
PyTorch has formally launched torchao, a complete native library designed to optimize PyTorch fashions for higher efficiency and effectivity. The launch of this library is a milestone in deep studying mannequin optimization, offering customers with an accessible toolkit that leverages superior methods similar to low-bit varieties, quantization, and sparsity. The library is predominantly written in PyTorch code, guaranteeing ease of use and integration for builders engaged on inference and coaching workloads.
Key Options of torchao
- Gives complete assist for numerous generative AI fashions, similar to Llama 3 and diffusion fashions, guaranteeing compatibility and ease of use.
- Demonstrates spectacular efficiency beneficial properties, attaining as much as 97% speedup and important reductions in reminiscence utilization throughout mannequin inference and coaching.
- Affords versatile quantization methods, together with low-bit dtypes like int4 and float8, to optimize fashions for inference and coaching.
- Helps dynamic activation quantization and sparsity for numerous dtypes, enhancing the flexibleness of mannequin optimization.
- Options Quantization Conscious Coaching (QAT) to reduce accuracy degradation that may happen with low-bit quantization.
- It supplies easy-to-use, low-precision computing and communication workflows for coaching which might be appropriate with PyTorch’s ‘nn.Linear’ layers.
- Introduces experimental assist for 8-bit and 4-bit optimizers, serving as a drop-in substitute for AdamW to optimize mannequin coaching.
- Seamlessly integrates with main open-source tasks, similar to HuggingFace transformers and diffusers, and serves as a reference implementation for accelerating fashions.
These key options set up torchao as a flexible and environment friendly deep-learning mannequin optimization library.
Superior Quantization Methods
One of many standout options of torchao is its sturdy assist for quantization. The library’s inference quantization algorithms work over arbitrary PyTorch fashions that comprise ‘nn.Linear’ layers, offering weight-only and dynamic activation quantization for numerous dtypes and sparse layouts. Builders can choose essentially the most appropriate quantization methods utilizing the top-level ‘quantize_’ API. This API consists of choices for memory-bound fashions, similar to int4_weight_only and int8_weight_only, and compute-bound fashions. For compute-bound fashions, torchao can carry out float8 quantization, offering extra flexibility for high-performance mannequin optimization. Furthermore, torchao’s quantization methods are extremely composable, enabling the mix of sparsity and quantization for enhanced efficiency.
Quantization Conscious Coaching (QAT)
Torchao addresses the potential accuracy degradation related to post-training quantization, notably for fashions quantized at lower than 4 bits. The library consists of assist for Quantization Conscious Coaching (QAT), which has been proven to get better as much as 96% of the accuracy degradation on difficult benchmarks like Hellaswag. This function is built-in as an end-to-end recipe in torchtune, with a minimal tutorial to facilitate its implementation. Incorporating QAT makes torchao a robust device for coaching fashions with low-bit quantization whereas sustaining accuracy.
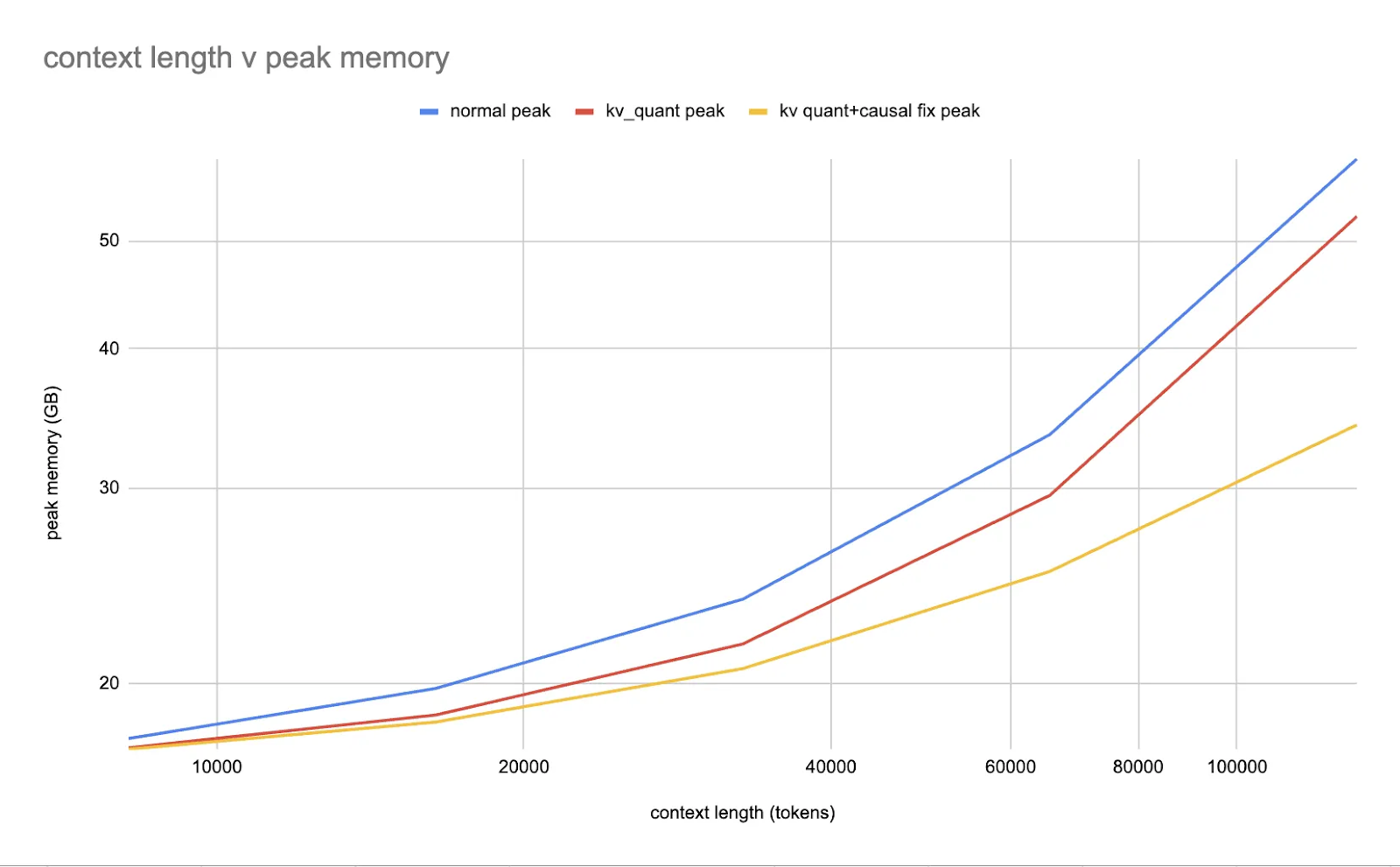
Coaching Optimization with Low Precision
Along with inference optimization, torchao affords complete assist for low-precision computing and communication throughout coaching. The library consists of easy-to-use workflows for decreasing the precision of coaching compute and distributed communications, starting with float8 for `torch.nn.Linear` layers.
Torchao has demonstrated spectacular outcomes, similar to a 1.5x speedup for Llama 3 70B pretraining when utilizing float8. The library additionally supplies experimental assist for different coaching optimizations, similar to NF4 QLoRA in torchtune, prototype int8 coaching, and accelerated sparse 2:4 coaching. These options make torchao a compelling selection for customers trying to speed up coaching whereas minimizing reminiscence utilization.
Low-Bit Optimizers
Impressed by the pioneering work of Bits and Bytes in low-bit optimizers, torchao introduces prototype assist for 8-bit and 4-bit optimizers as a drop-in substitute for the broadly used AdamW optimizer. This function permits customers to change to low-bit optimizers seamlessly, additional enhancing mannequin coaching effectivity with out considerably modifying their current codebases.
