
Prior analysis on Massive Language Fashions (LLMs) demonstrated important developments in fluency and accuracy throughout varied duties, influencing sectors like healthcare and training. This progress sparked investigations into LLMs’ language understanding capabilities and related dangers. Hallucinations, outlined as believable however incorrect data generated by fashions, emerged as a central concern. Research explored whether or not these errors may very well be eradicated or required administration, recognizing them as an intrinsic problem of LLMs.
Current developments in LLMs have revolutionized pure language processing, but the persistent problem of hallucinations necessitates a deeper examination of their basic nature and implications. Drawing from computational principle and Gödel’s First Incompleteness Theorem, it introduces the idea of “Structural Hallucinations.” This novel perspective posits that each stage of the LLM course of has a non-zero chance of manufacturing hallucinations, emphasizing the necessity for a brand new method to managing these inherent errors in language fashions.
This examine challenges the traditional view of hallucinations in LLMs, presenting them as inevitable options quite than occasional errors. It argues that these inaccuracies stem from the elemental mathematical and logical underpinnings of LLMs. By demonstrating the non-zero chance of errors at each stage of the LLM course of, the analysis requires a paradigm shift in approaching language mannequin limitations.
United We Care Researchers suggest a complete methodology to deal with hallucinations in LLMs. The method begins with enhanced data retrieval strategies, similar to Chain-of-Thought prompting and Retrieval-Augmented Technology, to extract related information from the mannequin’s database. This course of is adopted by enter augmentation, combining retrieved paperwork with the unique question to supply grounded context. The methodology then employs Self-Consistency strategies throughout output technology, permitting the mannequin to supply and choose essentially the most applicable response from a number of choices.
Submit-generation strategies kind a vital a part of the technique, together with Uncertainty Quantification and Faithfulness Clarification Technology. These strategies help in evaluating the correctness of generated responses and figuring out potential hallucinations. The usage of Shapley values to measure the faithfulness of explanations enhances output transparency and trustworthiness. Regardless of these complete measures, the researchers acknowledge that hallucinations stay an intrinsic facet of LLMs, emphasizing the necessity for continued growth in managing these inherent limitations.
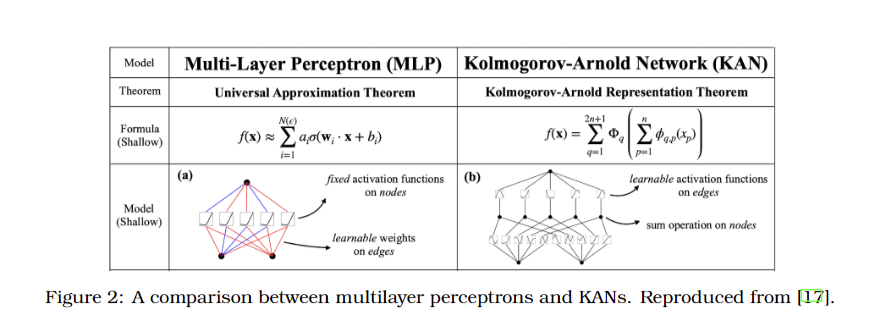
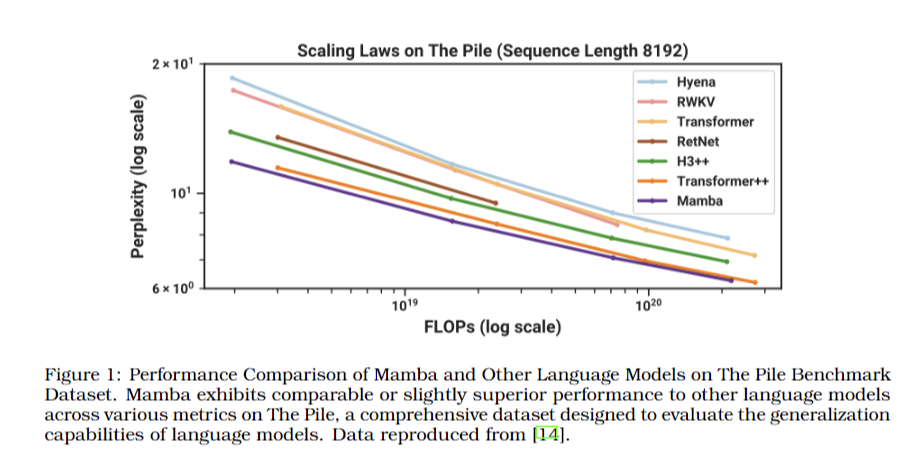
The examine contends that hallucinations in LLMs are intrinsic and mathematically sure, not merely occasional errors. Each stage of the LLM course of carries a non-zero chance of manufacturing hallucinations, making their full elimination unattainable by means of architectural or dataset enhancements. Architectural developments, similar to transformers and different fashions like KAN, Mamba, and Jamba, can enhance coaching however don’t deal with the elemental downside of hallucinations. The paper argues that the efficiency of LLMs, together with their skill to retrieve and generate data precisely, is inherently restricted by their structural design. Though particular numerical outcomes aren’t offered, the examine emphasizes that enhancements in structure or coaching information can’t alter the probabilistic nature of hallucinations. This analysis underscores the necessity for a practical understanding of LLM capabilities and limitations.
In conclusion, the examine asserts that hallucinations in LLMs are intrinsic and ineliminable, persisting regardless of developments in coaching, structure, or fact-checking mechanisms. Each stage of LLM output technology is prone to hallucinations, highlighting the systemic nature of this situation. Drawing on computational principle ideas, the paper argues that sure LLM-related issues are undecidable, reinforcing the impossibility of full accuracy. The authors problem prevailing beliefs about mitigating hallucinations, calling for sensible expectations and a shift in direction of managing, quite than eliminating, these inherent limitations in LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Expertise (IIT), Kharagpur. With a robust ardour for Knowledge Science, he’s notably within the numerous purposes of synthetic intelligence throughout varied domains. Shoaib is pushed by a need to discover the newest technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sphere of AI


