
Deep reinforcement studying (DRL) faces a crucial problem as a result of instability attributable to “churn” throughout coaching. Churn refers to unpredictable modifications within the output of neural networks for states that aren’t included within the coaching batch. This downside is especially troublesome in reinforcement studying (RL) due to its inherently non-stationary nature, the place insurance policies and worth capabilities repeatedly evolve as new information is launched. Churn results in vital instabilities in studying, inflicting erratic updates to each worth estimates and insurance policies, which may end up in inefficient coaching, suboptimal efficiency, and even catastrophic failures. Addressing this problem is crucial for enhancing the reliability of DRL in complicated environments, enabling the event of extra strong AI programs in real-world purposes like autonomous driving, robotics, and healthcare.
Present strategies to mitigate instability in DRL, reminiscent of value-based algorithms (e.g., DoubleDQN) and policy-based strategies (e.g., Proximal Coverage Optimization, PPO), purpose to stabilize studying by way of strategies like overestimation bias management and belief area enforcement. Nevertheless, these approaches fail to handle churn successfully. As an illustration, DoubleDQN suffers from grasping motion deviations on account of modifications in worth estimates, whereas PPO can silently violate its belief area on account of coverage churn. These present strategies overlook the compounded impact of churn between worth and coverage updates, leading to diminished pattern effectivity and poor efficiency, particularly in large-scale decision-making duties.
Researchers from Université de Montréal introduce Churn Approximated ReductIoN (CHAIN). This technique particularly targets the discount of worth and coverage churn by introducing regularization losses throughout coaching. CHAIN reduces the undesirable modifications in community outputs for states not included within the present batch, successfully controlling churn throughout completely different DRL settings. By minimizing the churn impact, this methodology improves the soundness of each value-based and policy-based RL algorithms. The innovation lies within the methodology’s simplicity and its means to be simply built-in into most present DRL algorithms with minimal code modifications. The power to regulate churn results in extra steady studying and higher pattern effectivity throughout a wide range of RL environments.
The CHAIN methodology introduces two most important regularization phrases: the worth churn discount loss (L_QC) and the coverage churn discount loss (L_PC). These phrases are computed utilizing a reference batch of information and cut back modifications within the Q-network’s worth outputs and coverage community’s motion outputs, respectively. This discount is achieved by evaluating present outputs with these from the earlier iteration of the community. The strategy is evaluated utilizing a number of DRL benchmarks, together with MinAtar, OpenAI MuJoCo, DeepMind Management Suite, and offline datasets reminiscent of D4RL. The regularization is designed to be light-weight and is utilized alongside the usual loss capabilities utilized in DRL coaching, making it extremely versatile for a variety of algorithms, together with DoubleDQN, PPO, and SAC.
CHAIN confirmed vital enhancements in each lowering churn and enhancing studying efficiency throughout numerous RL environments. In duties like MinAtar’s Breakout, integrating CHAIN with DoubleDQN led to a marked discount in worth churn, leading to improved pattern effectivity and higher general efficiency in comparison with baseline strategies. Equally, in steady management environments reminiscent of MuJoCo’s Ant-v4 and HalfCheetah-v4, making use of CHAIN to PPO improved stability and ultimate returns, outperforming normal PPO configurations. These findings show that CHAIN enhances the soundness of coaching dynamics, resulting in extra dependable and environment friendly studying throughout a spread of reinforcement studying eventualities, with constant efficiency positive factors in each on-line and offline RL settings.
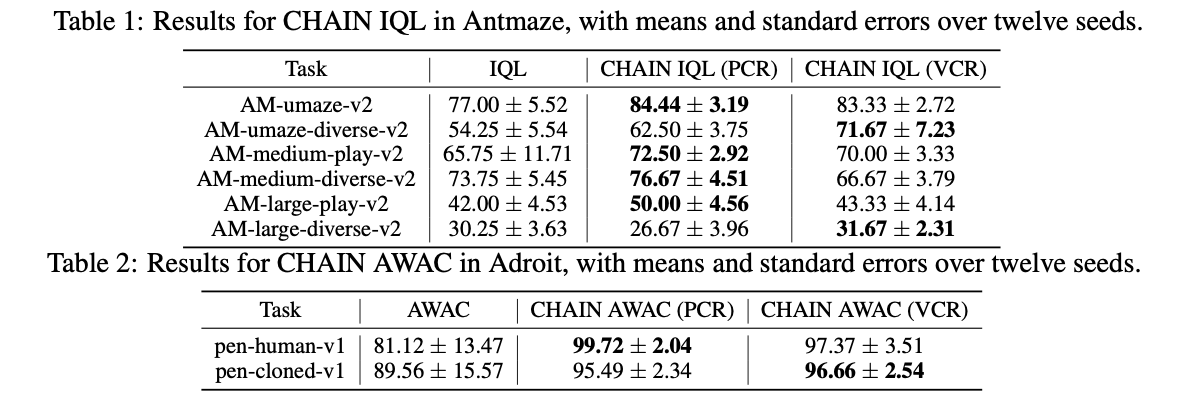
The CHAIN methodology addresses a basic problem in DRL by lowering the destabilizing impact of churn. By controlling each worth and coverage churn, the method ensures extra steady updates throughout coaching, resulting in improved pattern effectivity and higher ultimate efficiency throughout numerous RL duties. CHAIN’s means to be simply integrated into present algorithms, with minimal modifications makes it a sensible answer to a crucial downside in reinforcement studying. This innovation has the potential to considerably enhance the robustness and scalability of DRL programs, significantly in real-world, large-scale environments.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