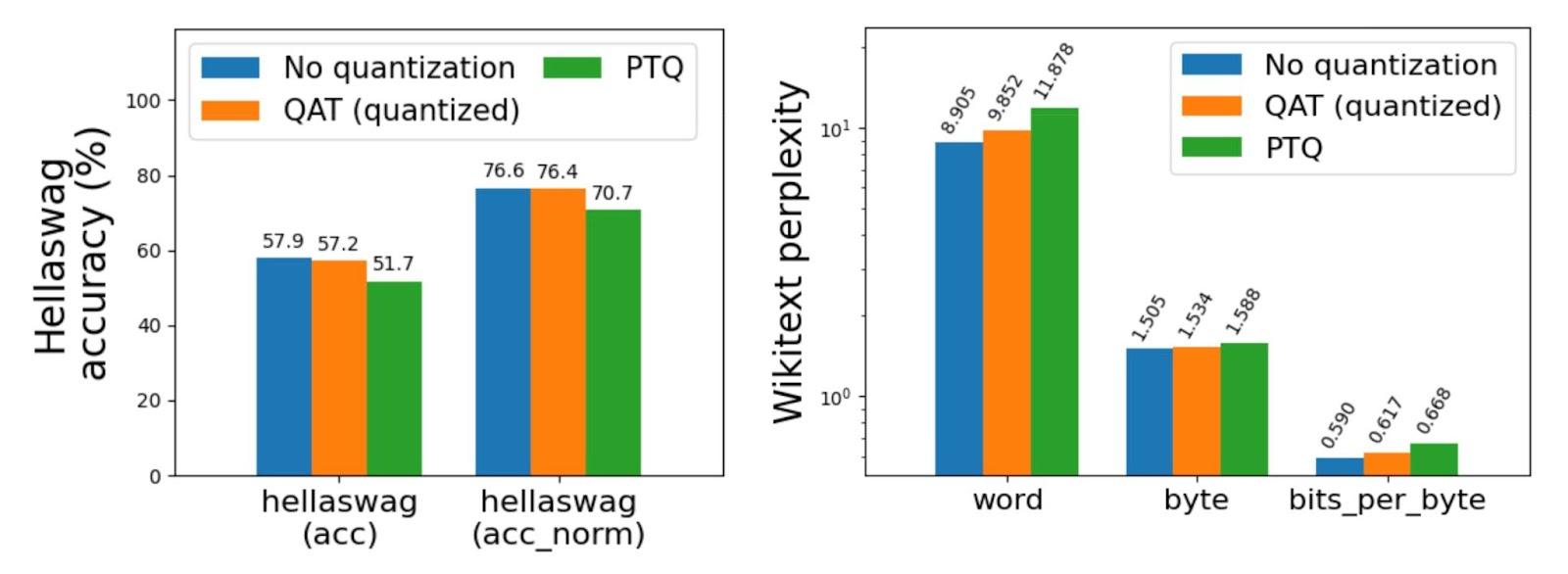
Integrations and Future Developments
Torchao has been actively built-in into among the most important open-source tasks within the machine-learning group. These integrations embody serving as an inference backend for HuggingFace transformers, contributing to diffusers-torchao for accelerating diffusion fashions, and offering QLoRA and QAT recipes in torchtune. torchao’s 4-bit and 8-bit quantization methods are additionally supported within the SGLang venture, making it a invaluable device for these engaged on analysis and manufacturing deployments.
Transferring ahead, the PyTorch workforce has outlined a number of thrilling developments for torchao. These embody pushing the boundaries of quantization by going decrease than 4-bit, growing performant kernels for high-throughput inference, increasing to extra layers, scaling varieties, or granularities, and supporting extra {hardware} backends, similar to MX {hardware}.
Key Takeaways from the Launch of torchao
- Important Efficiency Positive factors: Achieved as much as 97% speedup for Llama 3 8B inference utilizing superior quantization methods.
- Discount in Useful resource Consumption: Demonstrated 73% peak VRAM discount for Llama 3.1 8B inference and 50% discount in VRAM for diffusion fashions.
- Versatile Quantization Assist: Gives in depth choices for quantization, together with float8 and int4, with assist for QAT to get better accuracy.
- Low-Bit Optimizers: Launched 8-bit and 4-bit optimizers as a drop-in substitute for AdamW.
- Integration with Main Open-Supply Tasks: Actively built-in into HuggingFace transformers, diffusers-torchao, and different key tasks.
In conclusion, the launch of torchao represents a significant step ahead for PyTorch, offering builders with a robust toolkit to make fashions sooner and extra environment friendly throughout coaching and inference situations.
Take a look at the Particulars and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


