
The discharge of the FC-AMF-OCR Dataset by LightOn marks a big milestone in optical character recognition (OCR) and machine studying. This dataset is a technical achievement and a cornerstone for future analysis in synthetic intelligence (AI) and laptop imaginative and prescient. Introducing such a dataset opens up new potentialities for researchers and builders, permitting them to enhance OCR fashions, that are important in changing pictures of textual content into machine-readable textual content codecs.
Background of LightOn and FC-AMF-OCR Dataset
LightOn, an organization acknowledged for its pioneering contributions to AI and machine studying, has constantly pushed the boundaries of know-how. The FC-AMF-OCR Dataset is one among their newest initiatives, designed to facilitate extra correct and environment friendly OCR duties. It’s well-known that OCR know-how has a variety of functions, from digitizing printed books to enabling real-time textual content recognition in on a regular basis gadgets. Regardless of many developments, OCR stays difficult, notably in dealing with complicated fonts, noisy pictures, and various languages.
The FC-AMF-OCR Dataset goals to bridge these gaps by offering a big and various set of coaching knowledge. This knowledge helps AI fashions be taught and adapt to varied challenges related to textual content recognition. By together with a big selection of fonts, textures, and picture circumstances, LightOn ensures that the dataset is complete sufficient to deal with a lot of OCR know-how’s present limitations.
Significance of the Dataset
The discharge of the FC-AMF-OCR Dataset is particularly necessary attributable to its concentrate on AMF or Amorphous Meta-Fonts. These meta-fonts are characterised by their summary and fluid shapes, which might pose vital challenges for conventional OCR fashions. By incorporating these distinctive fonts into the dataset, LightOn encourages the event of AI fashions that may deal with even probably the most tough textual content recognition duties.
OCR know-how performs a significant position in numerous sectors. For instance, OCR digitizes and organizes huge quantities of printed paperwork within the authorized and medical industries. Within the publishing trade, it permits the conversion of bodily books into digital codecs, making literature extra accessible to a worldwide viewers. The accuracy of OCR know-how can instantly impression productiveness and accessibility in these fields. The FC-AMF-OCR Dataset permits builders to create extra strong and versatile OCR fashions, which might considerably enhance these sectors.
Technical Options of the Dataset
The technical points of the FC-AMF-OCR Dataset display its versatility and utility for researchers. The dataset includes 1000’s of pictures, every containing numerous varieties, starting from clear and crisp digital textual content to tougher handwritten and creative fonts. LightOn has designed the dataset to be adaptable to a variety of use instances, together with textual content recognition in noisy environments, distorted pictures, and paperwork with a number of languages.
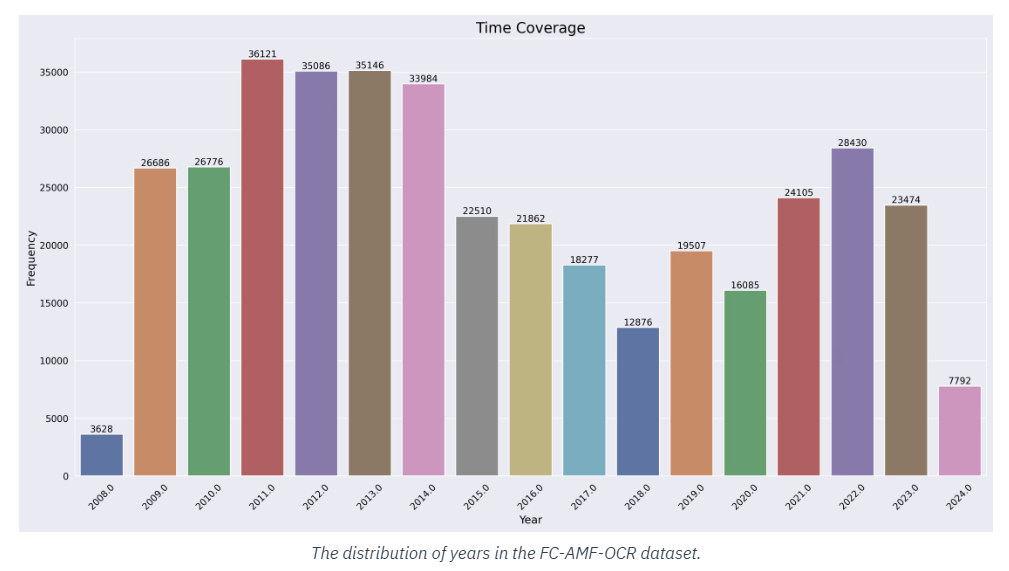
One of many dataset’s most crucial elements is its inclusion of Amorphous Meta-Fonts (AMF), which offer a excessive diploma of variability in textual content types. These fonts aren’t usually present in standard datasets, making the FC-AMF-OCR Dataset distinctive in its capability to coach OCR fashions to acknowledge much less structured, extra fluid textual content varieties. That is notably helpful for AI functions in artistic industries, the place textual content usually takes on a extra creative or non-standard type.
