
Giant language and imaginative and prescient fashions (LLVMs) face a essential problem in balancing efficiency enhancements with computational effectivity. As fashions develop in measurement, reaching as much as 80B parameters, they ship spectacular outcomes however require huge {hardware} sources for coaching and inference. This concern turns into much more urgent for real-time functions, similar to augmented actuality (AR), the place deploying these massive fashions on gadgets with restricted sources, like cellphones, is almost unimaginable. Overcoming this problem is important for enabling LLVMs to perform effectively throughout varied fields with out the excessive computational prices historically related to bigger fashions.
Current strategies to enhance the efficiency of LLVMs usually contain scaling up mannequin measurement, curating bigger datasets, and incorporating further modules for enhanced vision-language understanding. Whereas these approaches enhance accuracy, they impose important computational burdens, requiring high-end GPUs and substantial VRAM for coaching and inference. This makes them impractical for real-time functions and resource-limited environments. Moreover, integrating exterior imaginative and prescient modules provides complexity, additional limiting their usability in on-device functions.
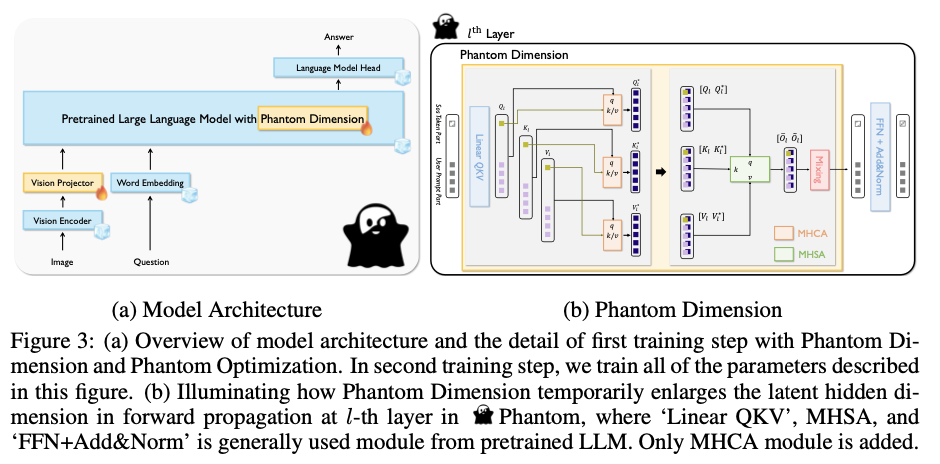
The researchers from KAIST suggest the Phantom LLVM household, which incorporates fashions starting from 0.5B to 7B parameters. Phantom enhances studying capabilities by briefly growing the latent hidden dimension throughout multi-head self-attention (MHSA), a function termed “Phantom Dimension.” This innovation permits the mannequin to embed considerably extra vision-language information with no everlasting improve in mannequin measurement. Phantom Optimization (PO) can be launched, combining autoregressive supervised fine-tuning (SFT) with a direct desire optimization (DPO)-like strategy to reduce errors and ambiguities in outputs. This strategy considerably improves computational effectivity whereas sustaining excessive efficiency.
The Phantom fashions make use of the InternViT-300M as a imaginative and prescient encoder, which aligns text-to-image representations by means of contrastive studying. The imaginative and prescient projector, constructed utilizing two totally linked layers, adapts the hidden dimension to the corresponding multimodal LLM’s latent area. A core facet of Phantom is the momentary enlargement of the latent hidden dimension throughout MHSA, which boosts the mannequin’s skill to embed vision-language information with out growing its bodily measurement. The fashions are skilled utilizing a dataset of two.8M visible instruction samples, curated into 2M Phantom triples (questions, appropriate solutions, and incorrect or ambiguous solutions). These triples play a vital position in coaching by means of PO, enhancing response accuracy by eliminating confusion.
