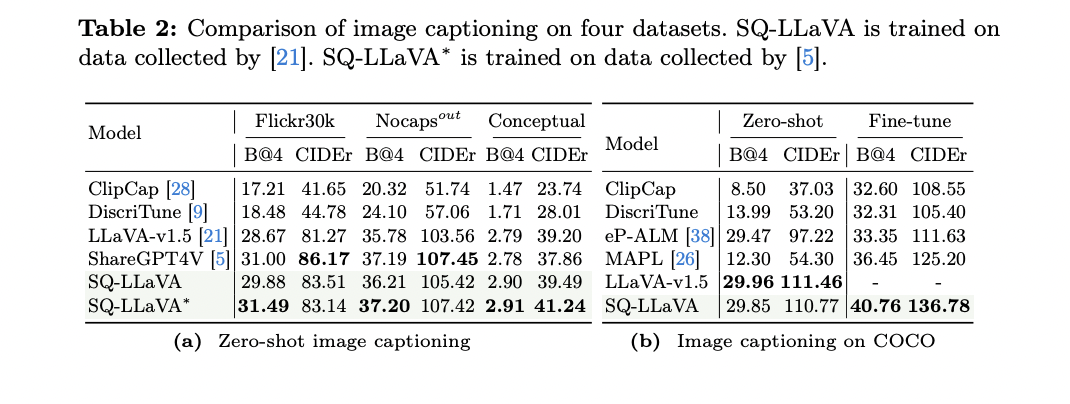
6. Zero-shot picture captioning: SQ-LLaVA achieved vital enhancements over baseline fashions like ClipCap and DiscriTune, with a 73% and 66% common enchancment throughout all datasets.
These outcomes have been achieved with considerably fewer trainable parameters in comparison with different strategies, highlighting the effectivity of the SQ-LLaVA strategy. The mannequin’s skill to generate numerous questions and supply detailed picture descriptions demonstrates its potential as a strong software for visible data discovery and understanding.


SQ-LLaVA introduces a singular visible instruction tuning technique that enhances vision-language understanding via self-questioning. The strategy achieves superior efficiency with fewer parameters and fewer information throughout numerous benchmarks. It demonstrates improved generalization to unseen duties, reduces object hallucination, and enhances semantic picture interpretation. By framing questioning as an intrinsic purpose, SQ-LLaVA explores mannequin curiosity and proactive question-asking talents. This analysis highlights the potential of visible self-questioning as a strong coaching technique, paving the best way for extra environment friendly and efficient giant vision-language fashions able to tackling advanced issues throughout numerous domains.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Knowledge Retrieval Convention (Promoted)
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


