Researchers from Aleph Alpha announce a brand new basis mannequin household that features Pharia-1-LLM-7B-control and Pharia-1-LLM-7B-control-aligned. These fashions at the moment are publicly out there beneath the Open Aleph License, explicitly permitting for non-commercial analysis and academic use. This launch marks a big step ahead in offering accessible, high-performance language fashions to the neighborhood.
Pharia-1-LLM-7B-control is engineered to ship concise, length-controlled responses that match the efficiency of main open-source fashions within the 7B to 8B parameter vary. The mannequin is culturally and linguistically optimized for German, French, and Spanish, due to its coaching on a multilingual base corpus. This characteristic enhances its versatility throughout completely different language contexts.
The mannequin’s coaching knowledge has been fastidiously curated to adjust to relevant EU and nationwide rules, together with copyright and knowledge privateness legal guidelines. This consideration to authorized and moral concerns ensures that Pharia-1-LLM-7B-control can be utilized confidently in numerous analysis and academic settings.
With improved token effectivity, Pharia-1-LLM-7B-control excels in domain-specific purposes, significantly within the automotive and engineering industries. Its skill to be aligned to consumer preferences makes it appropriate for crucial purposes with out the danger of shutdown habits, addressing a standard concern in AI deployment.
The Pharia-1-LLM-7B-control-aligned variant has been enhanced with further security guardrails by way of alignment strategies. This model presents an additional layer of safety and reliability, making it perfect for purposes the place security and managed output are paramount.
Accompanying the discharge is a complete mannequin card and an in depth weblog put up. These assets present in-depth details about the method to constructing the Pharia-1-LLM-7B-control mannequin, providing useful insights into its growth and capabilities.
Researchers initially deliberate to optimize hyperparameters utilizing a small proxy mannequin with a hidden measurement of 256 and 27 layers, matching the goal mannequin’s layer depend. The plan concerned sweeping values for studying price, world init std acquire, embedding multiplier, and output multiplier, then upscaling these to the goal hidden measurement utilizing Maximal Replace Parametrization (MuP) ideas.
This methodology was efficiently utilized to seek out hyperparameters for 1B measurement ablations, with a quick 7B sanity examine yielding constructive outcomes. Nevertheless, extreme coaching instabilities emerged on the 7B scale when deviating from the unique configuration, comparable to altering the dataset or sequence size.
Whereas the complete extent of things contributing to those instabilities has but to be utterly understood, MuP seemed to be a big contributor. Consequently, researchers determined in opposition to utilizing MuP for this mannequin coaching. Since then, a greater understanding of making use of MuP to transformers has been developed, leading to a printed paper introducing a modified, numerically steady model of MuP.
For the pre-training runs, researchers relied on heuristics as an alternative of MuP. They adopted the identical studying price as Llama 2 whereas using a normal initialization scheme for the weights. This method allowed for extra steady coaching on the 7B scale.
Researchers carried out ablations on Group-Question-Consideration to reinforce inference-time efficiency, investigating the impression of fewer kv heads whereas sustaining parameter depend consistency. No vital degradation was noticed with fewer kv heads, however substantial benefits in reminiscence consumption and throughput had been famous as much as a kv-q ratio of 1/8. Consequently, a 1/9 ratio was chosen for the ultimate 7B mannequin. Additionally, following Code Llama’s suggestion, a bigger rotary embedding base of 1e6 was investigated for improved long-context skill. Assessments on the 1B scale confirmed no hurt to pre-training and even slight enhancements in downstream scores, resulting in the adoption of the 1e6 base throughout pre-training.
