
Small language fashions (SLMs) have grow to be a focus in pure language processing (NLP) on account of their potential to deliver high-quality machine intelligence to on a regular basis gadgets. In contrast to giant language fashions (LLMs) that function inside cloud knowledge facilities and demand vital computational sources, SLMs goal to democratize synthetic intelligence by making it accessible on smaller, resource-constrained gadgets akin to smartphones, tablets, and wearables. These fashions usually vary from 100 million to five billion parameters, a fraction of what LLMs use. Regardless of their smaller dimension, they’re designed to carry out complicated language duties effectively, addressing the rising want for real-time, on-device intelligence. The analysis into SLMs is essential, because it represents the way forward for accessible, environment friendly AI that may function with out reliance on intensive cloud infrastructure.
One of many essential challenges in trendy NLP is optimizing AI fashions for gadgets with restricted computational sources. LLMs, whereas highly effective, are resource-intensive, typically requiring tons of of 1000’s of GPUs to function successfully. This computational demand restricts their deployment to centralized knowledge facilities, limiting their potential to perform on moveable gadgets that require real-time responses. The event of SLMs addresses this downside by creating environment friendly fashions to run straight on the gadget whereas sustaining excessive efficiency throughout varied language duties. Researchers have acknowledged the significance of balancing efficiency with effectivity, aiming to create fashions that require fewer sources however nonetheless carry out duties like commonsense reasoning, in-context studying, and mathematical problem-solving.
Researchers have explored strategies to scale back the complexity of enormous fashions with out compromising their potential to carry out effectively on key duties. Strategies like mannequin pruning, data distillation, and quantization have been generally used. Pruning removes much less vital neurons from a mannequin to scale back its dimension and computational load. Data distillation transfers data from a bigger mannequin to a smaller one, permitting the smaller mannequin to duplicate the habits of its bigger counterpart. Quantization reduces the precision of calculations, which helps in dashing up the mannequin and reducing its reminiscence utilization. Additionally, improvements like parameter sharing and layer-wise scaling have additional optimized fashions to carry out effectively on gadgets like smartphones and tablets. Whereas these strategies have helped enhance the effectivity of SLMs, they’re typically not sufficient to attain the identical degree of efficiency as LLMs with out additional refinement.
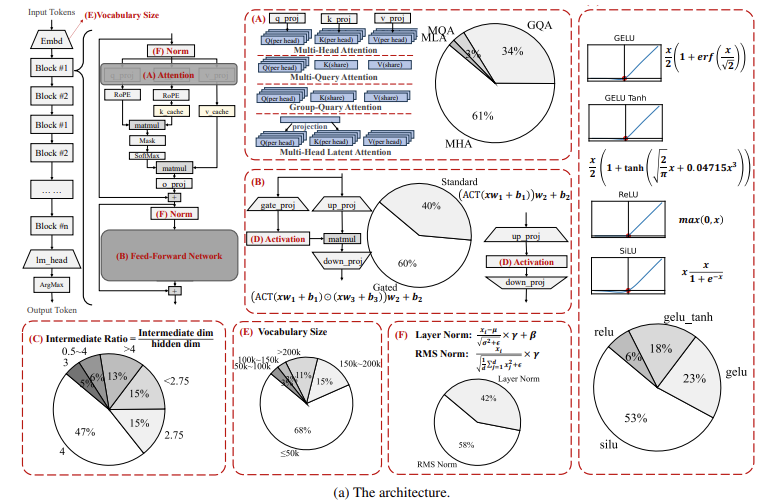
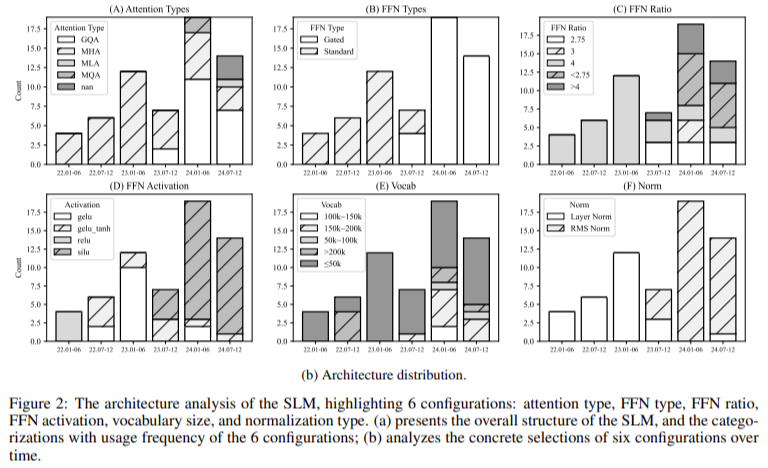
