Generative modeling, notably diffusion fashions (DMs), has considerably superior in recent times, enjoying a vital position in producing high-quality photographs, movies, and audio. Diffusion fashions function by introducing noise into the information after which steadily reversing this course of to generate information from noise. They’ve demonstrated important potential in varied functions, from creating visible art work to simulating scientific information. Nonetheless, regardless of their spectacular generative capabilities, diffusion fashions undergo from gradual inference speeds and excessive computational prices, which limits their sensible deployment, notably on gadgets with restricted assets like smartphones.
One of many major challenges in deploying diffusion fashions is their want for in depth computational assets and time throughout the era course of. These fashions depend on iterative steps to estimate and scale back noise within the information, usually requiring hundreds of iterations. This makes them inefficient for real-time functions, the place pace and computational effectivity are important. Moreover, storing the massive datasets wanted to coach these fashions provides one other layer of complexity, making it tough for a lot of organizations to make the most of diffusion fashions successfully. The issue turns into much more urgent as industries search sooner and extra resource-efficient fashions for real-world functions.
Present strategies to deal with the inefficiencies of diffusion fashions contain optimizing the variety of denoising steps and the structure of the neural networks used. Methods like step discount, quantization, and pruning are generally utilized to cut back the time required to generate information with out compromising output high quality. For instance, decreasing the variety of steps throughout the noise discount course of can result in sooner outcomes, whereas quantization helps decrease the precision necessities of the mannequin, saving computational assets. Though these approaches enhance effectivity to some extent, they usually end in trade-offs regarding mannequin efficiency, and there may be nonetheless a major want for options that may present each pace and high-quality outcomes.
Researchers from the Harbin Institute of Expertise and Illinois Institute of Expertise have launched a brand new answer often known as Information-Free Data Distillation for Diffusion Fashions (DKDM). This method introduces a novel methodology for distilling the capabilities of enormous, pretrained diffusion fashions into smaller, extra environment friendly architectures with out counting on the unique coaching information. That is notably helpful when the unique datasets are both unavailable or too massive to retailer. The DKDM methodology permits for compressing diffusion fashions by transferring their data to sooner variations, thereby addressing the problem of gradual inference speeds whereas sustaining mannequin accuracy. The novelty of DKDM lies in its means to work with out entry to the supply information, making it a groundbreaking method within the realm of information distillation.
The DKDM methodology depends on a dynamic, iterative distillation course of, which successfully generates artificial denoising information by pretrained diffusion fashions, often known as “instructor” fashions. This artificial information is then used to coach “pupil” fashions, that are smaller and sooner than the instructor fashions. The method optimizes the scholar fashions utilizing a specifically designed goal operate that carefully mirrors the optimization targets of normal diffusion fashions. The artificial information created by the instructor fashions simulates the noisy information usually produced throughout the reverse diffusion course of, permitting the scholar fashions to study effectively with out entry to the unique datasets. By using this methodology, researchers can considerably scale back the computational load required for coaching new fashions whereas nonetheless guaranteeing that the scholar fashions retain the excessive generative high quality of their instructor counterparts.