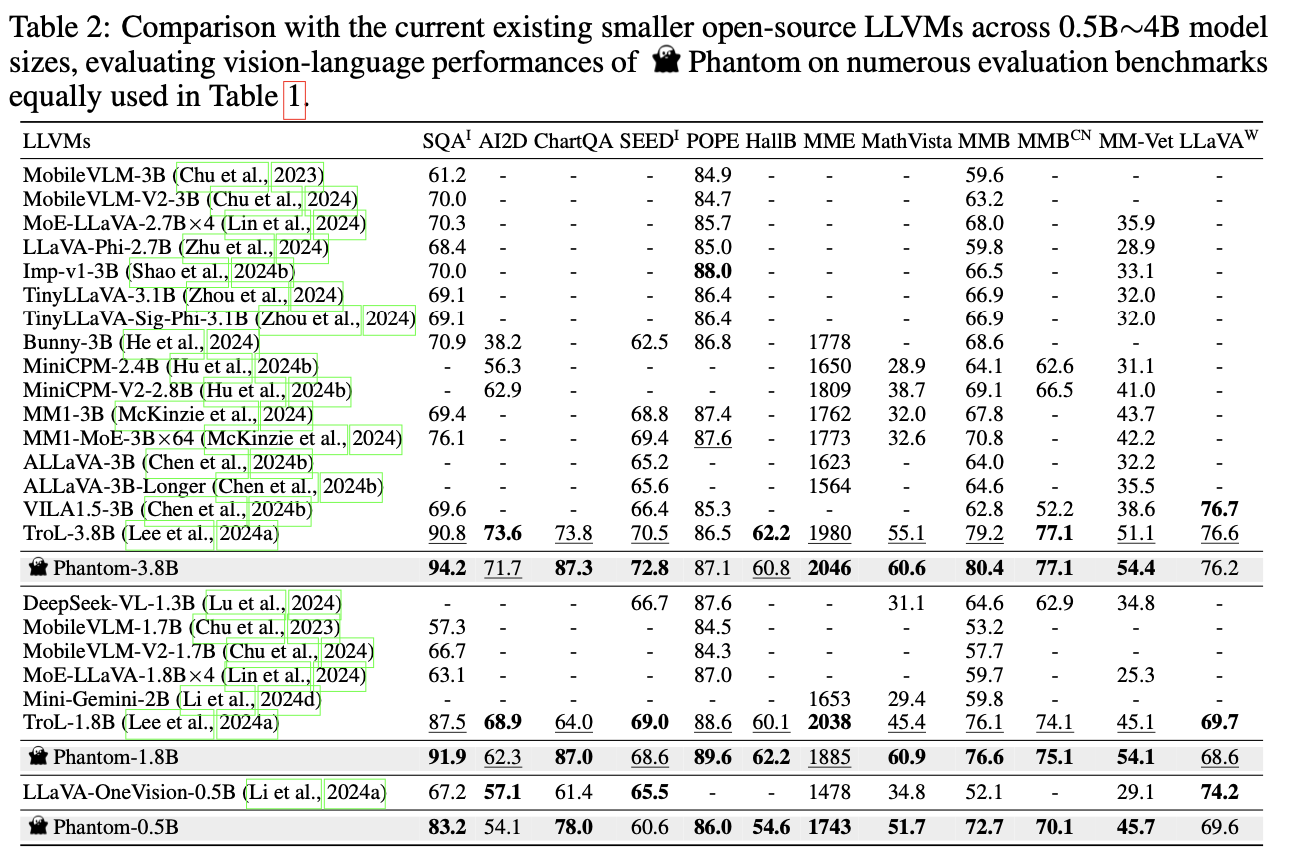
Phantom displays robust efficiency enhancements throughout a number of benchmarks, outperforming many bigger fashions in duties involving picture understanding, chart interpretation, and mathematical reasoning. As an example, in benchmarks like SQAI and ChartQA, Phantom’s accuracy exceeds that of bigger fashions similar to Cambrian-1-13B and SPHINX-MoE-7B×8. These outcomes reveal Phantom’s functionality to deal with complicated vision-language duties effectively, all whereas utilizing a smaller mannequin measurement. This effectivity is basically on account of Phantom Dimension and Phantom Optimization, which permit the mannequin to maximise studying with no proportional improve in computational necessities.
The Phantom LLVM household introduces a brand new strategy to addressing the problem of balancing efficiency and computational effectivity in massive vision-language fashions. Via the modern use of Phantom Dimension and Phantom Optimization, Phantom allows smaller fashions to carry out on the stage of a lot bigger fashions, lowering the computational burden and making these fashions possible for deployment in resource-constrained environments. This innovation has the potential to develop the applying of AI fashions throughout a broader vary of real-world eventualities.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


