
Massive language fashions (LLMs) have gained vital consideration within the discipline of synthetic intelligence, primarily on account of their potential to mimic human data via intensive datasets. The present methodologies for coaching these fashions closely depend on imitation studying, significantly subsequent token prediction utilizing most chance estimation (MLE) throughout pretraining and supervised fine-tuning phases. Nonetheless, this method faces a number of challenges, together with compounding errors in autoregressive fashions, publicity bias, and distribution shifts throughout iterative mannequin software. These points develop into extra pronounced with longer sequences, doubtlessly resulting in degraded efficiency and misalignment with human intent. As the sector progresses, there’s a rising want to handle these challenges and develop simpler strategies for coaching and aligning LLMs with human preferences and intentions.
Present makes an attempt to handle the challenges in language mannequin coaching have primarily centered on two fundamental approaches: behavioral cloning (BC) and inverse reinforcement studying (IRL). BC, analogous to supervised fine-tuning through MLE, straight mimics professional demonstrations however suffers from compounding errors and requires intensive information protection. IRL, then again, collectively infers the coverage and reward perform, doubtlessly overcoming BC’s limitations by using further setting interactions. Latest IRL strategies have included game-theoretic approaches, entropy regularization, and varied optimization strategies to enhance stability and scalability. Within the context of language modeling, some researchers have explored adversarial coaching strategies, resembling SeqGAN, as alternate options to MLE. Nonetheless, these approaches have proven restricted success, working successfully solely in particular temperature regimes. Regardless of these efforts, the sector continues to hunt extra sturdy and scalable options for coaching and aligning massive language fashions.
DeepMind researchers suggest an in-depth investigation of RL-based optimization, significantly specializing in the distribution matching perspective of IRL, for fine-tuning massive language fashions. This method goals to supply an efficient different to plain MLE. The examine encompasses each adversarial and non-adversarial strategies, in addition to offline and on-line strategies. A key innovation is the extension of inverse tender Q-learning to determine a principled reference to classical habits cloning or MLE. The analysis evaluates fashions starting from 250M to 3B parameters, together with encoder-decoder T5 and decoder-only PaLM2 architectures. By inspecting job efficiency and technology range, the examine seeks to display the advantages of IRL over habits cloning in imitation studying for language fashions. Along with that, the analysis explores the potential of IRL-obtained reward features to bridge the hole with later levels of RLHF.
The proposed methodology introduces a novel method to language mannequin fine-tuning by reformulating inverse tender Q-learning as a temporal distinction regularized extension of MLE. This methodology bridges the hole between MLE and algorithms that exploit the sequential nature of language technology.
The method fashions language technology as a sequential decision-making drawback, the place producing the following token is conditioned on the beforehand generated sequence. The researchers deal with minimizing the divergence between the γ-discounted state-action distribution of the coverage and that of the professional coverage, mixed with a weighted causal entropy time period.
The formulation makes use of the χ2-divergence and rescales the worth perform, ensuing within the IQLearn goal:
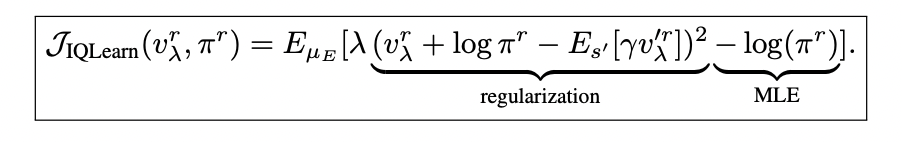
This goal consists of two fundamental parts:
1. A regularization time period that {couples} the realized coverage to a price perform, favoring insurance policies the place the log chance of actions matches the distinction in state values.
2. An MLE time period that maintains the connection to conventional language mannequin coaching.
Importantly, this formulation permits for annealing of the regularization time period, offering flexibility in balancing between normal MLE (λ = 0) and stronger regularization. This method allows offline coaching utilizing solely professional samples, doubtlessly enhancing computational effectivity in large-scale language mannequin fine-tuning.
