
Language Basis Fashions (LFMs) and Giant Language Fashions (LLMs) have demonstrated their means to deal with a number of duties effectively with a single fastened mannequin. This achievement has motivated the event of Picture Basis Fashions (IFMs) in pc imaginative and prescient, which goal to encode basic info from photographs into embedding vectors. Nonetheless, utilizing these strategies poses a problem in video evaluation. One method includes treating movies as a sequence of photographs, the place every body is sampled and embedded earlier than combining; nevertheless, this method faces challenges in capturing detailed movement and small adjustments between frames. It turns into obscure the continual move of knowledge in movies, particularly in the case of monitoring object motion and minor frame-to-frame variations
The prevailing works tried to beat these challenges utilizing two foremost approaches primarily based on the Imaginative and prescient Transformer structure (ViT). The primary method makes use of distillation with high-performance IFMs like CLIP as lecturers, and the second method is predicated on masked modeling, the place the mannequin predicts lacking info from partial enter. Nonetheless, each approaches have their limitations. Distillation-based strategies, like UMT and InternVideo2, battle with motion-sensitive benchmarks like One thing-One thing-v2 and Diving-48. The masked modeling-based strategies, like V-JEPA, carry out badly on appearance-centric benchmarks like Kinetics-400 and Moments-in-Time. These limitations spotlight the problem in capturing the looks of objects and their movement in movies.
A staff from Twelve Labs has proposed TWLV-I, a brand new mannequin designed to offer embedding vectors for movies that seize look and movement. Regardless that skilled solely on publicly accessible datasets, TWLV-I exhibits sturdy efficiency on look and motion-focused motion recognition benchmarks. Furthermore, the mannequin achieves state-of-the-art efficiency in video-centric duties equivalent to temporal and spatiotemporal motion localization, in addition to temporal motion segmentation. The present analysis strategies are enhanced to investigate the TWLV-I and different Video Basis Fashions (VFMs), with a brand new analytical method and a way to search out the mannequin’s means to distinguish movies primarily based on movement route, unbiased of look.
TWLV-I adopts ViT structure, accessible in Base with 86M parameters and Giant with 307M parameters variations. The mannequin tokenizes enter movies into patches, processes them by way of the transformer, and swimming pools the ensuing patch-wise embeddings to acquire the general video embedding. Furthermore, the pretraining dataset incorporates Kinetics-710, HowTo360K, WebVid10M, and numerous picture datasets. The coaching goal of TWLV-I integrates strengths from distillation-based and masked modeling-based approaches utilizing completely different reconstruction goal methods. The mannequin makes use of two body sampling strategies, (a) Uniform Embedding for shorter movies and (b) Multi-Clip Embedding for longer movies, to beat computational constraints.
The outcomes obtained on TWLV-I present important efficiency enhancement over current fashions in motion recognition duties. Based mostly on the typical top-1 accuracy of linear probing throughout 5 motion recognition benchmarks and utilizing solely publicly accessible datasets for pretraining, TWLV-I outperforms VJEPA (ViT-L) by 4.6% factors and UMT (ViT-L) by 7.7% factors. This mannequin outperforms bigger fashions like DFN (ViT-H) by 7.2% factors, V-JEPA (ViT-H) by 2.7% factors, and InternVideo2 (ViT-g) by 2.8% factors. Researchers additionally supplied embedding vectors generated by TWLV-I from broadly used video benchmarks and analysis supply code that may straight make the most of these embeddings.
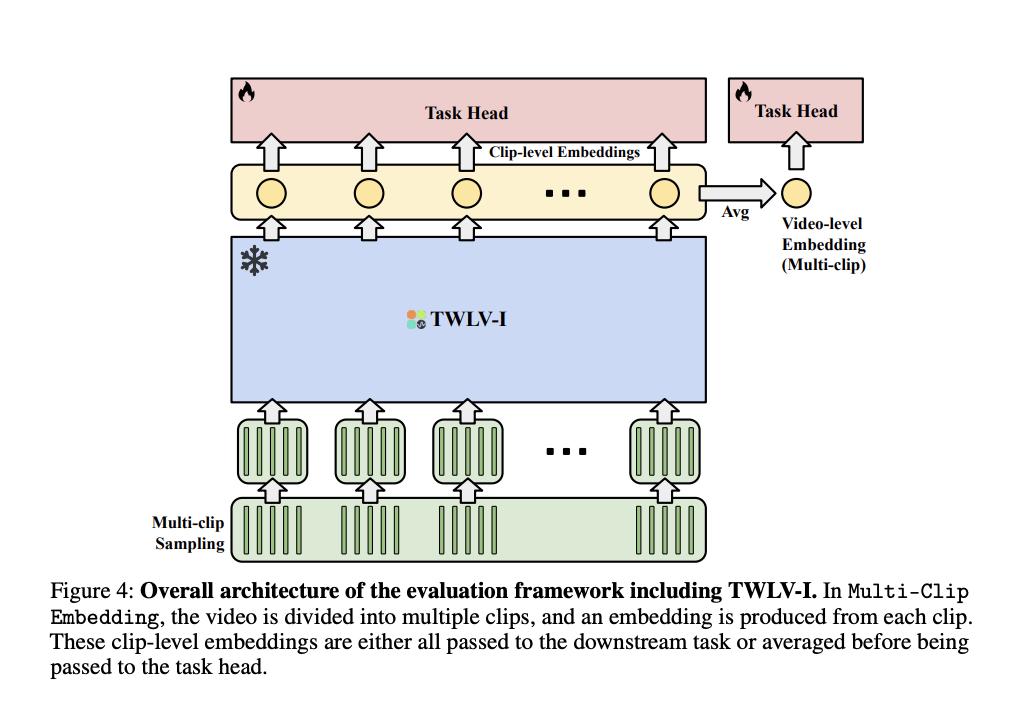
A staff from Twelve Labs has proposed TWLV-I, a novel mannequin designed to offer embedding vectors for movies that seize look and movement. TWLV-I proves a powerful video basis mannequin that exhibits nice efficiency in understanding movement and look. The TWLV-I mannequin and its embeddings are anticipated for use broadly in numerous purposes. Furthermore, the analysis and evaluation strategies will probably be actively adopted within the video basis mannequin area. Sooner or later, these strategies are anticipated to information analysis within the video understanding area, making additional progress in growing extra complete video evaluation fashions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here

Sajjad Ansari is a closing 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


