
Reinforcement Studying (RL) is a crucial space of ML that enables brokers to study from their interactions inside an atmosphere by receiving suggestions as rewards. A major problem in RL is fixing the temporal credit score project downside, which refers to figuring out which actions in a sequence contributed to attaining a desired consequence. That is notably tough when suggestions is sparse or delayed, that means brokers don’t instantly know if their actions are right. In such conditions, brokers should learn to correlate particular actions with outcomes, however the lack of speedy suggestions makes this a posh process. RL methods usually fail to generalize and scale successfully to extra difficult duties with out efficient mechanisms to resolve this problem.
The analysis addresses the problem of credit score project when rewards are delayed and sparse. RL brokers usually begin with out prior data of the atmosphere and should navigate by way of it primarily based solely on trial and error. When suggestions is scarce, the agent could wrestle to develop a sturdy decision-making course of as a result of it can’t discern which actions led to profitable outcomes. This state of affairs could be notably difficult in advanced environments with a number of steps resulting in a objective, the place solely the ultimate motion sequence produces a reward. In lots of situations, brokers find yourself studying inefficient insurance policies or fail to generalize their conduct throughout totally different environments because of this elementary downside.
Historically, RL has relied on methods like reward shaping and hierarchical reinforcement studying (HRL) to sort out the credit score project downside. Reward shaping is a technique the place synthetic rewards are added to information the agent’s conduct when pure rewards are inadequate. In HRL, duties are damaged down into less complicated sub-tasks or choices, with brokers being skilled to attain intermediate objectives. Whereas each methods could be efficient, they require important area data and human enter, making them tough to scale. Lately, massive language fashions (LLMs) have demonstrated potential in transferring human data into computational methods, providing new methods to enhance the credit score project course of with out extreme human intervention.
The analysis workforce from College Faculty London, Google DeepMind, and the College of Oxford developed a brand new strategy known as Credit score Project with Language Fashions (CALM). CALM leverages the ability of LLMs to decompose duties into smaller subgoals and assess the agent’s progress towards these objectives. In contrast to conventional strategies that require intensive human-designed rewards, CALM automates this course of by permitting the LLM to find out subgoals and supply auxiliary reward alerts. The approach reduces human involvement in designing RL methods, making it simpler to scale to totally different environments. Researchers declare that this methodology can deal with zero-shot settings, that means the LLM can consider actions with out requiring fine-tuning or prior examples particular to the duty.
CALM makes use of LLMs to evaluate whether or not particular subgoals are achieved throughout a process. As an example, within the MiniHack atmosphere used within the examine, brokers are tasked with choosing up a key and unlocking a door to obtain a reward. CALM breaks down this process into manageable subgoals, equivalent to “navigate to the important thing,” “choose up the important thing,” and “unlock the door.” Every time one in every of these subgoals is accomplished, CALM supplies an auxiliary reward to the RL agent, guiding it towards finishing the ultimate process. This technique reduces the necessity for manually designed reward capabilities, which are sometimes time-consuming and domain-specific. As a substitute, the LLM makes use of its prior data to successfully form the agent’s conduct.
The researchers’ experiments evaluated CALM utilizing a dataset of 256 human-annotated demonstrations from MiniHack, a gaming atmosphere that challenges brokers to unravel duties in a grid-like world. The outcomes confirmed that LLMs may efficiently assign credit score in zero-shot settings, that means the mannequin didn’t require prior examples or fine-tuning. Particularly, the LLM may acknowledge when subgoals had been achieved, offering helpful steering to the RL agent. The examine discovered that the LLM precisely acknowledged subgoals and aligned them with human annotations, attaining an F1 rating of 0.74. The LLM’s efficiency improved considerably when utilizing extra centered observations, equivalent to cropped photos exhibiting a 9×9 view across the agent. This implies that LLMs could be a worthwhile software in automating credit score project, notably in environments the place pure rewards are sparse or delayed.
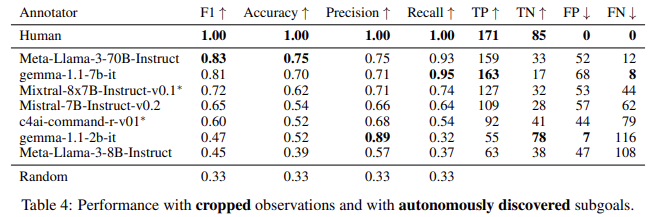
The researchers additionally reported that CALM’s efficiency was aggressive with that of human annotators in figuring out profitable subgoal completions. In some circumstances, the LLM achieved an accuracy price of 0.73 in detecting when an agent had accomplished a subgoal, and the auxiliary rewards supplied by CALM helped the agent study extra effectively. The workforce additionally in contrast the efficiency of CALM to current fashions like Meta-Llama-3 and located that CALM carried out effectively throughout numerous metrics, together with recall and precision, with precision scores starting from 0.60 to 0.97, relying on the mannequin and process.

In conclusion, the analysis demonstrates that CALM can successfully sort out the credit score project downside in RL by leveraging LLMs. CALM reduces the necessity for intensive human involvement in designing RL methods by breaking duties into subgoals and automating reward shaping. The experiments point out that LLMs can present correct suggestions to RL brokers, enhancing their studying skill in environments with sparse rewards. This strategy can improve RL efficiency in numerous purposes, making it a promising avenue for future analysis and growth. The examine highlights the potential for LLMs to generalize throughout duties, making RL methods extra scalable and environment friendly in real-world situations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


