
Massive Language Fashions (LLMs) like GPT-4, Gemini, and Llama have revolutionized textual dataset augmentation, providing new prospects for enhancing small downstream classifiers. Nonetheless, this method faces vital challenges. The first concern lies within the substantial computational prices of LLM-based augmentation, leading to excessive energy consumption and CO2 emissions. Usually that includes tens of billions of parameters, these fashions are considerably extra resource-intensive than established augmentation strategies equivalent to again translation paraphrasing or BERT-based methods. Researchers need assistance with the necessity to steadiness the improved efficiency of LLM-augmented classifiers in opposition to their environmental and financial prices. Additionally, conflicting outcomes from present research have created uncertainty concerning the comparative effectiveness of LLM-based strategies versus conventional approaches, highlighting the necessity for extra complete analysis on this space.
Researchers have explored varied textual content augmentation methods to reinforce language mannequin efficiency. Established strategies embody character-based augmentations, backtranslation, and earlier language fashions for paraphrasing. Superior approaches incorporate model switch, syntax management, and multilingual paraphrasing. With highly effective LLMs like GPT-4 and Llama, augmentation methods have been tailored to generate high-quality paraphrases. Nonetheless, research evaluating LLM-based augmentation with established strategies have yielded combined outcomes. Some analysis reveals improved classifier accuracy with LLM paraphrasing, whereas others counsel it could not considerably outperform conventional methods.
Researchers from Brno College of Know-how, Kempelen Institute of Clever Applied sciences and the College of Pittsburgh evaluate established textual content augmentation strategies with LLM-based approaches, specializing in accuracy and cost-benefit evaluation. It investigates paraphrasing, phrase inserts, and phrase swaps in each conventional and LLM-based variants. The analysis makes use of six datasets throughout varied classification duties, three classifier fashions, and two fine-tuning approaches. By conducting 267,300 fine-tunings with various pattern sizes, the research goals to establish situations the place conventional strategies carry out equally or higher than LLM-based approaches and decide when the price of LLM augmentation outweighs its advantages. This complete evaluation supplies insights into optimum augmentation methods for various use circumstances.
The research presents a meticulous comparability of established and LLM-based textual content augmentation strategies via an in depth experimental design. It investigates three key augmentation methods: paraphrasing, contextual phrase insertion, and phrase swap. These methods are applied utilizing each conventional approaches, equivalent to again translation and BERT-based contextual embeddings, and superior LLM-based strategies using GPT-3.5 and Llama-3-8B. The analysis spans six various datasets, encompassing sentiment evaluation, intent classification, and information categorization duties, to make sure the broad applicability of findings. By using three state-of-the-art classifier fashions (DistilBERT, RoBERTa, BERT) and two distinct fine-tuning approaches (full fine-tuning and QLoRA), the research supplies a multifaceted examination of augmentation results throughout varied situations. This complete design yields 37,125 augmented samples and a formidable 267,300 fine-tunings, enabling a strong and nuanced comparability of augmentation methodologies.
The analysis course of entails deciding on seed samples, making use of augmentation methods, and fine-tuning classifiers utilizing each unique and augmented knowledge. The research varies the variety of seed samples and picked up samples per seed to supply a nuanced understanding of augmentation results. Handbook validity checks guarantee the standard of augmented samples. A number of fine-tuning runs with totally different random seeds improve outcome reliability. This in depth method permits for a complete evaluation of the augmentation technique’s accuracy and cost-effectiveness, addressing the research’s major analysis questions on the comparative efficiency and cost-benefit evaluation of established versus LLM-based augmentation methods.
The research in contrast LLM-based and established textual content augmentation strategies throughout varied parameters, revealing delicate outcomes. LLM-based paraphrasing outperformed different LLM strategies in 56% of circumstances, whereas contextual phrase insert led amongst established strategies with the identical proportion. For full fine-tuning, LLM-based paraphrasing constantly surpassed contextual insert. Nonetheless, QLoRA fine-tuning confirmed combined outcomes, with contextual insert typically outperforming LLM-based paraphrasing for RoBERTa. LLM strategies demonstrated greater effectiveness with fewer seed samples (5-20 per label), exhibiting a 3% to 17% accuracy improve for QLoRA and a pair of% to 11% for full fine-tuning. Because the variety of seeds elevated, the efficiency hole between LLM and established strategies narrowed. Notably, RoBERTa achieved the best accuracy throughout all datasets, suggesting that cheaper established strategies may be aggressive with LLM-based augmentation for high-performing classifiers, besides when utilizing a small variety of seeds.