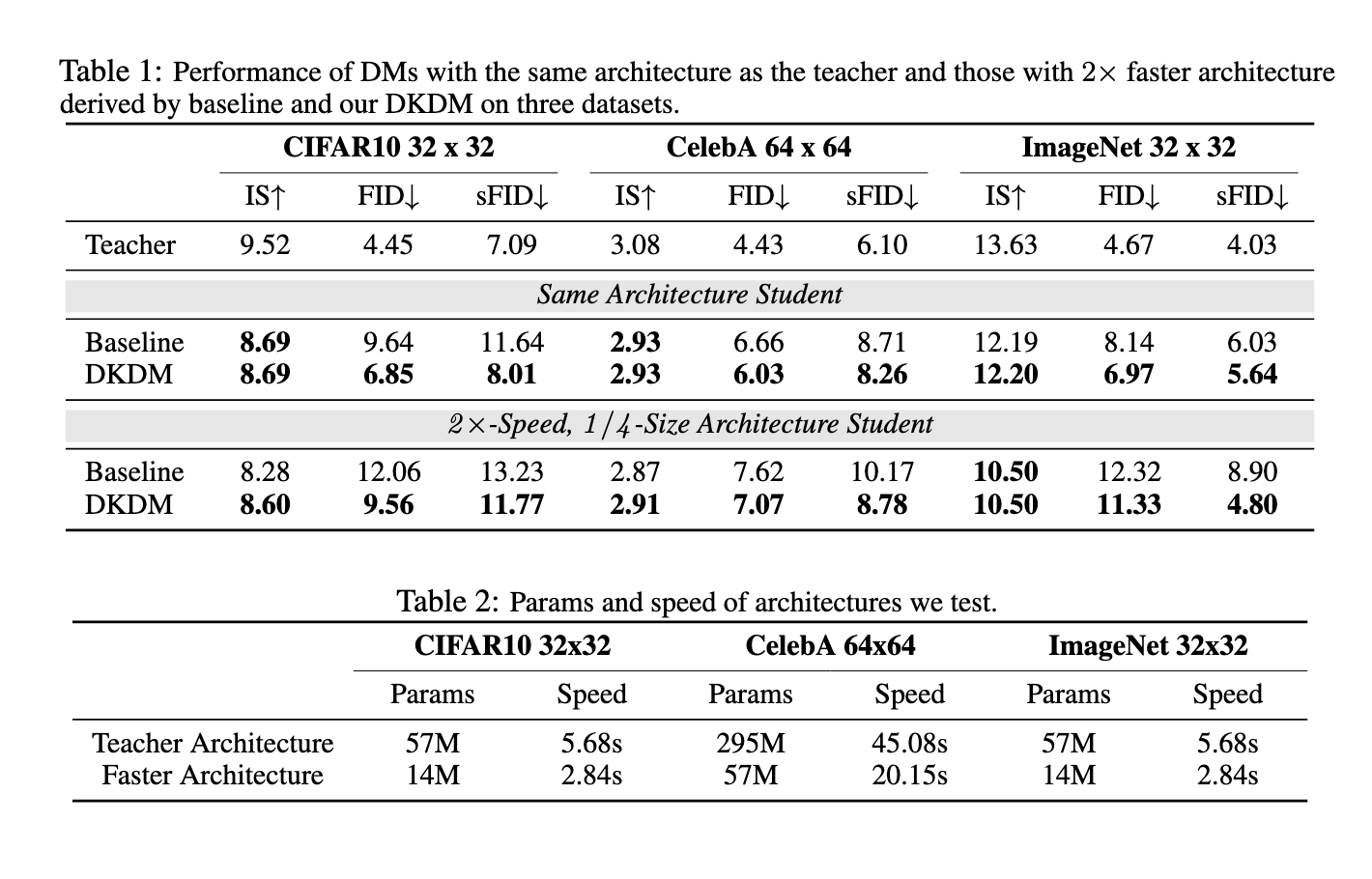
In experiments performed by the analysis workforce, the DKDM method demonstrated substantial efficiency enhancements. Particularly, fashions skilled utilizing DKDM achieved era speeds twice as quick as baseline diffusion fashions whereas sustaining almost the identical stage of efficiency. As an illustration, when utilized to the CIFAR-10 dataset, the DKDM-optimized pupil fashions achieved an Inception Rating (IS) of 8.60 and a Fréchet Inception Distance (FID) rating of 9.56, in comparison with the baseline scores of 8.28 IS and 12.06 FID. On the CelebA dataset, DKDM-trained fashions achieved a 2× pace enchancment over baseline fashions with minimal affect on high quality, as evidenced by an almost similar IS of two.91. Moreover, DKDM’s versatile structure permits it to combine seamlessly with different acceleration methods, resembling quantization and pruning, additional enhancing its practicality for real-world functions. Notably, these enhancements have been achieved with out compromising the generative high quality of the output, as demonstrated by the experiments on a number of datasets.
In conclusion, the DKDM methodology gives a sensible and environment friendly answer to the issue of gradual and resource-intensive diffusion fashions. By leveraging data-free data distillation, the researchers from the Harbin Institute of Expertise and Illinois Institute of Expertise have developed a way that enables for sooner, extra environment friendly diffusion fashions with out compromising on generative high quality. This innovation provides important potential for the way forward for generative modeling, notably in areas the place computational assets and information storage are restricted. The DKDM method efficiently addresses the important thing challenges within the area and paves the way in which for extra environment friendly deployment of diffusion fashions in sensible functions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.