
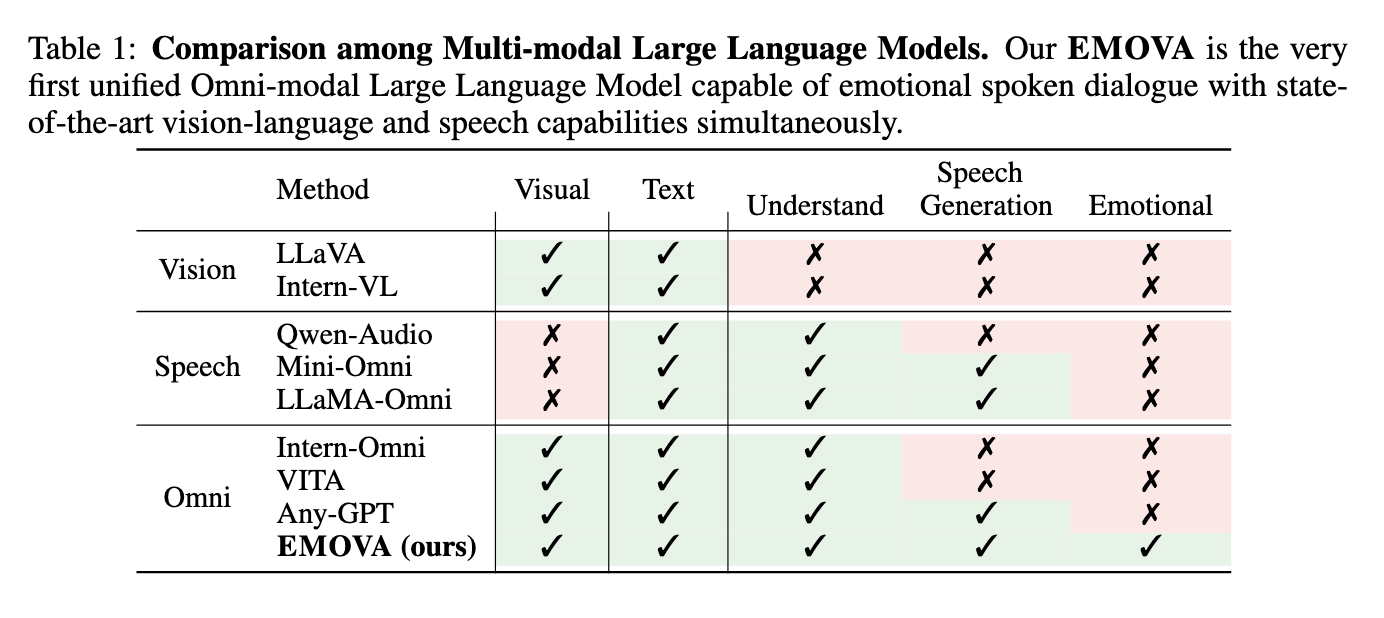
Omni-modal giant language fashions (LLMs) are on the forefront of synthetic intelligence analysis, looking for to unify a number of knowledge modalities resembling imaginative and prescient, language, and speech. The first objective is to reinforce the interactive capabilities of those fashions, permitting them to understand, perceive, and generate outputs throughout numerous inputs, simply as a human would. These developments are vital for creating extra complete AI techniques to interact in pure interactions, reply to visible cues, interpret vocal directions, and supply coherent responses in textual content and speech codecs. Such a feat entails designing fashions to handle high-level cognitive duties whereas integrating sensory and textual data.
Regardless of progress in particular person modalities, present AI fashions need assistance integrating imaginative and prescient and speech skills right into a unified framework. Present fashions are both vision-language or speech-language-focused, usually failing to attain a seamless end-to-end understanding of all three modalities concurrently. This limitation hinders their utility in eventualities that demand real-time interactions, resembling digital assistants or autonomous robots. Additional, present speech fashions rely closely on exterior instruments for producing vocal outputs, which introduces latency and restricts flexibility in speech model management. The problem stays in designing a mannequin that may overcome these limitations whereas sustaining excessive efficiency in understanding and producing multimodal content material.
