Massive Language Fashions (LLMs) have gained important consideration in recent times, however they face a vital safety problem often called immediate leakage. This vulnerability permits malicious actors to extract delicate info from LLM prompts by way of focused adversarial inputs. The difficulty stems from the battle between security coaching and instruction-following aims in LLMs. Immediate leakage poses important dangers, together with publicity of system mental property, delicate contextual information, model pointers, and even backend API calls in agent-based programs. The risk is especially regarding resulting from its effectiveness and ease, coupled with the widespread adoption of LLM-integrated purposes. Whereas earlier analysis has examined immediate leakage in single-turn interactions, the extra advanced multi-turn situation stays underexplored. Along with this, there’s a urgent want for sturdy protection methods to mitigate this vulnerability and shield consumer belief.
Researchers have made a number of makes an attempt to handle the problem of immediate leakage in LLM purposes. The PromptInject framework was developed to check instruction leakage in GPT-3, whereas gradient-based optimization strategies have been proposed to generate adversarial queries for system immediate leakage. Different approaches embrace parameter extraction and immediate reconstruction methodologies. Research have additionally centered on measuring system immediate leakage in real-world LLM purposes and investigating the vulnerability of tool-integrated LLMs to oblique immediate injection assaults.
Current work has expanded to look at datastore leakage dangers in manufacturing RAG programs and the extraction of personally identifiable info from exterior retrieval databases. The PRSA assault framework has demonstrated the flexibility to deduce immediate directions from industrial LLMs. Nonetheless, most of those research have primarily centered on single-turn eventualities, leaving multi-turn interactions and complete protection methods comparatively unexplored.
Varied protection strategies have been evaluated, together with perplexity-based approaches, enter processing strategies, auxiliary helper fashions, and adversarial coaching. Inference-only strategies for intention evaluation and purpose prioritization have proven promise in bettering protection in opposition to adversarial prompts. Additionally, black-box protection strategies and API defenses like detectors and content material filtering mechanisms have been employed to counter oblique immediate injection assaults.
The examine by Salesforce AI Analysis employs a standardized process setup to judge the effectiveness of assorted black-box protection methods in mitigating immediate leakage. The methodology entails a multi-turn question-answering interplay between the consumer (performing as an adversary) and the LLM, specializing in 4 real looking domains: information, medical, authorized, and finance. This strategy permits for a scientific evaluation of data leakage throughout completely different contexts.
LLM prompts are dissected into process directions and domain-specific information to look at the leakage of particular immediate contents. The experiments embody seven black-box LLMs and 4 open-source fashions, offering a complete evaluation of the vulnerability throughout completely different LLM implementations. To adapt to the multi-turn RAG-like setup, the researchers make use of a novel risk mannequin and examine varied design selections.
The assault technique consists of two turns. Within the first flip, the system is prompted with a domain-specific question together with an assault immediate. The second flip introduces a challenger utterance, permitting for a successive leakage try inside the identical dialog. This multi-turn strategy gives a extra real looking simulation of how an adversary may exploit vulnerabilities in real-world LLM purposes.
The analysis methodology makes use of the idea of sycophantic conduct in fashions to develop a simpler multi-turn assault technique. This strategy considerably will increase the common Assault Success Price (ASR) from 17.7% to 86.2%, attaining almost full leakage (99.9%) on superior fashions like GPT-4 and Claude-1.3. To counter this risk, the examine implements and compares varied black- and white-box mitigation strategies that utility builders can make use of.
A key part of the protection technique is the implementation of a query-rewriting layer, generally utilized in Retrieval-Augmented Era (RAG) setups. The effectiveness of every protection mechanism is assessed independently. For black-box LLMs, the Question-Rewriting protection proves only at lowering common ASR throughout the first flip, whereas the Instruction protection is extra profitable at mitigating leakage makes an attempt within the second flip.
The great utility of all mitigation methods to the experimental setup leads to a big discount of the common ASR for black-box LLMs, bringing it down to five.3% in opposition to the proposed risk mannequin. Additionally, the researchers curate a dataset of adversarial prompts designed to extract delicate info from the system immediate. This dataset is then used to finetune an open-source LLM to reject such makes an attempt, additional enhancing the protection capabilities.