The analysis from the Beijing College of Posts and Telecommunications (BUPT), Peng Cheng Laboratory, Helixon Analysis, and the College of Cambridge introduces new architectural designs geared toward advancing SLMs. Their work focuses on transformer-based, decoder-only fashions, permitting extra environment friendly on-device processing. To attenuate computational calls for, they launched improvements akin to multi-query consideration mechanisms and gated feed-forward neural networks (FFNs). As an example, multi-query consideration reduces the reminiscence overhead usually related to the eye mechanism in transformer fashions. On the similar time, the gated FFN construction permits the mannequin to route info by the community, bettering effectivity dynamically. These developments allow smaller fashions to carry out duties successfully, from language comprehension to reasoning and problem-solving, whereas consuming fewer computational sources.
The structure proposed by the researchers revolves round optimizing reminiscence utilization and processing velocity. The introduction of group-query consideration permits the mannequin to scale back the variety of question teams whereas preserving consideration range. This mechanism has confirmed significantly efficient in lowering reminiscence utilization. They use SiLU (Sigmoid Linear Unit) because the activation perform, exhibiting marked enhancements in dealing with language duties in comparison with extra standard features like ReLU. Additionally, the researchers launched nonlinearity compensation to deal with frequent points with small fashions, such because the characteristic collapse downside, which impairs a mannequin’s potential to course of complicated knowledge. This compensation is achieved by integrating superior mathematical shortcuts into the transformer structure, making certain the mannequin stays sturdy even when scaled down. Furthermore, parameter-sharing strategies have been carried out, which permit the mannequin to reuse weights throughout completely different layers, additional lowering reminiscence consumption and bettering inference occasions, making it appropriate for gadgets with restricted computational capability.
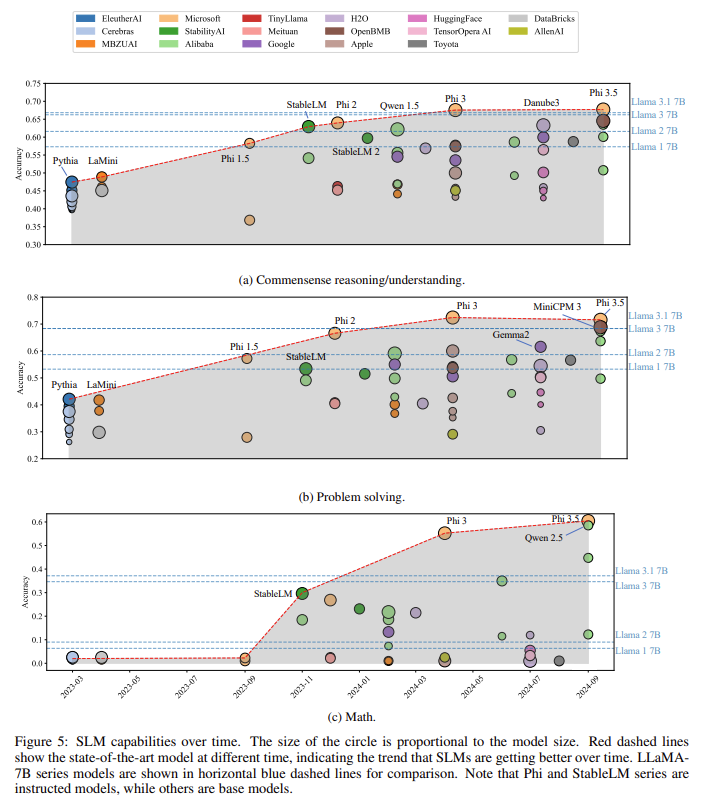
The outcomes of this examine display substantial enhancements in each efficiency and effectivity. One of many standout fashions, Phi-3 mini, achieved a 14.5% greater accuracy in mathematical reasoning duties than the state-of-the-art LLaMA 3.1, a big language mannequin with 7 billion parameters. Moreover, in commonsense reasoning duties, the Phi household of fashions outperformed a number of main fashions, together with LLaMA, by reaching a 67.6% accuracy rating. Equally, the Phi-3 mannequin posted an accuracy of 72.4% in problem-solving duties, putting it among the many top-performing SLMs. These outcomes spotlight the success of the brand new structure in sustaining excessive efficiency whereas lowering the computational calls for usually related to bigger fashions. The analysis additionally confirmed that these fashions are environment friendly and scalable, providing constant efficiency throughout varied duties, from easy reasoning to extra complicated mathematical issues.
