
Textual content-to-image diffusion fashions have made important strides in producing complicated and devoted pictures from enter situations. Amongst these, Diffusion Transformers Fashions (DiTs) have emerged as notably highly effective, with OpenAI’s SoRA being a notable utility. DiTs, constructed by stacking a number of transformer blocks, make the most of the scaling properties of transformers to attain enhanced efficiency via versatile parameter enlargement. Whereas DiTs outperform UNet-based diffusion fashions in picture high quality, they face deployment challenges because of their massive parameter depend and excessive computational complexity. As an example, producing a 256 × 256 decision picture utilizing the DiT XL/2 mannequin requires over 17 seconds and 105 Gflops on an NVIDIA A100 GPU. This computational demand makes deploying DiTs on edge gadgets with restricted assets impractical, prompting researchers to discover environment friendly deployment strategies, notably via mannequin quantization.
VQ4DiT: Environment friendly Publish-Coaching Vector Quantization for Diffusion Transformers
Textual content-to-image diffusion fashions have made important strides in producing complicated and devoted pictures from enter situations. Amongst these, Diffusion Transformers Fashions (DiTs) have emerged as notably highly effective, with OpenAI’s SoRA being a notable utility. DiTs, constructed by stacking a number of transformer blocks, make the most of the scaling properties of transformers to attain enhanced efficiency via versatile parameter enlargement. Whereas DiTs outperform UNet-based diffusion fashions in picture high quality, they face deployment challenges because of their massive parameter depend and excessive computational complexity. As an example, producing a 256 × 256 decision picture utilizing the DiT XL/2 mannequin requires over 17 seconds and 105 Gflops on an NVIDIA A100 GPU. This computational demand makes deploying DiTs on edge gadgets with restricted assets impractical, prompting researchers to discover environment friendly deployment strategies, notably via mannequin quantization.
Prior makes an attempt to handle the deployment challenges of diffusion fashions have primarily centered on mannequin quantization strategies. Publish-training quantization (PTQ) has been extensively used because of its speedy implementation with out intensive fine-tuning. Vector quantization (VQ) has proven promise in compressing CNN fashions to extraordinarily low bit-widths. Nevertheless, these strategies face limitations when utilized to DiTs. PTQ strategies considerably scale back mannequin accuracy at very low bit-widths, akin to 2-bit quantization. Conventional VQ strategies solely calibrate the codebook with out adjusting assignments, resulting in suboptimal outcomes because of incorrect task of weight sub-vectors and inconsistent gradients to the codebook.
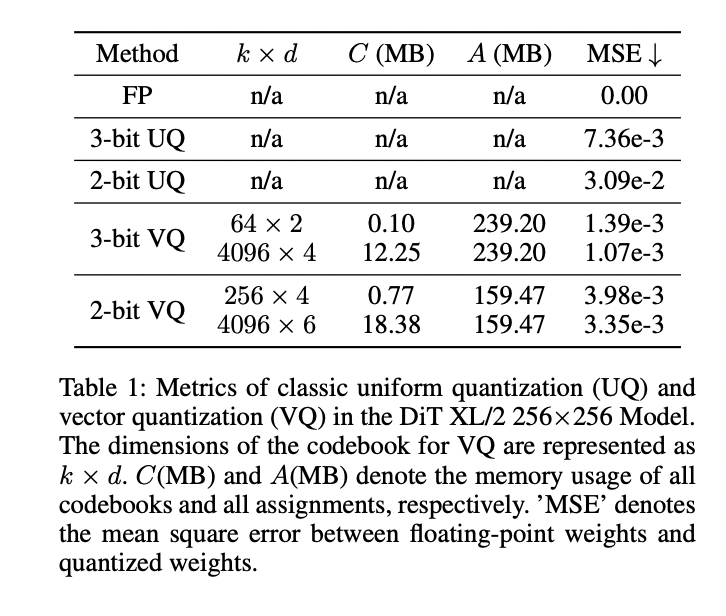
The applying of basic uniform quantization (UQ) and VQ to the DiT XL/2 mannequin reveals important challenges in reaching optimum efficiency at extraordinarily low bit-widths. Whereas VQ outperforms UQ by way of quantization error, it nonetheless faces points with efficiency degradation, particularly at 2-bit and 3-bit quantization ranges. The trade-off between codebook dimension, reminiscence utilization, and quantization error presents a posh optimization downside. Superb-tuning quantized DiTs on massive datasets like ImageNet is computationally intensive and time-consuming. Additionally, the buildup of quantization errors in these large-scale fashions results in suboptimal outcomes, even after fine-tuning. The important thing challenge lies within the conflicting gradients for sub-vectors with the identical task, hindering correct codeword updates.