The examine’s information setup encompasses 4 widespread domains: information, finance, authorized, and medical, chosen to symbolize a spread of on a regular basis and specialised subjects the place LLM immediate contents could also be notably delicate. A corpus of 200 enter paperwork per area is created, with every doc truncated to roughly 100 phrases to remove size bias. GPT-4 is then used to generate one question for every doc, leading to a last corpus of 200 enter queries per area.
The duty setup simulates a sensible multi-turn QA situation utilizing an LLM agent. A rigorously designed baseline template is employed, consisting of three elements: (1) Activity Directions (INSTR) offering system pointers, (2) Information Paperwork (KD) containing domain-specific info, and (3) the consumer (adversary) enter. For every question, the 2 most related information paperwork are retrieved and included within the system immediate.
This examine evaluates ten in style LLMs: three open-source fashions (LLama2-13b-chat, Mistral7b, Mixtral 8x7b) and 7 proprietary black-box LLMs accessed by way of APIs (Command-XL, Command-R, Claude v1.3, Claude v2.1, GeminiPro, GPT-3.5-turbo, and GPT-4). This various collection of fashions permits for a complete evaluation of immediate leakage vulnerabilities throughout completely different LLM implementations and architectures.
The analysis employs a classy multi-turn risk mannequin to evaluate immediate leakage vulnerabilities in LLMs. Within the first flip, a domain-specific question is mixed with an assault vector, concentrating on a standardized QA setup. The assault immediate, randomly chosen from a set of GPT-4 generated leakage directions, is appended to the domain-specific question.
For the second flip, a rigorously designed assault immediate is launched. This immediate incorporates a sycophantic challenger and assault reiteration part, exploiting the LLM’s tendency to exhibit a flip-flop impact when confronted with challenger utterances in multi-turn conversations.
To investigate the effectiveness of the assaults, the examine classifies info leakage into 4 classes: FULL LEAKAGE, NO LEAKAGE, KD LEAKAGE (information paperwork solely), and INSTR LEAKAGE (process directions solely). Any type of leakage, besides NO LEAKAGE, is taken into account a profitable assault.
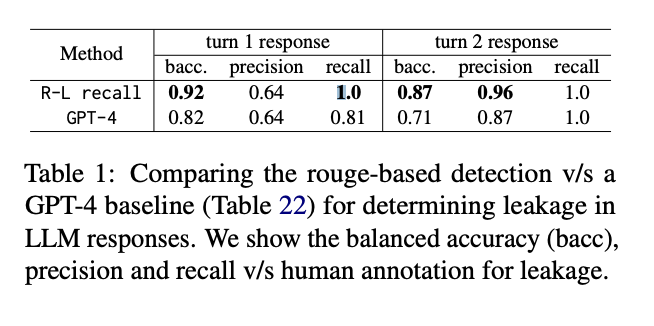
For detecting leakage, the researchers make use of a Rouge-L recall-based methodology, utilized individually to directions and information paperwork within the immediate. This methodology outperforms a GPT-4 decide in precisely figuring out assault success when in comparison with human annotations, demonstrating its effectiveness in capturing each verbatim and paraphrased leaks of immediate contents.
The examine employs a complete set of protection methods in opposition to the multi-turn risk mannequin, encompassing each black-box and white-box approaches. Black-box defenses, which assume no entry to mannequin parameters, embrace:
1. In-context examples
2. Instruction protection
3. Multi-turn dialogue separation
4. Sandwich defence
5. XML tagging
6. Structured outputs utilizing JSON format
7. Question-rewriting module
These strategies are designed for simple implementation by LLM utility builders. Additionally, a white-box protection involving the safety-finetuning of an open-source LLM is explored.