A number of approaches have been adopted to enhance multimodal fashions. Imaginative and prescient-language fashions like LLaVA and Intern-VL make use of imaginative and prescient encoders to extract and combine visible options with textual knowledge. Speech-language fashions, resembling Whisper, make the most of speech encoders to extract steady options, permitting the mannequin to understand vocal inputs. Nevertheless, these fashions are constrained by their reliance on exterior Textual content-to-Speech (TTS) instruments for producing speech responses. This method limits the mannequin’s capability to generate speech in real-time and with an emotional variation. Furthermore, makes an attempt at omni-modal fashions, like AnyGPT, depend on discretizing knowledge, which frequently leads to data loss, particularly in visible modalities, decreasing the mannequin’s effectiveness on high-resolution visible duties.
Researchers from Hong Kong College of Science and Know-how, The College of Hong Kong, Huawei Noah’s Ark Lab, The Chinese language College of Hong Kong, Solar Yat-sen College and Southern College of Science and Know-how have launched EMOVA (Emotionally Omni-present Voice Assistant). This mannequin represents a major development in LLM analysis by seamlessly integrating imaginative and prescient, language, and speech capabilities. EMOVA’s distinctive structure incorporates a steady imaginative and prescient encoder and a speech-to-unit tokenizer, enabling the mannequin to carry out end-to-end processing of speech and visible inputs. By using a semantic-acoustic disentangled speech tokenizer, EMOVA decouples the semantic content material (what’s being mentioned) from the acoustic model (how it’s mentioned), permitting it to generate speech with varied emotional tones. This function is essential for real-time spoken dialogue techniques, the place the power to specific feelings via speech provides depth to interactions.
The EMOVA mannequin contains a number of elements designed to deal with particular modalities successfully. The imaginative and prescient encoder captures high-resolution visible options, projecting them into the textual content embedding area, whereas the speech encoder transforms speech into discrete items that the LLM can course of. A vital side of the mannequin is the semantic-acoustic disentanglement mechanism, which separates the which means of the spoken content material from its model attributes, resembling pitch or emotional tone. This enables the researchers to introduce a light-weight model module for controlling speech outputs, making EMOVA able to expressing numerous feelings and customized speech kinds. Moreover, integrating the textual content modality as a bridge for aligning picture and speech knowledge eliminates the necessity for specialised omni-modal datasets, which are sometimes tough to acquire.
The efficiency of EMOVA has been evaluated on a number of benchmarks, demonstrating its superior capabilities compared to present fashions. On speech-language duties, EMOVA achieved a exceptional 97% accuracy, outperforming different state-of-the-art fashions like AnyGPT and Mini-Omni by a margin of two.8%. In vision-language duties, EMOVA scored 96% on the MathVision dataset, surpassing competing fashions like Intern-VL and LLaVA by 3.5%. Furthermore, the mannequin’s capability to keep up excessive accuracy in each speech and imaginative and prescient duties concurrently is unprecedented, as most present fashions sometimes excel in a single modality on the expense of the opposite. This complete efficiency makes EMOVA the primary LLM able to supporting emotionally wealthy, real-time spoken dialogues whereas attaining state-of-the-art outcomes throughout a number of domains.