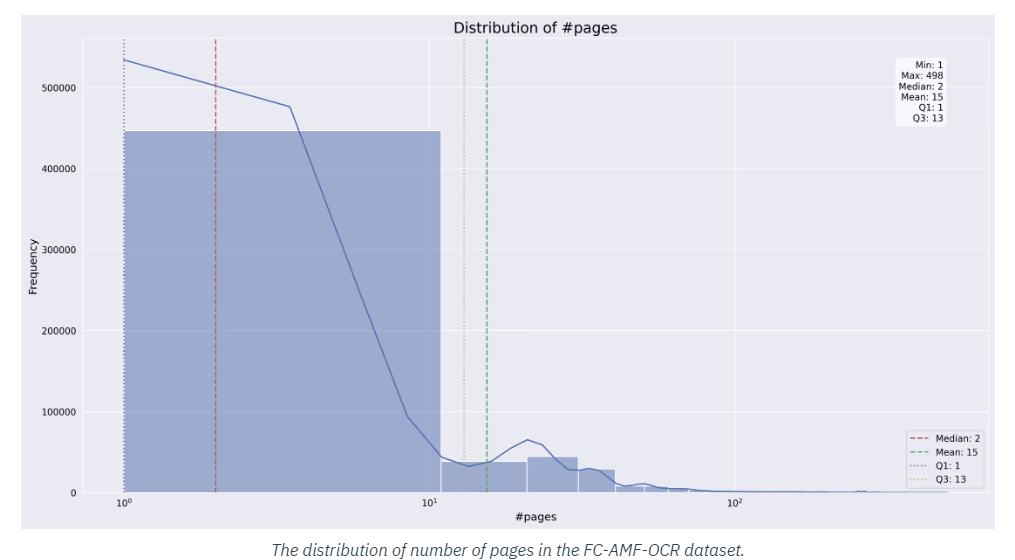
The dataset is designed to be extremely accessible and simply built-in into present machine-learning workflows. Researchers can obtain and implement the dataset of their initiatives with minimal friction, permitting them to concentrate on bettering their OCR fashions. The dataset is appropriate with many in style machine-learning frameworks, together with TensorFlow and PyTorch.
Potential Purposes
The discharge of the FC-AMF-OCR Dataset has the potential to impression a number of industries and functions. For instance, OCR acknowledges highway indicators and different text-based indicators in autonomous driving programs. By including extra complicated fonts and circumstances to the FC-AMF-OCR Dataset, builders might enhance textual content recognition accuracy in these environments, making autonomous automobiles safer and extra dependable. One other space the place the dataset might considerably impression digital content material accessibility is OCR know-how. OCR know-how makes printed supplies accessible to people with visible impairments. By bettering OCR fashions with the FC-AMF-OCR Dataset, builders can create extra correct text-to-speech programs that convert printed textual content into audible speech.
The dataset additionally guarantees to enhance textual content recognition accuracy in augmented actuality (AR) functions. AR depends closely on OCR know-how to overlay digital data onto real-world objects. As an example, AR functions usually show translations or further context for textual content that seems within the person’s atmosphere. The FC-AMF-OCR Dataset’s capability to deal with numerous fonts and textual content types might considerably enhance the accuracy and reliability of those AR functions, resulting in a extra seamless person expertise.
Challenges and Alternatives
Whereas the FC-AMF-OCR Dataset represents a big leap ahead, it additionally highlights the continuing challenges within the discipline of OCR. One of many essential challenges that researchers face is making certain that OCR fashions can generalize throughout a variety of textual content types and environments. Though the FC-AMF-OCR Dataset consists of many fonts and circumstances, new challenges will at all times come up as textual content types and codecs evolve. Researchers should constantly adapt their fashions to deal with new and rising textual content types successfully.
As well as, the complexity of AMF fonts presents a problem relating to computational assets. Coaching AI fashions on such a various and complicated dataset requires vital processing energy and reminiscence. Nevertheless, this problem additionally presents a chance for AI {hardware} and infrastructure developments. LightOn’s launch of the FC-AMF-OCR Dataset additionally opens the door to collaboration and innovation. By making the dataset freely obtainable to researchers and builders, LightOn encourages the broader AI neighborhood to contribute to advancing OCR know-how.
Conclusion
The discharge of the FC-AMF-OCR Dataset by LightOn is a milestone in creating OCR and AI know-how. By offering a complete and various dataset that features difficult textual content varieties resembling Amorphous Meta-Fonts, LightOn permits researchers to create extra correct and versatile OCR fashions. The dataset’s potential functions span a number of industries, from autonomous automobiles to digital accessibility, making it a worthwhile useful resource for future AI analysis.
Take a look at the Dataset and Particulars. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


