
Massive Language Fashions (LLMs) have made vital strides in processing intensive contexts, with some fashions able to dealing with as much as 10 million tokens. Nonetheless, this development brings challenges in inference effectivity as a result of quadratic complexity of consideration computation. Whereas KV caching has been broadly adopted to forestall redundant computations, it introduces substantial GPU reminiscence necessities and elevated inference latency for lengthy contexts. The Llama-2-7B mannequin, as an illustration, requires roughly 500GB per million tokens in FP16 format. These points spotlight the vital want to scale back token entry and storage prices to boost inference effectivity. The answer to those challenges lies in using the dynamic sparsity inherent within the consideration mechanism, the place every question vector considerably interacts with solely a restricted subset of key and worth vectors.
Present makes an attempt to speed up long-context LLM inference have centered on compressing the KV cache dimension by using consideration sparsity. Nonetheless, these strategies typically lead to vital accuracy drops as a result of dynamic nature of consideration sparsity. Some approaches, like FlexGen and Lamina, offload the KV cache to CPU reminiscence however face challenges with gradual and dear full-attention computation. Different strategies, resembling Quest and InfLLM, partition the KV cache into blocks and choose consultant key vectors, however their effectiveness relies upon closely on the accuracy of those representatives. SparQ, InfiniGen, and LoKi try and approximate probably the most related top-k keys by lowering head dimensions.
Researchers from Microsoft Analysis, Shanghai Jiao Tong College, and Fudan College introduce RetrievalAttention, an revolutionary methodology designed to speed up long-context LLM era. It employs dynamic sparse consideration throughout token era, permitting probably the most vital tokens to emerge from intensive context knowledge. To deal with the out-of-distribution (OOD) problem, RetrievalAttention introduces a vector index particularly tailor-made for the eye mechanism, specializing in question