
Textual content embedding fashions have change into foundational in pure language processing (NLP). These fashions convert textual content into high-dimensional vectors that seize semantic relationships, enabling duties like doc retrieval, classification, clustering, and extra. Embeddings are particularly crucial in superior techniques reminiscent of Retrieval-Augmented Era (RAG) fashions, the place the embeddings help retrieving related paperwork. With the rising want for fashions that may deal with a number of languages and lengthy textual content sequences, transformer-based fashions have revolutionized how embeddings are generated. Nonetheless, whereas these fashions have superior capabilities, they face limitations in real-world functions, significantly in dealing with intensive multilingual information and long-context paperwork.
Textual content embedding fashions have confronted a number of challenges lately. Whereas marketed as general-purpose, a key problem is that many fashions typically require particular tuning to carry out effectively throughout varied duties. These fashions steadily battle to steadiness efficiency throughout languages and deal with lengthy textual content sequences. In multilingual functions, embedding fashions should cope with the complexity of encoding relationships throughout completely different languages, every with distinctive linguistic buildings. The problem will increase with duties that require the processing of prolonged textual content sequences, which frequently exceeds the capability of most present fashions. Furthermore, deploying such large-scale fashions, typically with billions of parameters, presents important computational price and scalability challenges, particularly when marginal enhancements don’t justify useful resource consumption.
Earlier makes an attempt to unravel these challenges have largely relied on massive language fashions (LLMs), which may exceed 7 billion parameters. These fashions have proven proficiency in dealing with varied duties in numerous languages, from textual content classification to doc retrieval. Nonetheless, regardless of their huge parameter measurement, efficiency positive aspects are minimal in comparison with encoder-only fashions, reminiscent of XLM-RoBERTa and mBERT. The complexity of those fashions additionally makes them impractical for a lot of real-world functions the place sources are restricted. Efforts to make embeddings extra environment friendly have included improvements like instruction tuning and positional encoding strategies, reminiscent of Rotary Place Embeddings (RoPE), which assist fashions course of longer textual content sequences. However, even with these developments, the fashions typically fail to satisfy the calls for of real-world, multilingual retrieval duties with the specified effectivity.
Researchers from Jina AI GmbH have launched a brand new mannequin, Jina-embeddings-v3, particularly designed to deal with the inefficiencies of earlier embedding fashions. This mannequin, which incorporates 570 million parameters, affords optimized efficiency throughout a number of duties whereas supporting longer-context paperwork of as much as 8192 tokens. The mannequin incorporates a key innovation: task-specific Low-Rank Adaptation (LoRA) adapters. These adapters enable the mannequin to effectively generate high-quality embeddings for varied duties, together with query-document retrieval, classification, clustering, and textual content matching. Jina-embeddings-v3’s means to offer particular optimizations for these duties ensures simpler dealing with of multilingual information, lengthy paperwork, and sophisticated retrieval situations, balancing efficiency and scalability.
The structure of the Jina-embeddings-v3 mannequin builds upon the widely known XLM-RoBERTa mannequin however with a number of crucial enhancements. It makes use of FlashAttention 2 to enhance computational effectivity and integrates RoPE positional embeddings to deal with long-context duties as much as 8192 tokens. One of many mannequin’s most modern options is Matryoshka Illustration Studying, which permits customers to truncate embeddings with out compromising efficiency. This methodology gives flexibility in selecting completely different embedding sizes, reminiscent of lowering a 1024-dimensional embedding to only 16 or 32 dimensions, optimizing the trade-off between area effectivity and activity efficiency. With the addition of task-specific LoRA adapters, which account for lower than 3% of the overall parameters, the mannequin can dynamically adapt to completely different duties reminiscent of classification and retrieval. By freezing the unique mannequin weights, the researchers have ensured that coaching these adapters stays extremely environment friendly, utilizing solely a fraction of the reminiscence required by conventional fashions. This effectivity makes it sensible for deployment in real-world settings.
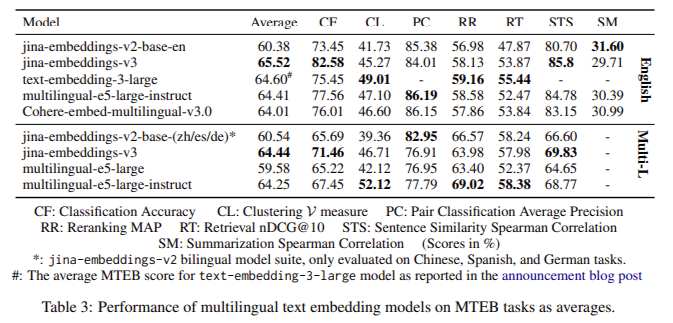
The Jina-embeddings-v3 mannequin has proven exceptional efficiency enhancements throughout a number of benchmark assessments. The mannequin outperformed opponents like OpenAI’s proprietary fashions and Cohere’s multilingual embeddings in multilingual evaluations, significantly in English duties. The jina-embeddings-v3 mannequin demonstrated superior ends in classification accuracy (82.58%) and sentence similarity (85.8%) on the MTEB benchmark, outperforming a lot bigger fashions reminiscent of e5-mistral-7b-instruct, which has over 7 billion parameters however solely reveals a marginal 1% enchancment on sure duties. Jina-embeddings-v3 achieved glorious ends in multilingual duties, surpassing multilingual-e5-large-instruct throughout all duties regardless of its considerably smaller measurement. Its means to carry out effectively in multilingual and long-context retrieval duties whereas requiring fewer computational sources makes it extremely environment friendly and cost-effective, particularly for quick, on-edge computing functions.

In conclusion, Jina-embeddings-v3 affords a scalable and environment friendly answer to the long-standing challenges textual content embedding fashions face in multilingual and long-context duties. Integrating LoRA adapters, Matryoshka Illustration Studying, and different superior methods ensures that the mannequin can deal with varied capabilities with out the extreme computational burden seen in fashions with billions of parameters. The researchers have created a sensible and high-performing mannequin that outperforms many bigger fashions and units a brand new normal for embedding effectivity. Introducing these improvements gives a transparent path ahead for additional developments in multilingual and long-text retrieval, making jina-embeddings-v3 a worthwhile software in NLP.
Try the Paper and Mannequin Card on HF. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


