
Earlier 3D mannequin era from single photographs confronted challenges. Feed-forward architectures produced simplistic objects resulting from restricted 3D knowledge. Gaussian splatting offered fast coarse geometry however lacked advantageous particulars and look at consistency. Naive gradient thresholding brought on extreme densification and swollen geometries. Regularisation strategies improved accuracy, however removing led to structural points. Consumer research revealed view consistency and high quality issues, emphasizing the necessity for sturdy frameworks. Information availability, element preservation, and consistency limitations highlighted the need for superior approaches. Vista3D addresses these challenges, introducing a framework balancing pace and high quality in 3D mannequin era from single photographs.
Researchers from the Nationwide College of Singapore and Huawei Applied sciences Ltd introduce Vista3D, a novel framework for producing 3D representations from a single picture. The system addresses the problem of unveiling hidden object dimensions via a two-phase method: a rough part using Gaussian Splatting for preliminary geometry and a advantageous part refining the geometry through Signed Distance Perform extraction and optimization. This technique enhances mannequin high quality by capturing each seen and obscured object facets. Vista3D harmonizes 2D and 3D-aware diffusion priors, balancing consistency and variety. The framework achieves swift, constant 3D era inside 5 minutes and allows user-driven enhancing via textual content prompts, doubtlessly advancing fields like gaming and digital actuality.
Vista3D’s methodology for producing 3D objects from single photographs employs a multi-stage method. The method begins with coarse geometry era utilizing 3D Gaussian Splatting, offering a fast preliminary 3D construction. This geometry undergoes refinement via transformation into signed distance fields and the introduction of a differentiable isosurface illustration. These steps improve floor accuracy and visible attraction. The framework incorporates diffusion priors to allow numerous 3D era, using gradient magnitude constraints and angular-based composition to keep up consistency whereas exploring object range.

The methodology follows a coarse-to-fine mesh era technique, using top-Ok densification regularisation. This method progressively refines the preliminary geometry to attain high-fidelity outputs. By combining superior methods in geometry era, refinement, and texture mapping, Vista3D addresses challenges in conventional 3D modeling. The framework’s modern use of diffusion priors and representations enhances element, consistency, and output range, leading to high-quality 3D fashions generated effectively from single photographs. This complete method demonstrates important developments in 3D object era from restricted 2D inputs.

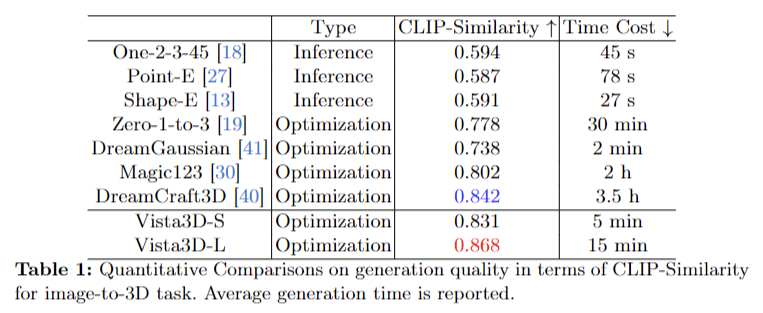
Outcomes from the Vista3D framework exhibit important developments in 3D object era from single photographs. Vista3D-L achieved state-of-the-art efficiency throughout metrics, together with PSNR, SSIM, and LPIPS, outperforming present strategies. CLIP-similarity scores of 0.831 for Vista3D-S and 0.868 for Vista3D-L point out excessive consistency between generated 3D views and reference photographs. The framework generates 3D objects in roughly 5 minutes, a notable enchancment in processing time. Qualitative assessments reveal superior texture high quality, notably in eventualities with much less informative reference views. Ablation research verify the effectiveness of key elements, whereas comparisons with strategies like One-2-3-45 and Wonder3D spotlight Vista3D’s superior efficiency in texture, geometry high quality, and look at consistency.
In conclusion, the Vista3D framework introduces a coarse-to-fine method for exploring 3D facets of single photographs, enabling user-driven enhancing and bettering era high quality via picture captions. The environment friendly course of begins with Gaussian Splatting for coarse geometry, adopted by refinement utilizing isosurface illustration and disentangled textures, producing textured meshes in about 5 minutes. The angular composition of diffusion priors enhances range whereas sustaining 3D consistency. The highest-k densification technique and regularisation methods contribute to correct geometry and advantageous particulars. Vista3D outperforms earlier strategies in realism and element, balancing era time and mesh high quality. The authors anticipate their work will encourage additional developments in single-image 3D era analysis.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Expertise (IIT), Kharagpur. With a robust ardour for Information Science, he’s notably within the numerous purposes of synthetic intelligence throughout numerous domains. Shoaib is pushed by a want to discover the most recent technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sector of AI