distribution reasonably than key similarities. This method permits the traversal of only one% to three% of key vectors, successfully figuring out probably the most related tokens for correct consideration scores and inference outcomes. RetrievalAttention additionally optimizes GPU reminiscence consumption by retaining a small variety of KV vectors in GPU reminiscence following static patterns, whereas offloading the bulk to CPU reminiscence for index development. Throughout token era, it effectively retrieves vital tokens utilizing vector indexes on the CPU and merges partial consideration outcomes from each CPU and GPU. This technique permits RetrievalAttention to carry out consideration computation with diminished latency and minimal GPU reminiscence footprint.
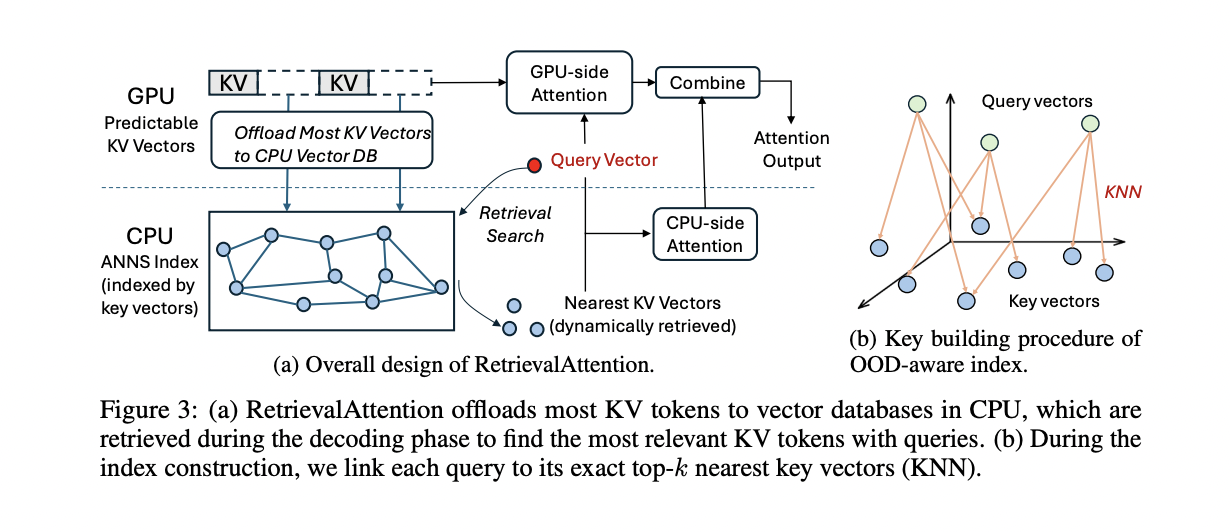
RetrievalAttention employs a CPU-GPU co-execution technique to speed up consideration computation for long-context LLM inference. The tactic decomposes consideration computation into two disjoint units of KV cache vectors: predictable ones on GPU and dynamic ones on CPU. It makes use of patterns noticed within the prefill part to foretell persistently activated KV vectors throughout token era, persisting them within the GPU cache. The present implementation makes use of fastened preliminary tokens and the final sliding window of the context because the static sample, just like StreamingLLM. For CPU-side computation, RetrievalAttention builds an attention-aware vector search index to effectively retrieve related KV vectors. This index is constructed utilizing KNN connections from question vectors to key vectors, that are then projected onto key vectors to streamline the search course of. This method permits for scanning solely 1-3% of key vectors to realize excessive recall, considerably lowering index search latency. To reduce knowledge switch over the PCIe interface, RetrievalAttention independently computes consideration outcomes for CPU and GPU elements earlier than combining them, impressed by FastAttention.
