
Synthetic intelligence (AI) has more and more relied on huge and various datasets to coach fashions. Nevertheless, a significant situation has arisen relating to these datasets’ transparency and authorized compliance. Researchers and builders usually use large-scale information with out absolutely understanding its origins, correct attribution, or licensing phrases. As AI continues to increase, these information transparency and licensing gaps pose vital moral and authorized dangers, making it essential to audit and hint the datasets utilized in mannequin growth.
The central drawback is the frequent use of unlicensed or improperly documented information in AI mannequin coaching. Many datasets, particularly these used for fine-tuning AI fashions, come from sources that don’t present clear licensing data. This ends in excessive charges of misattribution or non-compliance with information utilization phrases. The dangers related to such practices are extreme, together with publicity to authorized motion, as fashions educated on unlicensed information may violate copyright legal guidelines. Furthermore, these points increase moral issues relating to the usage of information, significantly when it accommodates private or delicate data.
Whereas some platforms try to prepare and supply dataset licenses, many should achieve this precisely. Platforms like GitHub and Hugging Face, which host fashionable AI datasets, usually comprise incorrect or incomplete license data. Research have proven that over 70% of licenses on these platforms are unspecified, and almost 50% comprise errors. This leaves builders needing clarification about their authorized obligations when utilizing such datasets, which is especially regarding given the rising scrutiny of information utilization in AI. The widespread lack of transparency not solely complicates the event of AI fashions but additionally dangers producing fashions which might be legally weak.
Researchers from establishments like MIT, Google and different main establishments have launched the Information Provenance Explorer (DPExplorer) to handle these issues. This progressive software was designed to assist AI practitioners audit and hint the provenance of datasets used for coaching. The DPExplorer permits customers to view the origins, licenses, and utilization situations of over 1,800 fashionable textual content datasets. By providing an in depth view of every dataset’s supply, creator, and license, the software empowers builders to make knowledgeable selections and keep away from authorized dangers. This effort was a complete collaborative initiative between authorized specialists and AI researchers, making certain that the software addresses technical and authorized facets of dataset use.