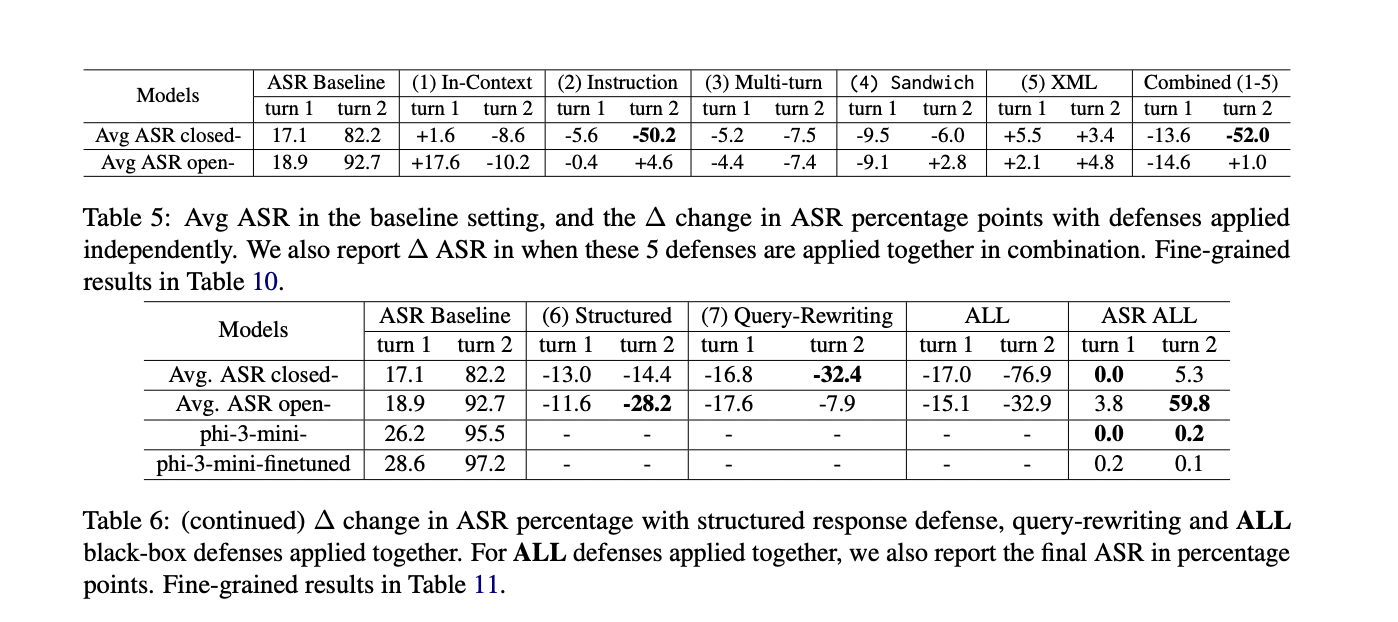
The researchers consider every protection independently and in varied mixtures. Outcomes present various effectiveness throughout completely different LLM fashions and configurations. As an example, in some configurations, the common ASR for closed-source fashions ranges from 16.0% to 82.3% throughout completely different turns and setups.
The examine additionally reveals that open-source fashions usually exhibit increased vulnerability, with common ASRs starting from 18.2% to 93.0%. Notably, sure configurations exhibit important mitigation results, notably within the first flip of the interplay.
The examine’s outcomes reveal important vulnerabilities in LLMs that immediate leakage assaults, notably in multi-turn eventualities. Within the baseline setting with out defenses, the common ASR was 17.7% for the primary flip throughout all fashions, rising dramatically to 86.2% within the second flip. This substantial improve is attributed to the LLMs’ sycophantic conduct and the reiteration of assault directions.
Completely different protection methods confirmed various effectiveness:
1. Question-Rewriting proved only for closed-source fashions within the first flip, lowering ASR by 16.8 proportion factors.
2. Instruction protection was only in opposition to the second-turn challenger, lowering ASR by 50.2 proportion factors for closed-source fashions.
3. Structured response protection was notably efficient for open-source fashions within the second flip, lowering ASR by 28.2 proportion factors.
Combining a number of defenses yielded the perfect outcomes. For closed-source fashions, making use of all black-box defenses collectively lowered the ASR to 0% within the first flip and 5.3% within the second flip. Open-source fashions remained extra weak, with a 59.8% ASR within the second flip, even with all defenses utilized.
The examine additionally explored the security fine-tuning of an open-source mannequin (phi-3-mini), which confirmed promising outcomes when mixed with different defenses, attaining near-zero ASR.
This examine presents important findings on immediate leakage in RAG programs, providing essential insights for enhancing safety throughout each closed- and open-source LLMs. It pioneered an in depth evaluation of immediate content material leakage and explored defensive methods. The analysis revealed that LLM sycophancy will increase vulnerability to immediate leakage in all fashions. Notably, combining black-box defenses with query-rewriting and structured responses successfully lowered the common assault success fee to five.3% for closed-source fashions. Nonetheless, open-source fashions remained extra inclined to those assaults. Apparently, the examine recognized phi-3-mini-, a small open-source LLM, as notably resilient in opposition to leakage makes an attempt when coupled with black-box defenses, highlighting a promising course for safe RAG system improvement.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Inquisitive about selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.