
Trustworthiness reasoning in multiplayer video games with incomplete info presents important challenges. Gamers have to assess the reliability of others primarily based on partial, typically deceptive info whereas making selections in actual time. Conventional approaches, closely reliant on pre-trained fashions, wrestle to adapt to dynamic environments as a result of their dependence on domain-specific information and suggestions rewards. These limitations lead to an absence of real-time adaptability, which is crucial for efficient decision-making in quickly evolving eventualities. Addressing these challenges is important for advancing AI’s utility in advanced environments, notably in contexts the place real-time belief evaluation is essential, corresponding to in autonomous methods and strategic video games.
Present strategies for trustworthiness reasoning in such environments embrace symbolic reasoning, Bayesian reasoning, and reinforcement studying (RL). Symbolic reasoning focuses on coherence and consistency in fashions however typically lacks flexibility in dynamic settings. Bayesian reasoning, whereas efficient in updating beliefs primarily based on proof, requires important computational assets and is vulnerable to inaccuracies when coping with restricted or noisy information. RL, though highly effective in decision-making, calls for huge quantities of domain-specific coaching information, making it unsuitable for real-time functions. These strategies typically wrestle with computational complexity, restricted information effectivity, and the lack to deal with dynamic, real-time environments successfully.
The researchers from Nanjing College of Data Science and Expertise and Hangzhou Dianzi College introduce the Graph Retrieval Augmented Trustworthiness Reasoning (GRATR) framework, a novel strategy leveraging Retrieval-Augmented Era (RAG) to reinforce trustworthiness reasoning. GRATR constructs a dynamic trustworthiness graph that updates in actual time, integrating evidential info because it turns into accessible. This graph-based technique addresses the restrictions of static information dealing with by current RAG fashions, enabling the system to adapt to the evolving nature of interactions and belief relationships in actual time. GRATR enhances reasoning by retrieving and integrating probably the most related belief information from the graph, enhancing decision-making, and lowering hallucinations in Giant Language Fashions (LLMs). This strategy represents a big development by offering a extra correct and environment friendly resolution for real-time trustworthiness reasoning.
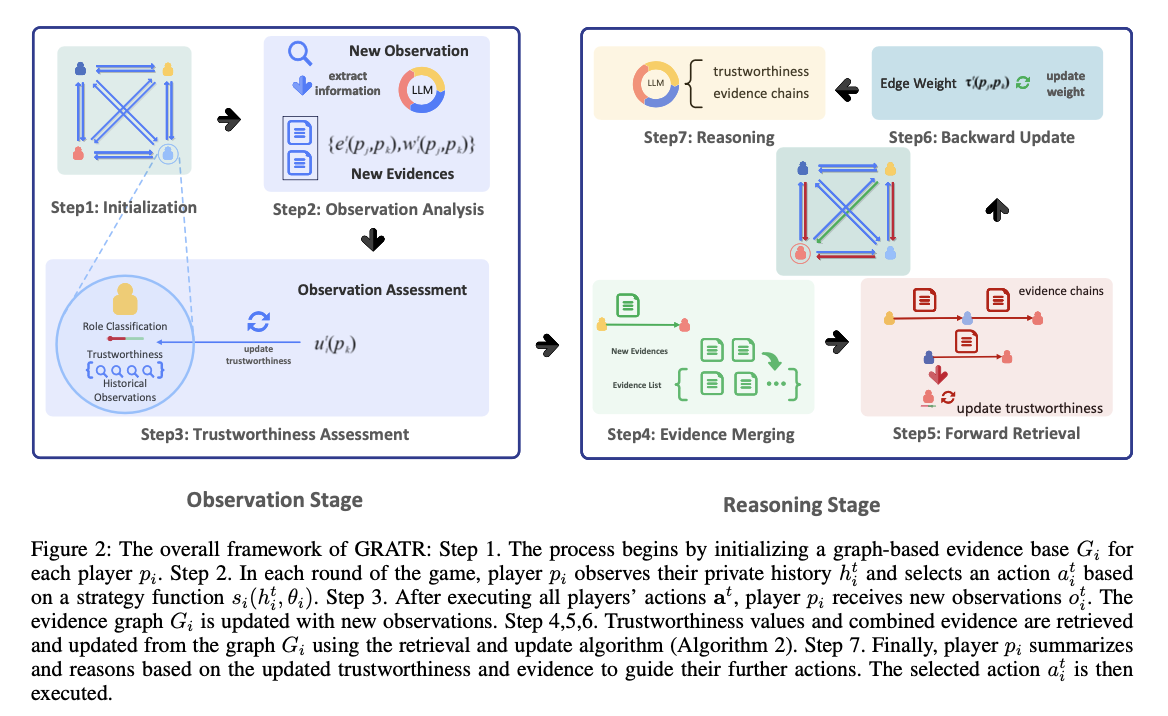
The GRATR framework initializes with a dynamic proof graph, the place nodes signify gamers, and edges signify belief relationships. The graph is up to date constantly as new observations are made, with proof lists connected to edges and trustworthiness values connected to nodes. Key parts embrace the proof merging part, the place proof is aggregated and evaluated, and the ahead retrieval part, the place trustworthiness values are up to date primarily based on retrieved proof chains. GRATR was validated utilizing the multiplayer sport “Werewolf,” with experiments evaluating its efficiency in opposition to baseline LLMs and LLMs enhanced with Native RAG and Rerank RAG. The dataset used for these experiments consisted of fifty sport iterations with eight gamers, together with numerous roles corresponding to werewolves, villagers, and leaders (witch, guard, and seer).
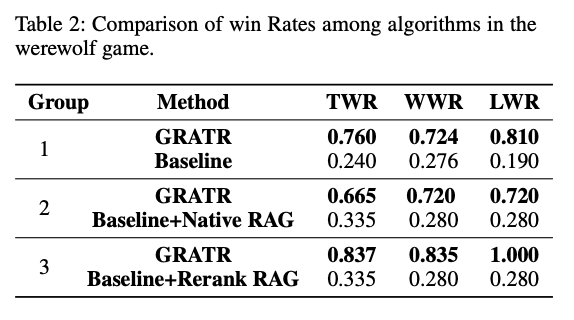
GRATR considerably outperforms baseline strategies when it comes to win charge and reasoning accuracy. As an example, GRATR achieved a complete win charge of 76.0% in a single experiment group, in comparison with 24.0% for the baseline LLM. Equally, the win charge for the werewolf position was 72.4% with GRATR, in comparison with 27.6% for the baseline. GRATR constantly outperformed each Native RAG and Rerank RAG throughout numerous metrics, together with whole win charge, werewolf win charge, and chief win charge. As an example, in a single comparability, GRATR achieved a complete win charge of 83.7%, and the win charge for the werewolf position was 83.5%, which is considerably larger than the efficiency of LLM enhanced with Rerank RAG.
GRATR presents a big development in trustworthiness reasoning for multiplayer video games with incomplete info. By leveraging a dynamic graph construction that updates in real-time, GRATR addresses the restrictions of current strategies, providing a extra correct and environment friendly resolution for real-time decision-making. The experimental outcomes spotlight GRATR’s superior efficiency, notably in enhancing the reasoning capabilities of LLMs whereas mitigating points corresponding to hallucinations. This contribution is poised to have a considerable affect on AI analysis, notably in areas requiring strong real-time belief evaluation, corresponding to autonomous methods and strategic sport environments.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Here’s a extremely really useful webinar from our sponsor: ‘Unlock the facility of your Snowflake information with LLMs’
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