The DPExplorer employs an in depth pipeline to collect and confirm metadata from extensively used AI datasets. Researchers meticulously audit every dataset, recording particulars such because the licensing phrases, dataset supply, and modifications made by earlier customers. The software expands on present metadata repositories like Hugging Face by providing a richer taxonomy of dataset traits, together with language composition, activity sort, and textual content size. Customers can filter datasets by industrial or non-commercial licenses and overview how datasets have been repackaged and reused in several contexts. The system additionally auto-generates information provenance playing cards, summarizing the metadata for simple reference and serving to customers determine datasets suited to their particular wants whereas staying inside authorized boundaries.
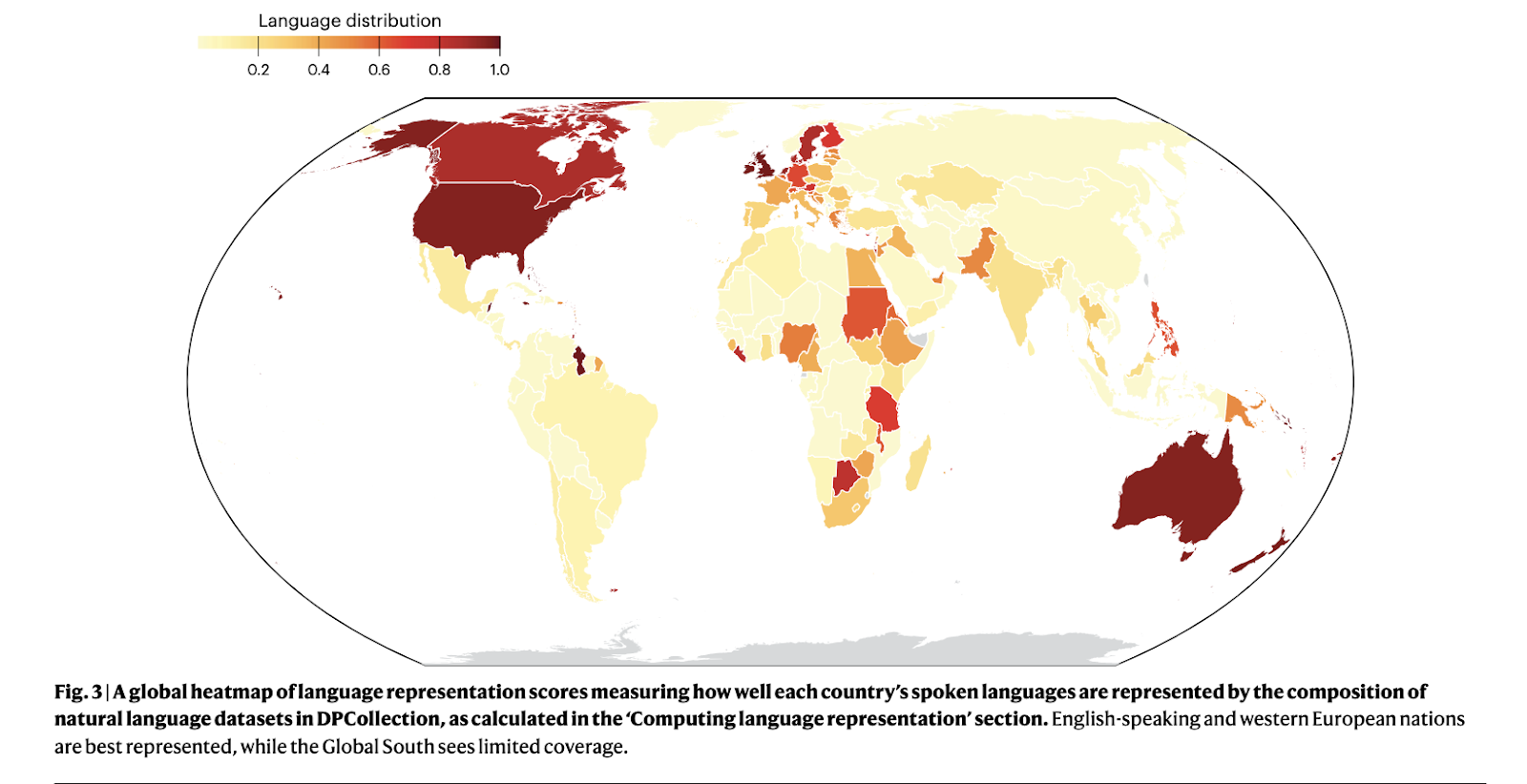
When it comes to efficiency, the DPExplorer has already yielded vital outcomes. The software efficiently diminished the variety of unspecified licenses from 72% to 30%, marking a considerable enchancment in dataset transparency. Out of the datasets audited, 66% of the permits on platforms like Hugging Face had been misclassified, with many marked as extra permissive than the unique writer’s license. Moreover, over 1,800 textual content datasets had been traced for licensing accuracy, which led to a clearer understanding of the authorized situations underneath which AI fashions could be developed. The findings reveal a essential divide between datasets licensed for industrial use and people restricted to non-commercial functions, with the latter being extra various and artistic in content material.
The researchers famous that datasets used for industrial functions usually want extra variety of duties and subjects seen in non-commercial datasets. As an illustration, non-commercial datasets function extra artistic and open-ended duties, akin to artistic writing and problem-solving. In distinction, industrial datasets usually focus extra on quick textual content technology and classification duties. Furthermore, 45% of non-commercial datasets had been synthetically generated utilizing fashions like OpenAI’s GPT, whereas industrial datasets had been primarily derived from human-generated content material. This stark distinction in dataset sorts and utilization signifies the necessity for extra cautious licensing consideration when choosing coaching information for AI fashions.
In conclusion, the analysis highlights a major hole within the licensing and attribution of AI datasets. The introduction of the DPExplorer addresses this problem by offering builders with a strong software for auditing and tracing dataset licenses. This ensures that AI fashions are educated on correctly licensed information, lowering authorized dangers and selling moral practices within the subject. As AI evolves, instruments just like the DPExplorer will guarantee information is used responsibly and transparently.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be part of our Telegram Channel. For those who like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