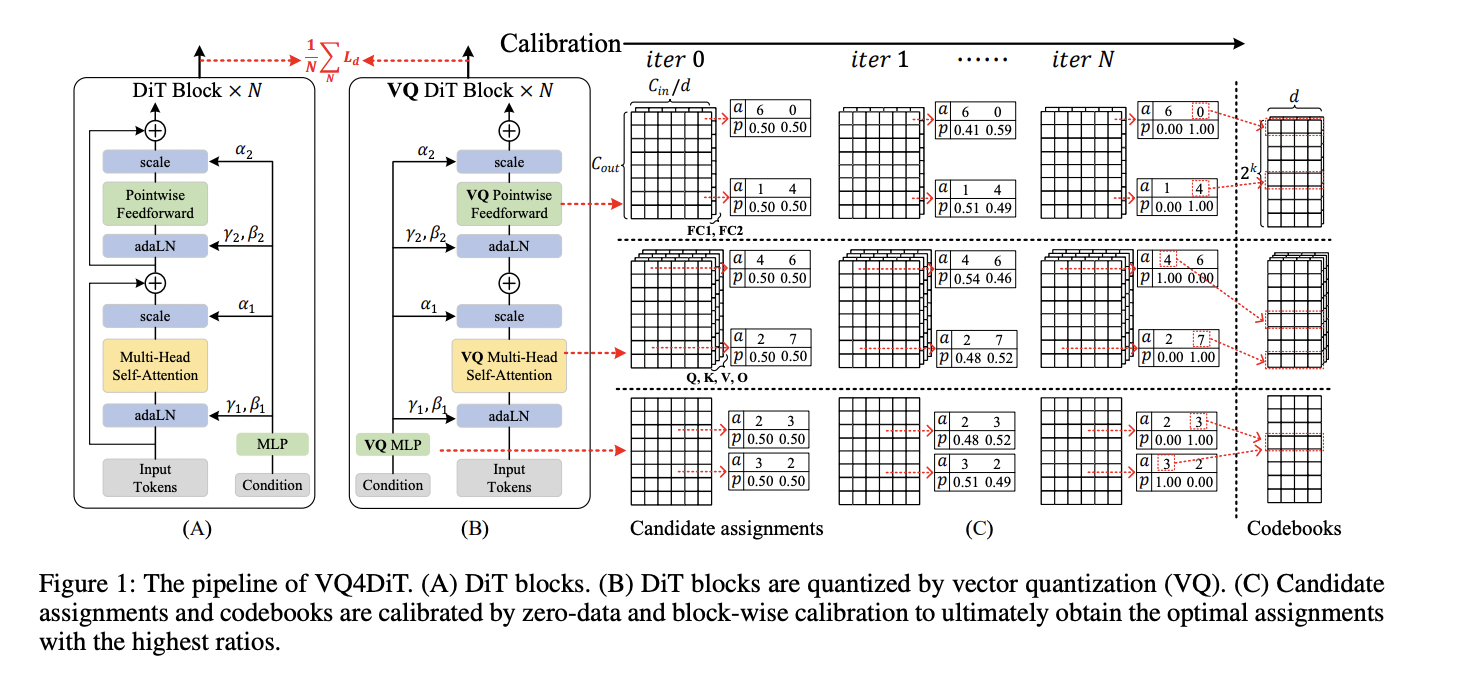
To beat the constraints of current quantization strategies, researchers from Zhejiang College and vivo Cell Communication Co., Ltd have developed Environment friendly Publish-Coaching Vector Quantization for Diffusion Transformers (VQ4DiT). This sturdy method effectively and precisely vector quantizes DiTs with out requiring a calibration dataset. VQ4DiT decomposes the weights of every layer right into a codebook and candidate task units, initializing every candidate task with an equal ratio. It then employs a zero-data and block-wise calibration technique to concurrently calibrate codebooks and candidate task units. This technique minimizes the imply sq. error between the outputs of floating-point and quantized fashions at every timestep and DiT block, making certain the quantized mannequin maintains efficiency much like its floating-point counterpart whereas avoiding calibration collapse because of cumulative quantization errors.

