
Multi-agent reinforcement studying (MARL) is a area centered on creating methods the place a number of brokers cooperate to unravel duties that exceed the capabilities of particular person brokers. This space has garnered vital consideration as a result of its relevance in autonomous autos, robotics, and complicated gaming environments. The purpose is to allow brokers to work collectively effectively, adapt to dynamic environments, and remedy complicated duties that require coordination and collaboration. In doing so, researchers develop fashions that facilitate interplay between brokers to make sure efficient problem-solving. This department of synthetic intelligence has grown quickly as a result of its potential for real-world purposes, requiring fixed enhancements in agent cooperation and decision-making algorithms.
One of many key challenges in MARL is that it’s notoriously tough to coordinate a number of brokers, significantly in environments that current dynamic and complicated challenges. Brokers sometimes need assistance with two primary points: low pattern effectivity and poor generalization. Pattern effectivity refers back to the agent’s skill to be taught successfully from a restricted variety of experiences, whereas generalization is their skill to use discovered behaviors to new, unseen environments. Human experience is commonly wanted to information agent decision-making in complicated situations, however it’s expensive, scarce, and time-consuming. The problem is compounded by the truth that most reinforcement studying frameworks rely closely on human intervention in the course of the coaching part, resulting in vital scalability limitations.
A number of present strategies try to enhance agent collaboration and decision-making by introducing particular frameworks and algorithms. Some strategies give attention to role-based groupings, such because the RODE methodology, which decomposes the motion area into roles to create extra environment friendly insurance policies. Others, like GACG, use graph-based fashions to characterize agent interactions and optimize their cooperation. These present strategies, whereas useful, nonetheless go away gaps in agent adaptability and fail to deal with the restrictions of human intervention. They both rely an excessive amount of on predefined roles or require complicated mathematical modeling that limits their flexibility in real-world purposes. This inefficiency underscores the necessity for extra adaptable frameworks that require much less steady human involvement throughout coaching.
Researchers from Northwestern Polytechnical College and the College of Georgia have launched a novel framework referred to as HARP (Human-Assisted Regrouping with Permutation Invariant Critic). This progressive method permits brokers to regroup dynamically, even throughout deployment, with restricted human intervention. HARP is exclusive as a result of it allows non-expert human customers to supply helpful suggestions throughout deployment while not having steady, expert-level steering. The first aim of HARP is to scale back the reliance on human specialists throughout coaching whereas permitting for strategic human enter throughout deployment, successfully bridging the hole between automation and human-guided refinement.
HARP’s key innovation lies in its mixture of automated grouping in the course of the coaching part and human-assisted regrouping throughout deployment. Throughout coaching, brokers be taught to kind teams autonomously, optimizing their collaborative job completion. When deployed, they actively search human help when crucial, utilizing a Permutation Invariant Group Critic to guage and refine groupings primarily based on human solutions. This methodology permits brokers to be extra adaptive to complicated environments, as human enter is built-in to right or improve group dynamics when brokers face challenges. The distinctive characteristic of HARP is that it permits non-expert people to supply significant contributions because the system refines their solutions by way of reevaluation. The strategy dynamically adjusts group compositions primarily based on Q-value evaluations and agent efficiency.
The efficiency of HARP was examined in a number of cooperative environments utilizing six maps within the StarCraft II Multi-Agent Problem, masking three ranges of problem: Simple (8m, MMM), Laborious (8m vs 9m, 5m vs 6m), and Tremendous Laborious (MMM2, hall). In these checks, brokers managed by HARP outperformed these guided by conventional strategies, attaining a win price of 100% throughout all six maps. On more durable maps, reminiscent of 5m vs 6m, the place different strategies achieved win charges of solely 53.1% to 71.2%, HARP’s brokers confirmed marked enchancment, attaining a 100% success price. The strategy additionally improved agent efficiency by greater than 10% in comparison with different methods that don’t incorporate human help. The introduction of human enter throughout deployment and automated grouping throughout coaching resulted in vital enhancements throughout completely different problem ranges, showcasing the system’s skill to adapt and reply to complicated conditions effectively.
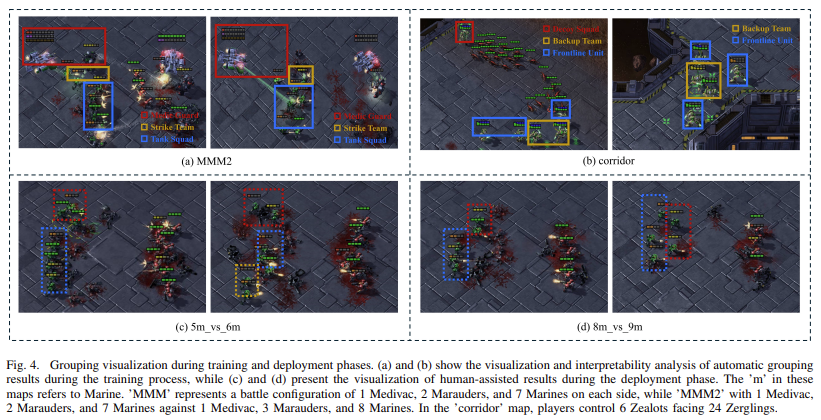
The outcomes from HARP’s implementation spotlight its vital impression on bettering multi-agent methods. Its skill to actively search and combine human steering throughout deployment, significantly in difficult environments, reduces the necessity for human experience throughout coaching. HARP demonstrated a marked enhance in success charges on tough maps, reminiscent of MMM2 and the hall map, the place the efficiency of different strategies faltered. On the hall map, brokers managed by HARP achieved a win price of 100%, in comparison with 0% for various approaches. The framework’s flexibility permits it to adapt dynamically to environmental modifications, making it a sturdy resolution for complicated multi-agent situations.

In conclusion, HARP gives a breakthrough in multi-agent reinforcement studying by lowering the necessity for steady human involvement throughout coaching whereas permitting for focused human enter throughout deployment. This technique addresses the important thing challenges of low pattern effectivity and poor generalization by enabling dynamic group changes primarily based on human suggestions. By considerably rising agent efficiency throughout varied problem ranges, HARP presents a scalable and adaptable resolution to multi-agent coordination. The profitable software of this framework within the StarCraft II atmosphere suggests its potential for broader use in real-world situations requiring human-machine collaboration, reminiscent of robotics and autonomous methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