The researchers carried out intensive experiments to judge the effectiveness of IRL strategies in comparison with MLE for fine-tuning massive language fashions. Their outcomes display a number of key findings:
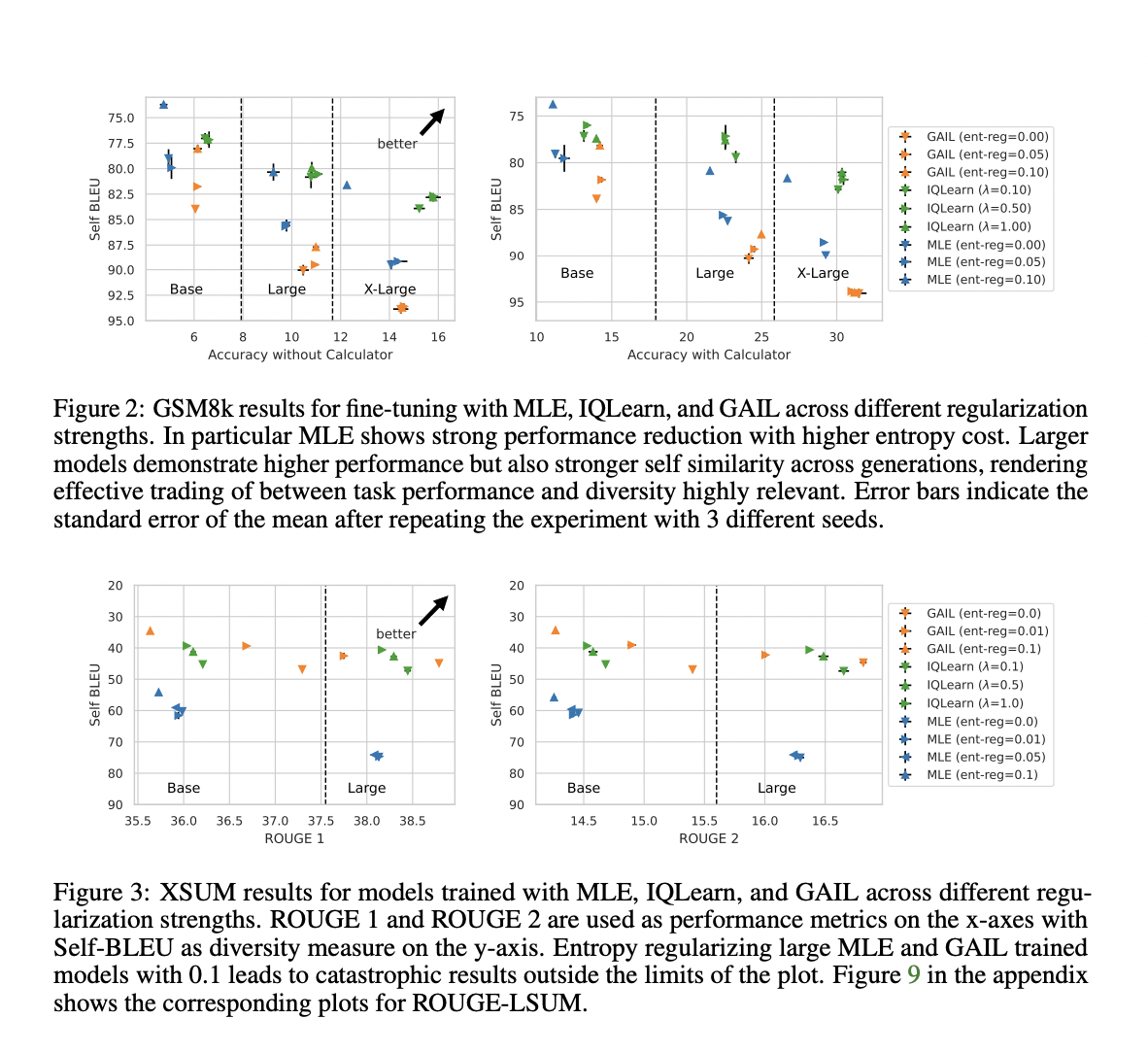
1. Efficiency enhancements: IRL strategies, significantly IQLearn, confirmed small however notable features in job efficiency throughout varied benchmarks, together with XSUM, GSM8k, TLDR, and WMT22. These enhancements have been particularly pronounced for math and reasoning duties.
2. Variety enhancement: IQLearn persistently produced extra various mannequin generations in comparison with MLE, as measured by decrease Self-BLEU scores. This means a greater trade-off between job efficiency and output range.
3. Mannequin scalability: The advantages of IRL strategies have been noticed throughout completely different mannequin sizes and architectures, together with T5 (base, massive, and xl) and PaLM2 fashions.
4. Temperature sensitivity: For PaLM2 fashions, IQLearn achieved larger efficiency in low-temperature sampling regimes throughout all examined duties, suggesting improved stability in technology high quality.
5. Diminished beam search dependency: IQLearn demonstrated the power to cut back reliance on beam search throughout inference whereas sustaining efficiency, doubtlessly providing computational effectivity features.
6. GAIL efficiency: Whereas stabilized for T5 fashions, GAIL proved difficult to implement successfully for PaLM2 fashions, highlighting the robustness of the IQLearn method.
These outcomes counsel that IRL strategies, significantly IQLearn, present a scalable and efficient different to MLE for fine-tuning massive language fashions, providing enhancements in each job efficiency and technology range throughout a spread of duties and mannequin architectures.
This paper investigates the potential of IRL algorithms for language mannequin fine-tuning, specializing in efficiency, range, and computational effectivity. The researchers introduce a reformulated IQLearn algorithm, enabling a balanced method between normal supervised fine-tuning and superior IRL strategies. Experiments reveal vital enhancements within the trade-off between job efficiency and technology range utilizing IRL. The examine majorly demonstrates that computationally environment friendly offline IRL achieves substantial efficiency features over MLE-based optimization with out requiring on-line sampling. Additionally, the correlation evaluation between IRL-extracted rewards and efficiency metrics suggests the potential for creating extra correct and sturdy reward features in language modeling, paving the best way for improved language mannequin coaching and alignment.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


