
Producing versatile and high-quality textual content embeddings throughout numerous duties is a big problem in pure language processing (NLP). Present embedding fashions, regardless of developments, typically wrestle to deal with unseen duties and complicated retrieval operations successfully. These limitations hinder their potential to adapt dynamically to various contexts, a important requirement for real-world functions. Addressing this problem is crucial for advancing the sector of AI, enabling the event of extra sturdy and adaptable methods able to performing effectively throughout a variety of eventualities.
Present strategies for textual content embedding rely closely on refined modifications to giant language mannequin (LLM) architectures, resembling bidirectional consideration mechanisms and numerous pooling methods. Whereas these approaches have led to efficiency enhancements in particular eventualities, they typically include vital drawbacks. These embody elevated computational complexity and a scarcity of flexibility when adapting to new duties. Furthermore, many of those fashions require intensive pre-training on giant datasets, which will be each resource-intensive and time-consuming. Regardless of these efforts, fashions like NV-Embed and GritLM nonetheless fall quick of their potential to generalize successfully throughout totally different duties, notably once they encounter eventualities that weren’t a part of their coaching information.
The researchers from Beijing Academy of Synthetic Intelligence, Beijing College of Posts and Telecommunications, Chinese language Academy of Sciences and College of Science, and Know-how of China introduce a novel mannequin, bge-en-icl, which reinforces the technology of textual content embeddings by leveraging the in-context studying (ICL) capabilities of LLMs. This method addresses the constraints of present fashions by integrating task-specific examples immediately into the question enter, enabling the mannequin to generate embeddings which might be extra related and generalizable throughout numerous duties. The innovation lies in sustaining the simplicity of the unique LLM structure whereas incorporating ICL options, avoiding the necessity for intensive architectural modifications or extra pre-training. This methodology proves extremely efficient, setting new efficiency benchmarks throughout various duties with out sacrificing the mannequin’s potential to adapt to new contexts.
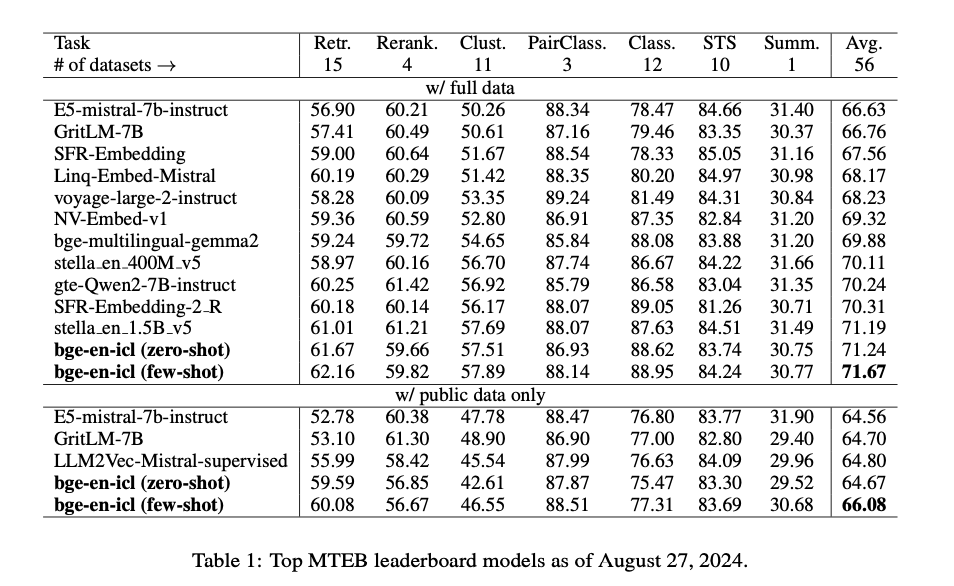
The bge-en-icl mannequin is predicated on the Mistral-7B spine, recognized for its effectiveness in NLP duties. A key facet of this methodology is using in-context studying throughout coaching, the place task-specific examples are built-in into the question enter. This enables the mannequin to study embeddings which might be each task-specific and generalizable. The mannequin is fine-tuned utilizing a contrastive loss perform, designed to maximise the similarity between related query-passage pairs whereas minimizing it for irrelevant ones. The coaching course of includes a various set of duties, resembling retrieval, reranking, and classification, guaranteeing broad applicability. The bge-en-icl mannequin is examined on benchmarks like MTEB and AIR-Bench, persistently outperforming different fashions, notably in few-shot studying eventualities.
The bge-en-icl mannequin demonstrates vital developments in textual content embedding technology, reaching state-of-the-art efficiency throughout numerous duties on the MTEB and AIR-Bench benchmarks. Notably, the mannequin excels in few-shot studying eventualities, outperforming a number of main fashions in retrieval, classification, and clustering duties. As an example, it achieves excessive scores in each retrieval and classification, highlighting its functionality to generate related and generalizable embeddings. These outcomes underscore the effectiveness of incorporating in-context studying (ICL) into the embedding course of, permitting the mannequin to adapt dynamically to various duties whereas sustaining simplicity in its architectural design. This progressive method not solely improves efficiency but in addition broadens the applicability of textual content embeddings in real-world eventualities.
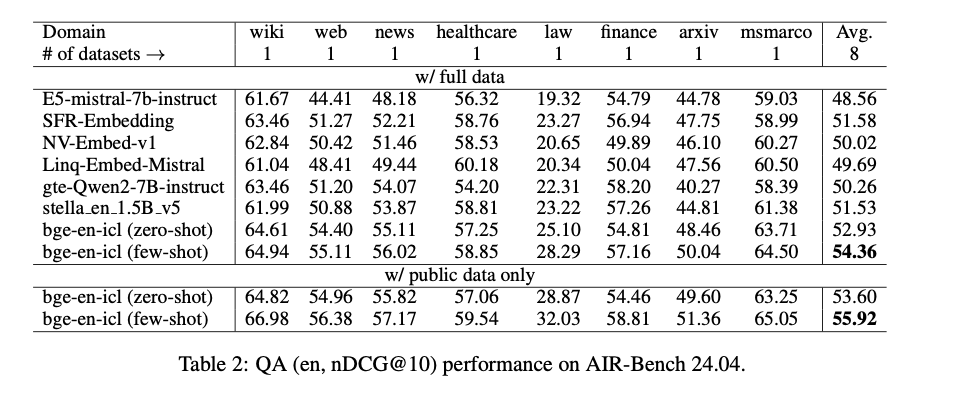
In conclusion, the researchers have made a considerable contribution to the sector of textual content embedding by growing the bge-en-icl mannequin, which successfully leverages in-context studying to enhance the adaptability and efficiency of LLMs. By integrating task-specific examples immediately into the question enter, this methodology overcomes the constraints of present fashions, enabling the technology of high-quality embeddings throughout a variety of duties. The bge-en-icl mannequin units new benchmarks on MTEB and AIR-Bench, demonstrating that simplicity mixed with ICL can result in extremely efficient and versatile AI methods. This method has the potential to considerably influence AI analysis, providing a path ahead for creating extra adaptable and environment friendly fashions for real-world functions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


