
The fast development of AI has led to the event of highly effective fashions for discrete and steady knowledge modalities, reminiscent of textual content and pictures, respectively. Nonetheless, integrating these distinct modalities right into a single mannequin stays a major problem. Conventional approaches typically require separate architectures or compromise on knowledge constancy by quantizing steady knowledge into discrete tokens, resulting in inefficiencies and efficiency limitations. This problem is essential for the development of AI, as overcoming it will allow extra versatile fashions able to processing and producing each textual content and pictures seamlessly, thereby enhancing purposes in multi-modal duties.
Present strategies to handle multi-modal technology primarily concentrate on specialised fashions for both discrete or steady knowledge. Language fashions, like transformers, excel at dealing with sequences of discrete tokens, making them extremely efficient for duties involving textual content. Conversely, diffusion fashions are the state-of-the-art for producing high-quality photographs by studying to reverse a noise-adding course of. Nonetheless, these fashions usually require separate coaching pipelines for every modality, resulting in inefficiencies. Furthermore, some approaches try to unify these modalities by quantizing photographs into discrete tokens for processing by language fashions, however this typically leads to data loss, limiting the mannequin’s means to generate high-resolution photographs or carry out advanced multi-modal duties.
A crew of researchers from Meta, Waymo and College of Southern California suggest Transfusion, an revolutionary methodology that integrates language modeling and diffusion processes inside a single transformer structure. This proposed methodology addresses the restrictions of current approaches by permitting the mannequin to course of and generate each discrete and steady knowledge with out the necessity for separate architectures or quantization. Transfusion combines the next-token prediction loss for textual content with the diffusion course of for photographs, enabling a unified coaching pipeline. The strategy consists of key improvements, reminiscent of modality-specific encoding and decoding layers and using bidirectional consideration inside photographs, which collectively improve the mannequin’s means to deal with numerous knowledge sorts effectively and successfully. This integration represents a major step ahead in creating extra versatile AI techniques able to performing advanced multi-modal duties.
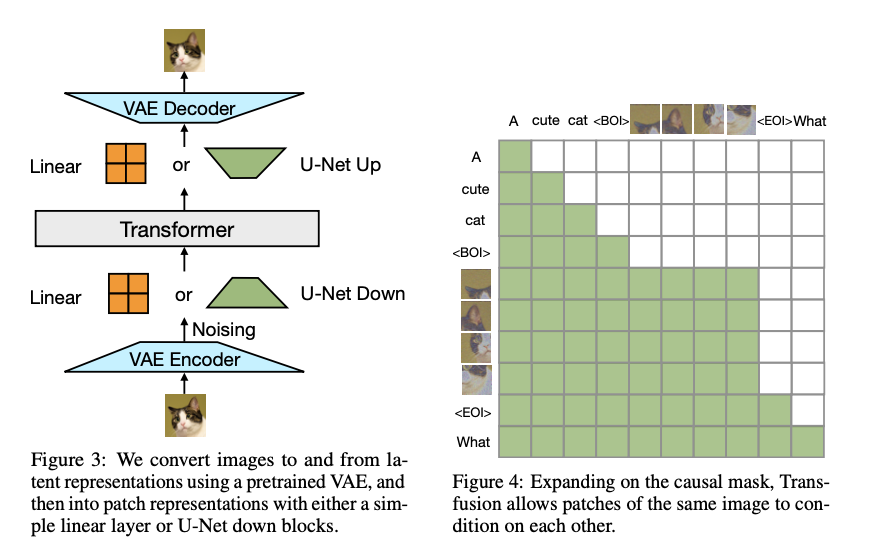
Transfusion is educated on a balanced combination of textual content and picture knowledge, with every modality being processed via its particular goal: next-token prediction for textual content and diffusion for photographs. The mannequin’s structure consists of a transformer with modality-specific elements, the place textual content is tokenized into discrete sequences and pictures are encoded as latent patches utilizing a variational autoencoder (VAE). The mannequin employs causal consideration for textual content tokens and bidirectional consideration for picture patches, guaranteeing that each modalities are processed successfully. Coaching is carried out on a large-scale dataset consisting of two trillion tokens, together with 1 trillion textual content tokens and 692 million photographs, every represented by a sequence of patch vectors. The usage of U-Internet down and up blocks for picture encoding and decoding additional enhances the mannequin’s effectivity, notably when compressing photographs into patches.
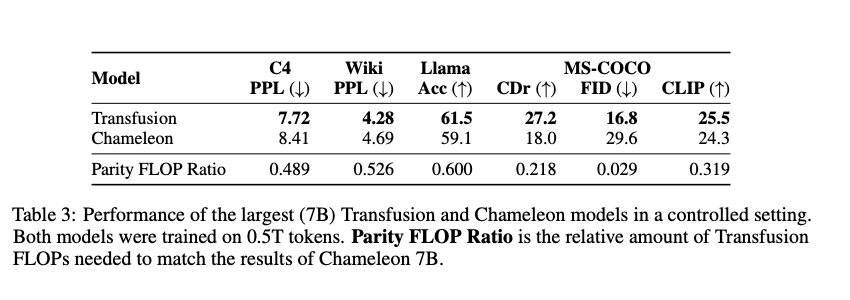
Transfusion demonstrates superior efficiency throughout a number of benchmarks, notably in duties involving text-to-image and image-to-text technology. This revolutionary strategy outperforms current strategies by a major margin in key metrics reminiscent of Frechet Inception Distance (FID) and CLIP scores. For instance, in a managed comparability, Transfusion achieves a 2× decrease FID rating than the Chameleon fashions, demonstrating higher scaling and decreased computational prices. A essential analysis desk highlights these outcomes, showcasing the effectiveness of Transfusion throughout varied benchmarks. Notably, the 7B parameter mannequin achieves a FID rating of 16.8 on the MS-COCO benchmark, outperforming different approaches that require extra computational assets to realize comparable outcomes .
In conclusion, Transfusion represents a novel strategy to multi-modal studying, successfully combining language modeling and diffusion processes inside a single structure. By addressing the inefficiencies and limitations of current strategies, Transfusion gives a extra built-in and environment friendly answer for processing and producing each textual content and pictures. This proposed methodology has the potential to considerably influence varied AI purposes, notably these involving advanced multi-modal duties, by enabling a extra seamless and efficient integration of numerous knowledge modalities.

Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