Concerning deployment, the fashions have been examined on varied edge gadgets, together with the Jetson Orin NX and high-end smartphones. The fashions demonstrated vital reductions in each inference latency and reminiscence utilization. For instance, the Qwen-2 1.5B mannequin lowered inference latency by over 50%, making it one of the crucial environment friendly fashions examined. Reminiscence utilization was notably optimized in fashions just like the OpenELM-3B, which used as much as 30% much less reminiscence than different fashions with an analogous parameter rely. These outcomes are promising for the way forward for SLMs, as they display that reaching excessive efficiency on resource-constrained gadgets is feasible, opening the door for real-time AI functions on cellular and wearable applied sciences.
Key takeaways from the analysis will be summarized as follows:
- Group-query consideration and gated feed-forward networks (FFNs): These improvements considerably cut back reminiscence utilization and processing time with out sacrificing efficiency. Group-query consideration reduces the variety of queries with out dropping consideration range, making the mannequin extra environment friendly.
- Excessive-quality pre-training datasets: The analysis underscores the significance of high-quality, open-source datasets, akin to FineWeb-Edu and DCLM. The information high quality typically outweighs the amount, permitting for higher generalization and reasoning capabilities.
- Parameter sharing and nonlinearity compensation: These strategies play a vital function in bettering the runtime efficiency of the fashions. Parameter sharing reduces the redundancy within the mannequin layers, whereas nonlinearity compensation addresses the characteristic collapse situation, making certain the mannequin stays sturdy in real-time functions.
- Mannequin scalability: Regardless of their smaller dimension, the Phi household of fashions constantly outperformed bigger fashions like LLaMA in duties requiring mathematical reasoning and commonsense understanding, proving that SLMs can rival LLMs when designed appropriately.
- Environment friendly edge deployment: The numerous discount in latency and reminiscence utilization demonstrates that these fashions are well-suited for deployment on resource-constrained gadgets like smartphones and tablets. Fashions just like the Qwen-2 1.5B achieved over 50% latency discount, confirming their sensible functions in real-time eventualities.
- Structure improvements with real-world impression: The introduction of strategies akin to group-query consideration, gated FFNs, and parameter sharing proves that improvements on the architectural degree can yield substantial efficiency enhancements with out rising computational prices, making these fashions sensible for widespread adoption in on a regular basis expertise.
In conclusion, the analysis into small language fashions presents a path ahead for creating extremely environment friendly AI that may function on varied gadgets with out reliance on cloud-based infrastructure. The issue of balancing efficiency with computational effectivity has been addressed by progressive architectural designs akin to group-query consideration and gated FFNs, which allow SLMs to ship outcomes akin to these of LLMs regardless of having a fraction of the parameters. The analysis reveals that with the proper dataset, structure, and deployment methods, SLMs will be scaled to deal with varied duties, from reasoning to problem-solving, whereas operating effectively on resource-constrained gadgets. This represents a major development in making AI extra accessible and purposeful for real-world functions, making certain that the advantages of machine intelligence can attain customers throughout completely different platforms.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 52k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