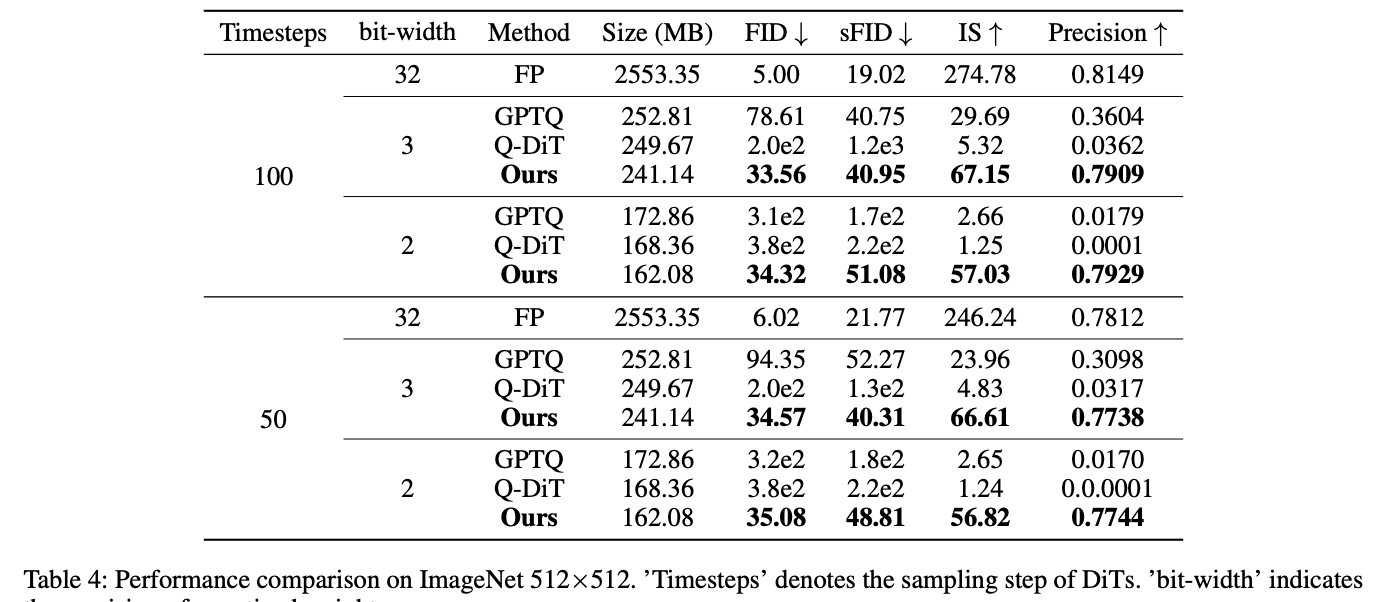
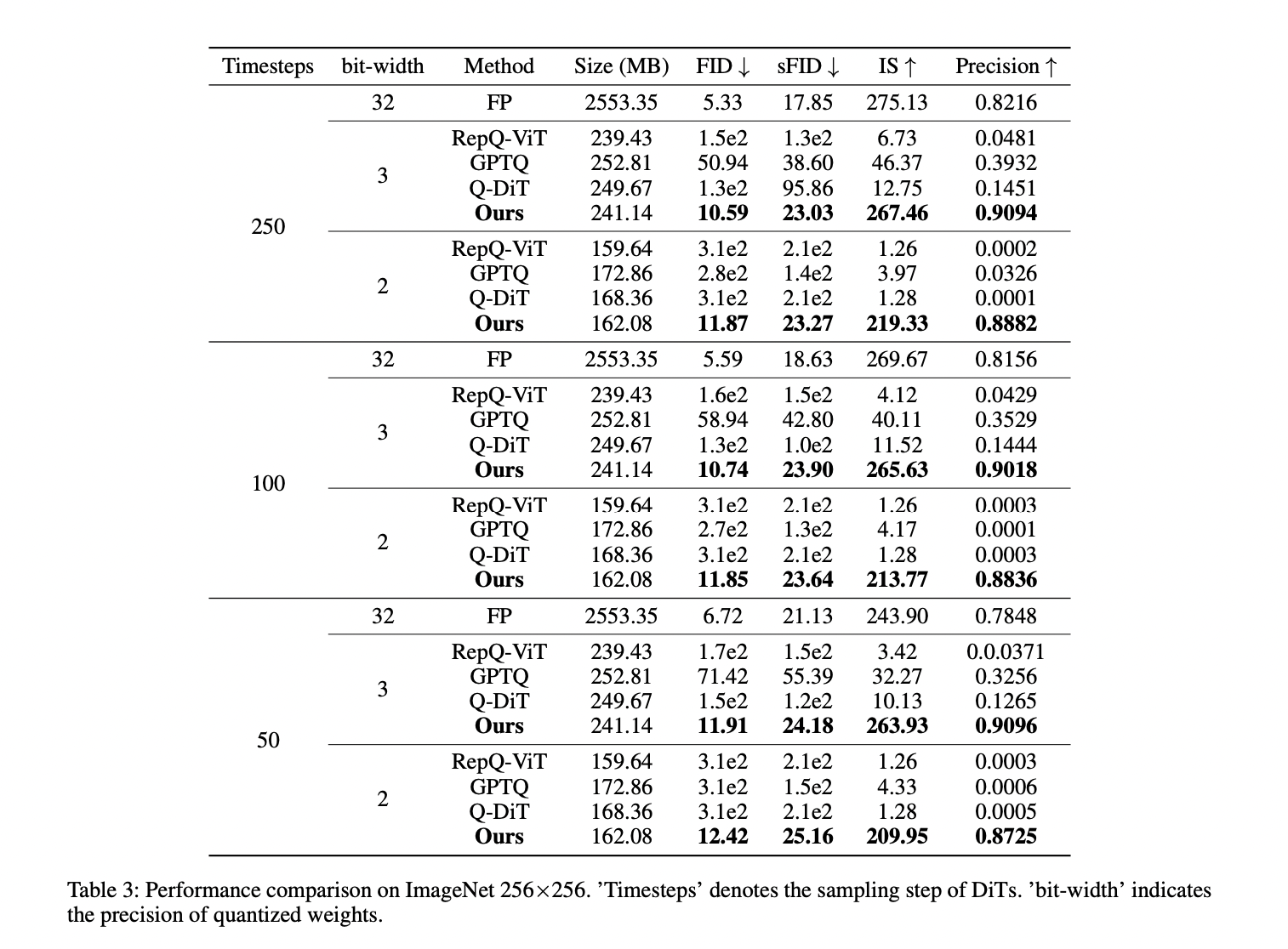
The DiT XL/2 mannequin, quantized utilizing VQ4DiT, demonstrates superior efficiency on ImageNet 256×256 and 512×512 datasets throughout varied pattern timesteps and weight bit-widths. At 256×256 decision, VQ4DiT outperforms different strategies, together with RepQ-ViT, GPTQ, and Q-DiT, particularly underneath 3-bit quantization. VQ4DiT maintains efficiency near the floating-point mannequin, with minimal will increase in FID and reduces in IS. At 2-bit quantization, the place different algorithms collapse, VQ4DiT continues to generate high-quality pictures with solely a slight lower in precision. Related outcomes are noticed at 512×512 decision, indicating VQ4DiT’s functionality to supply high-quality, high-resolution pictures with minimal reminiscence utilization, making it superb for deploying DiTs on edge gadgets.
