
Synthetic Intelligence (AI) and Machine Studying (ML) have been transformative in quite a few fields, however a major problem stays within the reproducibility of experiments. Researchers often depend on beforehand revealed work to validate or lengthen their findings. This course of usually entails operating advanced code from analysis repositories. Nevertheless, organising these repositories, configuring the surroundings, and resolving numerous technical points, comparable to outdated dependencies and bugs, are time-consuming and require experience. As AI continues to evolve, researchers are searching for methods to automate these duties to expedite scientific discovery.
One of many vital issues in reproducing experiments from analysis repositories is that these repositories are sometimes not well-maintained. Poor documentation and outdated code make it tough for different researchers to run the experiments as supposed. This situation is additional sophisticated by the assorted platforms and instruments required to run completely different experiments. Researchers spend a substantial period of time putting in dependencies, troubleshooting compatibility points, and configuring the surroundings to satisfy the precise wants of every experiment. Addressing this drawback might considerably enhance the tempo at which discoveries are validated and expanded upon within the scientific neighborhood.
Traditionally, strategies for dealing with the setup and execution of analysis repositories have been largely handbook. Researchers should possess a deep understanding of the codebase and the precise area of research to resolve points arising throughout experiment replication. Whereas some instruments assist handle dependencies or troubleshoot errors, these are restricted in scope and effectiveness. Latest developments in massive language fashions (LLMs) have proven potential in automating this course of, comparable to producing code or instructions to resolve points. Nevertheless, there’s at present no strong technique for evaluating LLMs’ potential to deal with real-world analysis repositories’ advanced and sometimes incomplete nature.
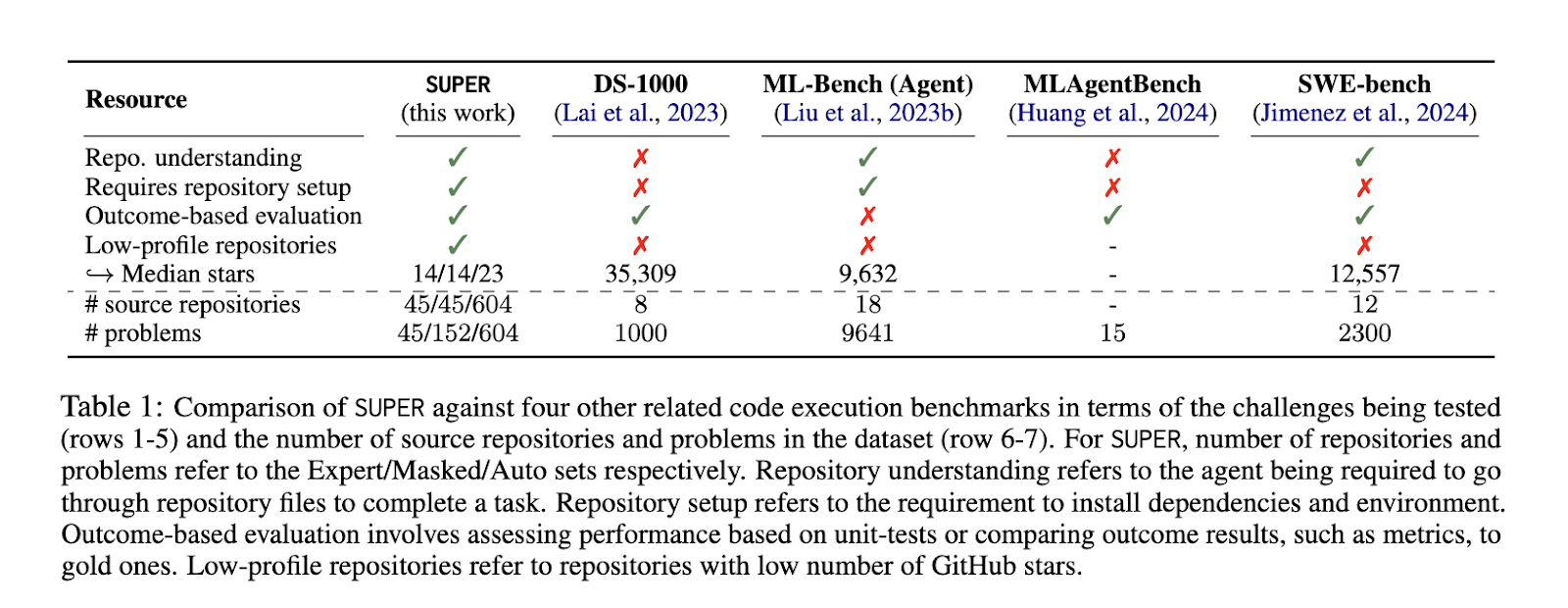
Researchers from the Allen Institute for AI and the College of Washington launched SUPER—a benchmark designed to judge the flexibility of LLMs to arrange and execute duties from analysis repositories. In contrast to different instruments specializing in in style and well-maintained repositories, SUPER emphasizes real-world challenges researchers face utilizing lower-profile repositories that aren’t at all times well-documented. The benchmark contains quite a lot of situations that mimic the varieties of obstacles researchers often encounter. By testing LLMs on these duties, SUPER gives a complete framework for assessing how effectively these fashions can assist analysis duties that contain code execution and troubleshooting.
The SUPER benchmark is split into three distinct units:
- The Professional set contains 45 manually curated issues primarily based on actual analysis duties.
- The Masked set breaks down these issues into 152 smaller challenges specializing in particular technical points like configuring a coach or resolving runtime exceptions.
- The Auto set consists of 604 mechanically generated duties designed for large-scale growth and fine-tuning of fashions.
Every drawback set introduces completely different challenges, from putting in dependencies and configuring hyperparameters to troubleshooting errors and reporting metrics. The benchmark assesses activity success, partial progress, and the accuracy of the generated options, providing an in depth analysis of the mannequin’s capabilities.
The efficiency analysis of LLMs on the SUPER benchmark reveals important limitations in present fashions. Essentially the most superior mannequin examined, GPT-4o, efficiently solved solely 16.3% of the end-to-end duties within the Professional set and 46.1% of the sub-problems within the Masked set. These outcomes spotlight the difficulties in automating the setup and execution of analysis experiments, as even the best-performing fashions wrestle with many duties. Moreover, open-source fashions lag considerably behind, finishing a smaller proportion of duties. The Auto set confirmed related efficiency patterns, suggesting that the challenges noticed within the curated units are constant throughout numerous issues. The analysis additionally highlighted that brokers carry out higher on particular duties, comparable to resolving dependency conflicts or addressing runtime errors, than on extra advanced duties, like configuring new datasets or modifying coaching scripts.
In conclusion, the SUPER benchmark sheds gentle on the present limitations of LLMs in automating analysis duties. Regardless of latest developments, there’s nonetheless a substantial hole between the capabilities of those fashions and the advanced wants of researchers working with real-world repositories. The outcomes from the SUPER benchmark point out that whereas LLMs could be helpful in resolving well-defined technical points, they don’t seem to be but able to dealing with the complete vary of duties required for the whole automation of analysis experiments. This benchmark gives a priceless useful resource for the AI neighborhood to measure and enhance upon, providing a path ahead for the event of extra subtle instruments that would sooner or later absolutely assist scientific analysis.
Take a look at the Paper, GitHub, and HF Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