RetrievalAttention demonstrates superior efficiency in each accuracy and effectivity in comparison with present strategies. It achieves comparable accuracy to full consideration whereas considerably lowering computational prices. In advanced duties like KV retrieval, RetrievalAttention outperforms static strategies resembling StreamingLLM and SnapKV, which lack dynamic token retrieval capabilities. It additionally surpasses InfLLM, which struggles with accuracy as a consequence of low-quality consultant vectors. RetrievalAttention’s means to precisely determine related key vectors permits it to keep up excessive process accuracy throughout numerous context lengths, from 4K to 128K tokens. Within the needle-in-a-haystack process, successfully focuses on vital info no matter place throughout the context window. Relating to latency, RetrievalAttention exhibits vital enhancements over full consideration and different strategies. It achieves 4.9× and 1.98× latency discount in comparison with Flat and IVF indexes respectively for 128K context, whereas scanning solely 1-3% of vectors. This mix of excessive accuracy and low latency demonstrates RetrievalAttention’s effectiveness in dealing with advanced, dynamic duties with lengthy contexts.
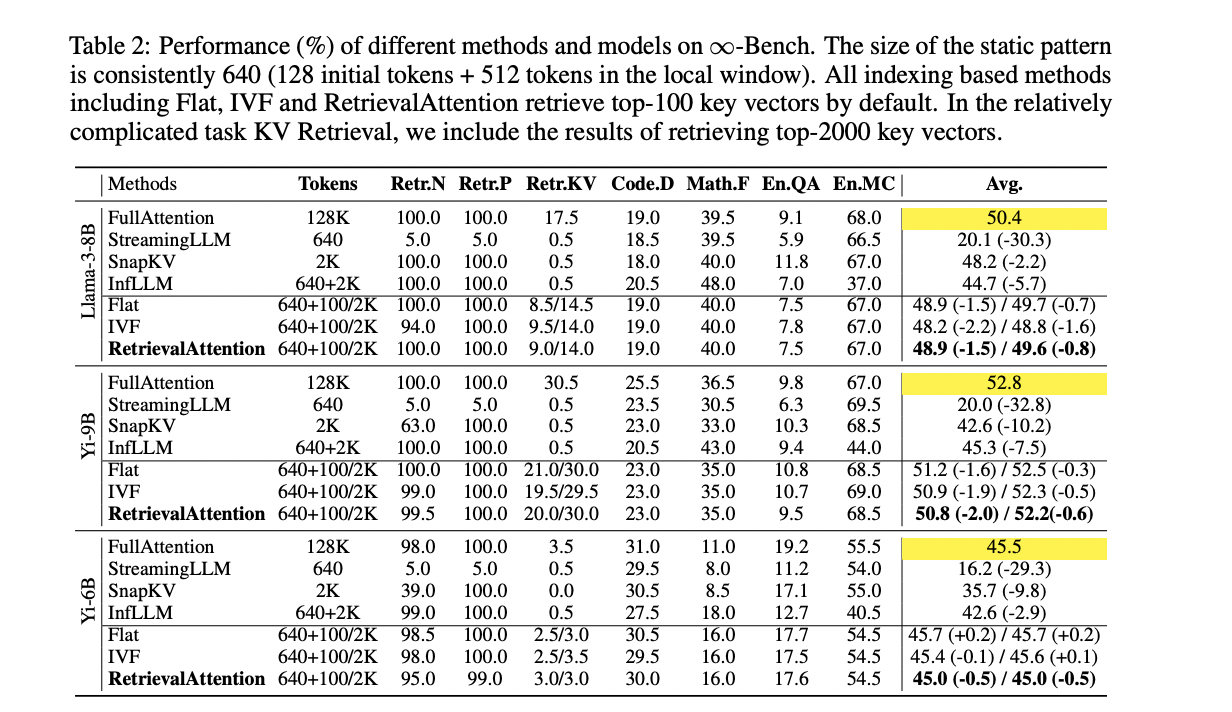
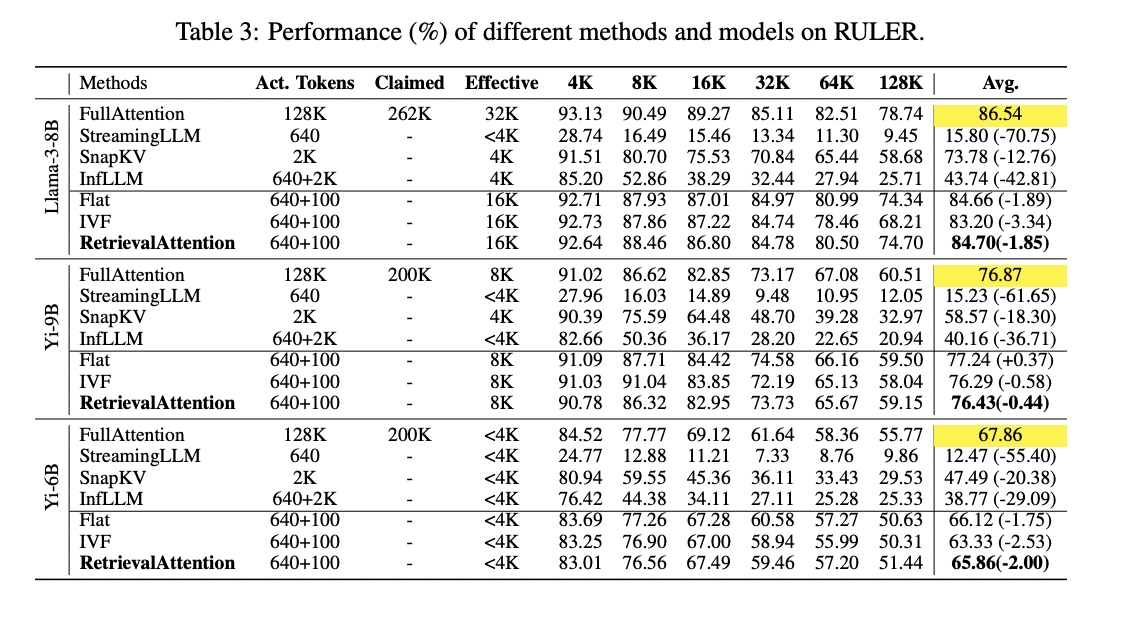
This research presents RetrievalAttention, an revolutionary resolution for accelerating long-context LLM inference by offloading most KV vectors to CPU reminiscence and using dynamic sparse consideration by vector search. The tactic addresses the distribution variations between question and key vectors, using an attention-aware method to effectively determine vital tokens for mannequin era. Experimental outcomes reveal RetrievalAttention’s effectiveness, reaching 4.9× and 1.98× decoding speedup in comparison with actual KNN and conventional ANNS strategies, respectively, on a single RTX4090 GPU with a context of 128K tokens. RetrievalAttention is the primary system to assist operating 8B-level LLMs with 128K tokens on a single 4090 (24GB) GPU, sustaining acceptable latency and preserving mannequin accuracy. This breakthrough considerably enhances the effectivity and accessibility of enormous language fashions for intensive context processing.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