This research presents VQ4DiT, a novel and sturdy post-training vector quantization technique for DiTs, that addresses key challenges in environment friendly quantization. By balancing codebook dimension with quantization error and resolving inconsistent gradient instructions, VQ4DiT achieves optimum assignments and codebooks via a zero-data and block-wise calibration course of. This modern method calculates candidate task units for every sub-vector and progressively calibrates every layer’s codebook and assignments. Experimental outcomes display VQ4DiT’s effectiveness in quantizing DiT weights to 2-bit precision whereas preserving high-quality picture era capabilities. This development considerably enhances the potential for deploying DiTs on resource-constrained edge gadgets, opening new prospects for environment friendly, high-quality picture era in varied functions.
Prior makes an attempt to handle the deployment challenges of diffusion fashions have primarily centered on mannequin quantization strategies. Publish-training quantization (PTQ) has been extensively used because of its speedy implementation with out intensive fine-tuning. Vector quantization (VQ) has proven promise in compressing CNN fashions to extraordinarily low bit-widths. Nevertheless, these strategies face limitations when utilized to DiTs. PTQ strategies considerably scale back mannequin accuracy at very low bit-widths, akin to 2-bit quantization. Conventional VQ strategies solely calibrate the codebook with out adjusting assignments, resulting in suboptimal outcomes because of incorrect task of weight sub-vectors and inconsistent gradients to the codebook.
The applying of basic uniform quantization (UQ) and VQ to the DiT XL/2 mannequin reveals important challenges in reaching optimum efficiency at extraordinarily low bit widths. Whereas VQ outperforms UQ by way of quantization error, it nonetheless faces points with efficiency degradation, particularly at 2-bit and 3-bit quantization ranges. The trade-off between codebook dimension, reminiscence utilization, and quantization error presents a posh optimization downside. Superb-tuning quantized DiTs on massive datasets like ImageNet is computationally intensive and time-consuming. Additionally, the buildup of quantization errors in these large-scale fashions results in suboptimal outcomes, even after fine-tuning. The important thing challenge lies within the conflicting gradients for sub-vectors with the identical task, hindering correct codeword updates.
To beat the constraints of current quantization strategies, researchers from Zhejiang College and vivo Cell Communication Co., Ltd have developed Environment friendly Publish-Coaching Vector Quantization for Diffusion Transformers (VQ4DiT). This sturdy method effectively and precisely vector quantizes DiTs with out requiring a calibration dataset. VQ4DiT decomposes the weights of every layer right into a codebook and candidate task units, initializing every candidate task with an equal ratio. It then employs a zero-data and block-wise calibration technique to concurrently calibrate codebooks and candidate task units. This technique minimizes the imply sq. error between the outputs of floating-point and quantized fashions at every timestep and DiT block, making certain the quantized mannequin maintains efficiency much like its floating-point counterpart whereas avoiding calibration collapse because of cumulative quantization errors.
The DiT XL/2 mannequin, quantized utilizing VQ4DiT, demonstrates superior efficiency on ImageNet 256×256 and 512×512 datasets throughout varied pattern timesteps and weight bit-widths. At 256×256 decision, VQ4DiT outperforms different strategies, together with RepQ-ViT, GPTQ, and Q-DiT, particularly underneath 3-bit quantization. VQ4DiT maintains efficiency near the floating-point mannequin, with minimal will increase in FID and reduces in IS. At 2-bit quantization, the place different algorithms collapse, VQ4DiT continues to generate high-quality pictures with solely a slight lower in precision. Related outcomes are noticed at 512×512 decision, indicating VQ4DiT’s functionality to supply high-quality, high-resolution pictures with minimal reminiscence utilization, making it superb for deploying DiTs on edge gadgets.
This research presents VQ4DiT, a novel and sturdy post-training vector quantization technique for DiTs, that addresses key challenges in environment friendly quantization. By balancing codebook dimension with quantization error and resolving inconsistent gradient instructions, VQ4DiT achieves optimum assignments and codebooks via a zero-data and block-wise calibration course of. This modern method calculates candidate task units for every sub-vector and progressively calibrates every layer’s codebook and assignments. Experimental outcomes display VQ4DiT’s effectiveness in quantizing DiT weights to 2-bit precision whereas preserving high-quality picture era capabilities. This development considerably enhances the potential for deploying DiTs on resource-constrained edge gadgets, opening new prospects for environment friendly, high-quality picture era in varied functions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and LinkedIn. Be part of our Telegram Channel.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


