
The sphere of data retrieval has quickly developed as a result of exponential development of digital knowledge. With the growing quantity of unstructured knowledge, environment friendly strategies for looking out and retrieving related data have develop into extra essential than ever. Conventional keyword-based search strategies usually must seize the nuanced which means of textual content, resulting in inaccurate or irrelevant search outcomes. This problem turns into extra pronounced with complicated datasets that span numerous media sorts, similar to textual content, pictures, and movies. The widespread adoption of good gadgets and social platforms has additional contributed to this surge in knowledge, with estimates suggesting that unstructured knowledge may represent 80% of the full knowledge quantity by 2025. As such, there’s a important want for strong methodologies that may remodel this knowledge into significant insights.
One of many primary challenges in data retrieval is coping with the excessive dimensionality and dynamic nature of recent datasets. Current strategies usually need assistance to supply scalable and environment friendly options for dealing with multi-vector queries or integrating real-time updates. That is significantly problematic for functions requiring fast retrieval of contextually related outcomes, similar to recommender techniques and large-scale serps. Whereas some progress has been made in enhancing retrieval mechanisms by means of latent semantic evaluation (LSA) and deep studying fashions, these strategies nonetheless want to deal with the semantic gaps between queries and paperwork.
Present data retrieval techniques, like Milvus, have tried to supply help for large-scale vector knowledge administration. Nonetheless, these techniques are hindered by their reliance on static datasets and an absence of flexibility in dealing with complicated multi-vector queries. Conventional algorithms and libraries usually rely closely on primary reminiscence storage and can’t distribute knowledge throughout a number of machines, limiting their scalability. This restricts their adaptability to real-world situations the place knowledge is continually altering. Consequently, present options wrestle to supply the precision and effectivity required for dynamic environments.
The analysis crew on the College of Washington launched VectorSearch, a novel doc retrieval framework designed to deal with these limitations. VectorSearch integrates superior language fashions, hybrid indexing strategies, and multi-vector question dealing with mechanisms to enhance retrieval precision and scalability considerably. By leveraging each vector embeddings and conventional indexing strategies, VectorSearch can effectively handle large-scale datasets, making it a robust software for complicated search operations. The framework incorporates cache mechanisms and optimized search algorithms, enhancing response instances and general efficiency. These capabilities set it other than typical techniques, providing a complete resolution for doc retrieval.
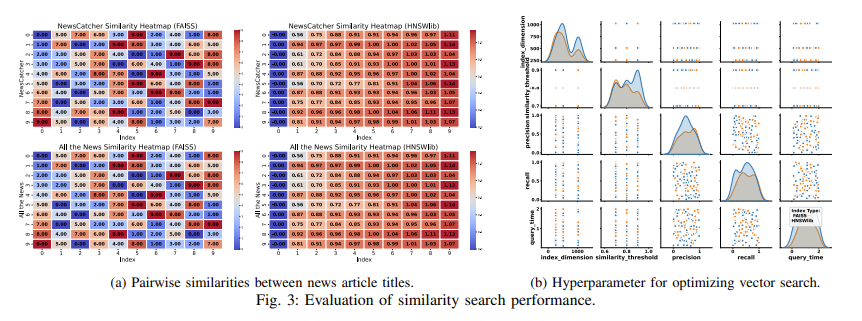
VectorSearch operates as a hybrid system that mixes the strengths of a number of indexing strategies, similar to FAISS for distributed indexing and HNSWlib for hierarchical search optimization. This method permits the seamless administration of large-scale datasets throughout a number of machines. Additionally, it introduces novel algorithms for multi-vector search, encoding paperwork into high-dimensional embeddings that seize the semantic relationships between totally different items of information. Integrating these embeddings right into a vector database permits the system to retrieve related paperwork based mostly on consumer queries effectively. Experiments on real-world datasets reveal that VectorSearch outperforms present techniques, with a recall charge of 76.62% and a precision charge of 98.68% at an index dimension of 1024.
The efficiency analysis of VectorSearch revealed important enhancements throughout numerous metrics. The system achieved a median question time of 0.47 seconds when utilizing the BERT-base-uncased mannequin and the FAISS indexing method, which is significantly quicker than conventional retrieval techniques. This discount in question time is attributed to the modern use of hierarchical indexing and multi-vector question dealing with. Furthermore, the proposed framework helps real-time updates, enabling it to deal with dynamically evolving datasets with out intensive re-indexing. These enhancements make VectorSearch a flexible resolution for functions starting from internet serps to advice techniques.
Key takeaways from the analysis embody:
- Excessive Precision and Recall: VectorSearch achieved a recall charge of 76.62% and a precision charge of 98.68% when utilizing an index dimension of 1024, outperforming baseline fashions in numerous retrieval duties.
- Lowered Question Time: The system considerably diminished question time, reaching a median of 0.47 seconds for high-dimensional knowledge retrieval.
- Scalability: By integrating FAISS and HNSWlib, VectorSearch effectively handles large-scale and evolving datasets, making it appropriate for real-time functions.
- Help for Dynamic Knowledge: The framework helps real-time updates, enabling it to take care of excessive efficiency at the same time as knowledge modifications.

In conclusion, VectorSearch presents a sturdy resolution to the challenges confronted by present data retrieval techniques. By introducing a scalable and adaptable method, the analysis crew has created a framework that meets the calls for of recent data-intensive functions. The mixing of hybrid indexing strategies, multi-vector search operations, and superior language fashions leads to a big enhancement in retrieval accuracy and effectivity. This analysis paves the best way for future developments within the discipline, providing worthwhile insights into the event of next-generation doc retrieval techniques.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report might be launched in late October/early November 2024. Click on right here to arrange a name!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