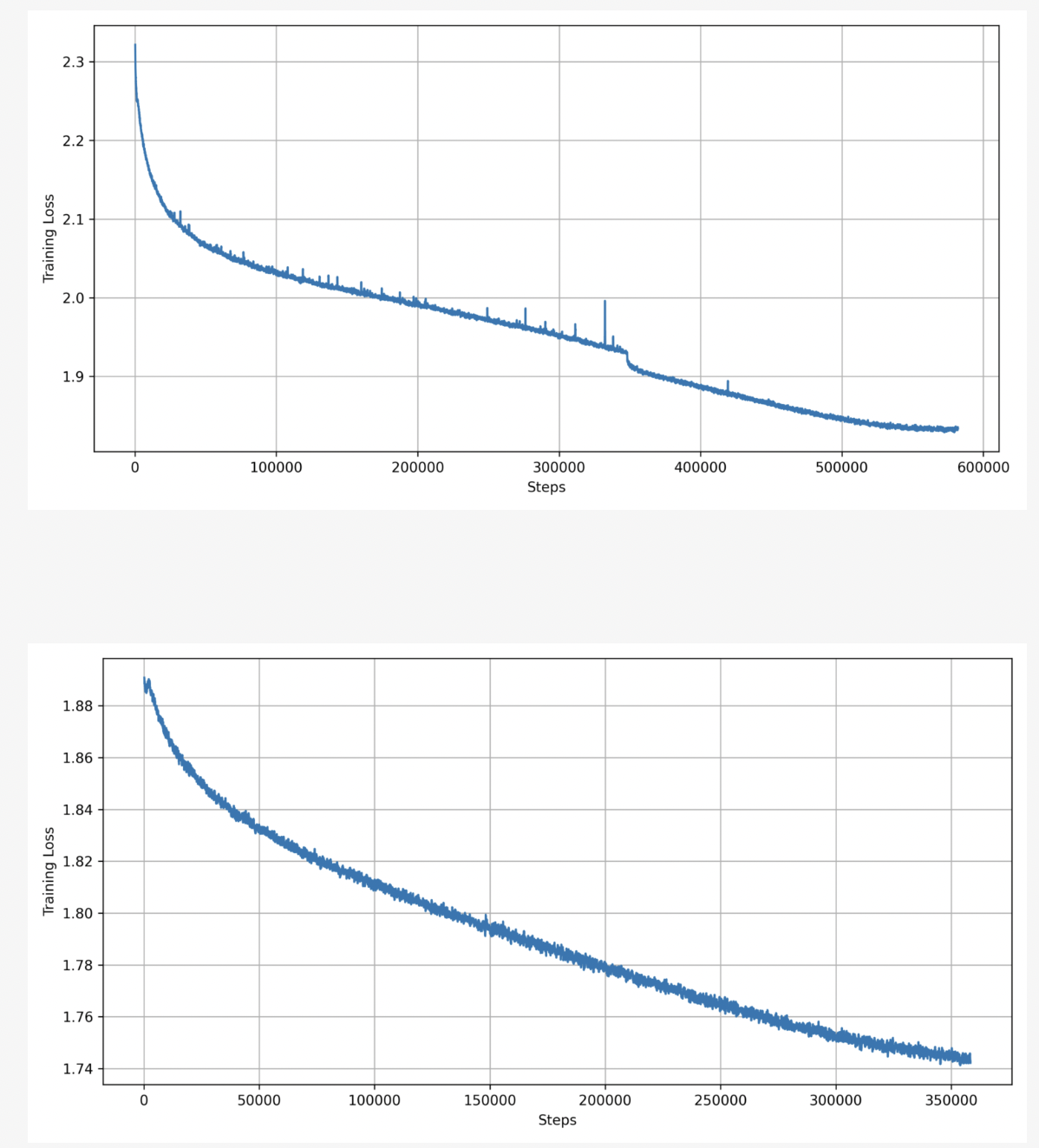
The Pharia-1-LLM-7B base mannequin was educated utilizing the Scaling code base, using parallelization capabilities and efficiency optimizations. Coaching employed bfloat16 format with mixed-precision technique and ZeRO stage 1. A sequence size warm-up technique was used to handle instabilities, scaling from 512 to 8192 tokens. Preliminary pre-training lined 4.7T tokens, adopted by a further 3T tokens on a distinct knowledge combine. The educational price was adjusted for the second section, with a warmup to 3e-5 and decay to 3e-6. Complete coaching spanned 7.7T tokens, using 256 A100 GPUs for the primary section and 256 H100 GPUs for the second, optimizing mannequin structure for throughput.

The upcoming Mannequin Suite launch introduces two variants of the 7B mannequin. Pharia-1-LLM-7B-control-aligned is an instruction-tuned mannequin refined by human and LLM preferences. The alignment course of employed KTO with a studying price of 1e-6 and a beta parameter of 0.1. To handle partial repetitions noticed throughout preliminary coaching, researchers filtered out generated samples with repetitions and included them as detrimental preferences within the knowledge combine. A security dataset was additionally included, serving to the mannequin reject unsafe prompts by treating protected responses as constructive examples and unsafe responses from the Pharia-1-LLM-7B-control mannequin as detrimental examples.
Pharia-1-LLM-7B-control is the instruction-tuned variant with out choice alignment or further security coaching. Researchers noticed that the KTO step led to extra verbose, generic solutions and diminished responsiveness to particular directions, comparable to adhering to desired output size. Regardless of improved scores on widespread instruction-tuning benchmarks, this habits was attributed to elevated use of artificial knowledge in datasets and the tendency of LLM-based analysis strategies to favor verbosity. The Pharia-1-LLM-7B-control mannequin thus maintains a stability between efficiency on benchmarks and sensible usability, providing a substitute for its aligned counterpart for purposes requiring extra exact management over output traits.
The Pharia-1-LLM-7B-control-aligned mannequin is tailor-made for conversational use circumstances, emphasizing readability, security, and alignment with consumer intent. This makes it perfect for purposes like chatbots and digital assistants, the place refined and protected interactions are essential. Conversely, the Pharia-1-LLM-7B-control mannequin, with out alignment, is extra appropriate for duties comparable to info extraction and summarization. In these circumstances, its skill to supply extra direct and concise outputs is most well-liked, making it a better option for duties that require simple and fewer verbose responses.
Aleph Alpha has launched the Pharia-1-LLM-7B mannequin household, out there beneath the Open Aleph License for non-commercial analysis and training. The Pharia-1-LLM-7B-control mannequin is optimized for concise, length-controlled outputs, excelling in domain-specific duties like automotive and engineering. Its aligned variant, Pharia-1-LLM-7B-control-aligned, contains security guardrails for safe conversational purposes. Each fashions are multilingual and compliant with EU legal guidelines. Researchers refined coaching methods, bypassed MuP resulting from instability, and improved inference effectivity. These fashions present accessible, high-performance choices for various AI analysis and software wants.
Try the Mannequin and Particulars. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Here’s a extremely really useful webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.