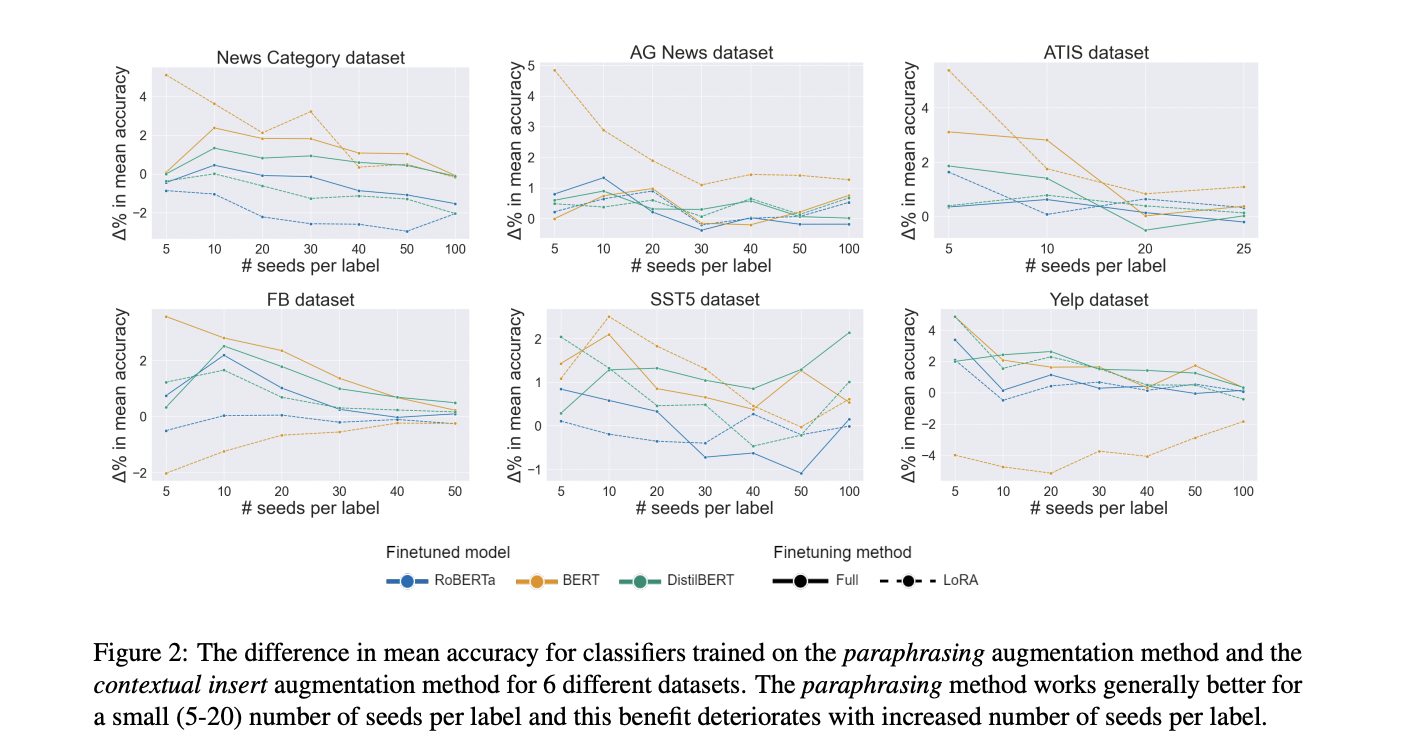
The research performed an in depth comparability between newer LLM-based and established textual augmentation strategies, analyzing their influence on downstream classifier accuracy. The analysis encompassed 6 datasets, 3 classifiers, 2 fine-tuning approaches, 2 augmenting LLMs, and varied numbers of seed samples per label and augmented samples per seed, leading to 267,300 fine-tunings. Among the many LLM-based strategies, paraphrasing emerged as the highest performer, whereas contextual insert led the established strategies. Outcomes point out that LLM-based strategies are primarily helpful in low-resource settings, particularly with 5 to twenty seed samples per label, the place they confirmed statistically vital enhancements and better relative will increase in mannequin accuracy in comparison with established strategies. Nonetheless, because the variety of seed samples elevated, this benefit diminished, and established strategies started to indicate superior efficiency extra steadily. Given the significantly greater prices related to newer LLM strategies, their use is justified solely in low-resource situations the place the associated fee distinction is much less pronounced.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be part of our Telegram Channel. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