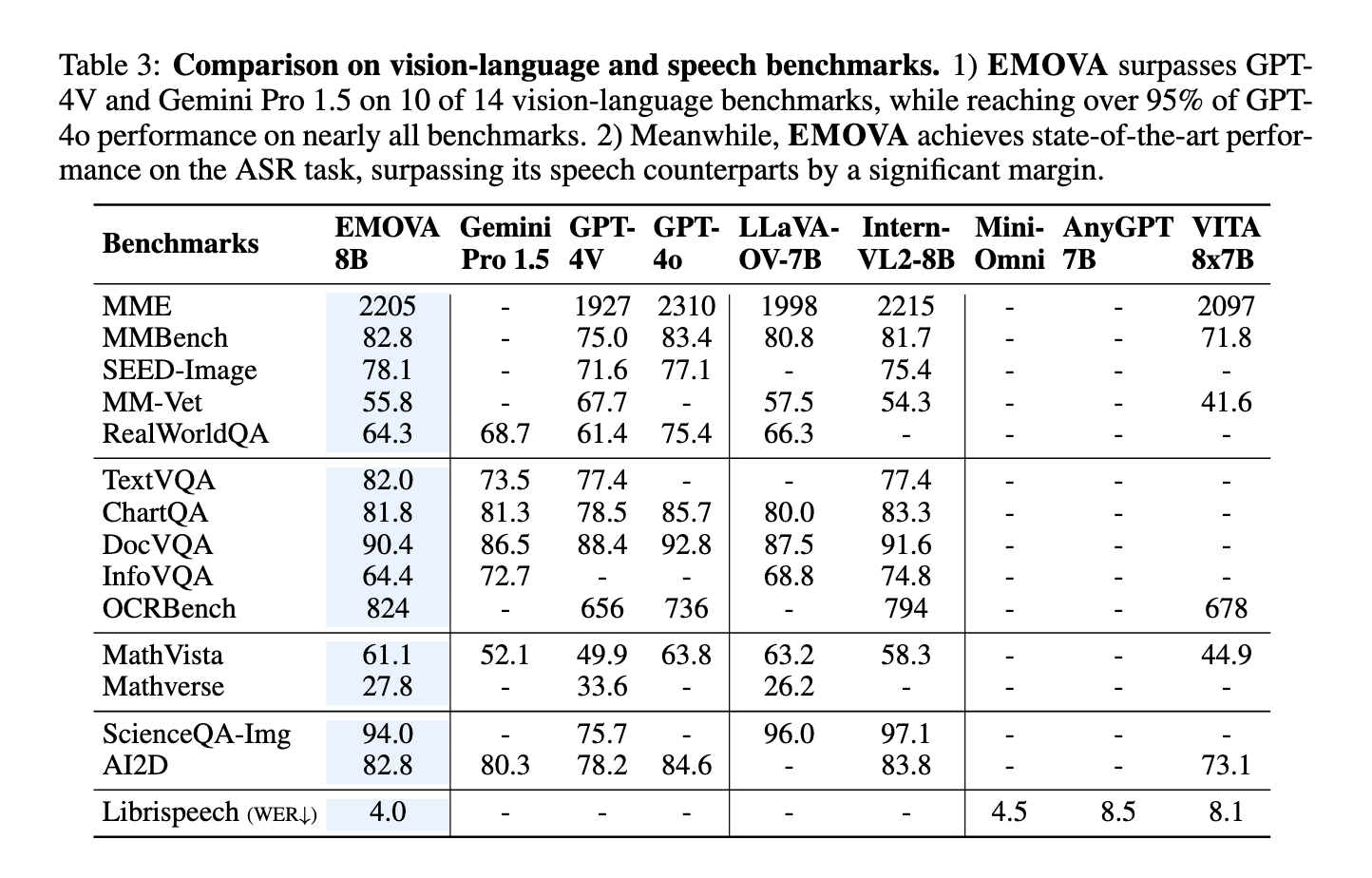
In abstract, EMOVA addresses a vital hole within the integration of imaginative and prescient, language, and speech capabilities inside a single AI mannequin. By means of its progressive semantic-acoustic disentanglement and environment friendly omni-modal alignment technique, it not solely performs exceptionally nicely on commonplace benchmarks but additionally introduces flexibility in emotional speech management, making it a flexible instrument for superior AI interactions. This breakthrough paves the best way for additional analysis and growth in omni-modal giant language fashions, setting a brand new commonplace for future developments within the area.
Take a look at the Paper and Mission. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit
Excited about selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


