
Massive Language Fashions (LLMs) like GPT-4, Qwen2, and LLaMA have revolutionized synthetic intelligence, significantly in pure language processing. These Transformer-based fashions, skilled on huge datasets, have proven outstanding capabilities in understanding and producing human language, impacting healthcare, finance, and training sectors. Nonetheless, LLMs want extra domain-specific data, real-time data, and proprietary information outdoors their coaching corpus. This limitation can result in “hallucination,” the place fashions generate inaccurate or fabricated data. To mitigate this problem, researchers have targeted on creating strategies to complement LLMs with exterior data, with Retrieval-Augmented Era (RAG) rising as a promising resolution.
Graph Retrieval-Augmented Era (GraphRAG) has emerged as an modern resolution to deal with the restrictions of conventional RAG strategies. In contrast to its predecessor, GraphRAG retrieves graph components containing relational data from a pre-constructed graph database, contemplating the interconnections between texts. This strategy allows extra correct and complete retrieval of relational data. GraphRAG makes use of graph information, similar to data graphs, which provide abstraction and summarization of textual information, thereby lowering enter textual content size and mitigating verbosity issues. By retrieving subgraphs or graph communities, GraphRAG can entry complete data, successfully addressing challenges like Question-Centered Summarization by capturing broader context and interconnections throughout the graph construction.
Researchers from the Faculty of Intelligence Science and Expertise, Peking College, School of Pc Science and Expertise, Zhejiang College, Ant Group, China, Gaoling Faculty of Synthetic Intelligence, Renmin College of China, and Rutgers College, US, present a complete evaluation of GraphRAG, a state-of-the-art methodology addressing limitations in conventional RAG programs. The examine presents a proper definition of GraphRAG and descriptions its common workflow, comprising G-Indexing, G-Retrieval, and G-Era. It analyzes core applied sciences, mannequin choice, methodological design, and enhancement methods for every element. The paper additionally explores numerous coaching methodologies, downstream duties, benchmarks, utility domains, and analysis metrics. Additionally, it discusses present challenges, and future analysis instructions, and compiles a list of present trade GraphRAG programs, bridging the hole between educational analysis and real-world functions.
GraphRAG builds upon conventional RAG strategies by incorporating relational data from graph databases. In contrast to text-based RAG, GraphRAG considers relationships between texts and integrates structural data as further data. It differs from different approaches like LLMs on Graphs, which primarily concentrate on integrating LLMs with Graph Neural Networks for graph information modeling. GraphRAG additionally extends past Data Base Query Answering (KBQA) strategies, making use of them to varied downstream duties. This strategy presents a extra complete resolution for using structured information in language fashions, qualifying limitations in purely text-based programs and opening new avenues for improved efficiency throughout a number of functions.
Textual content-Attributed Graphs (TAGs) kind the muse of GraphRAG, representing graph information with textual attributes for nodes and edges. Graph Neural Networks (GNNs) mannequin this graph information utilizing message-passing methods to acquire node and graph-level representations. Language Fashions (LMs), each discriminative and generative, play essential roles in GraphRAG. Initially, GraphRAG targeted on enhancing pre-training for discriminative fashions. Nonetheless, with the appearance of LLMs like ChatGPT and LLaMA, which reveal highly effective in-context studying capabilities, the main target has shifted to enhancing data retrieval for these fashions. This evolution goals to deal with complicated duties and mitigate hallucinations, driving speedy developments within the area.
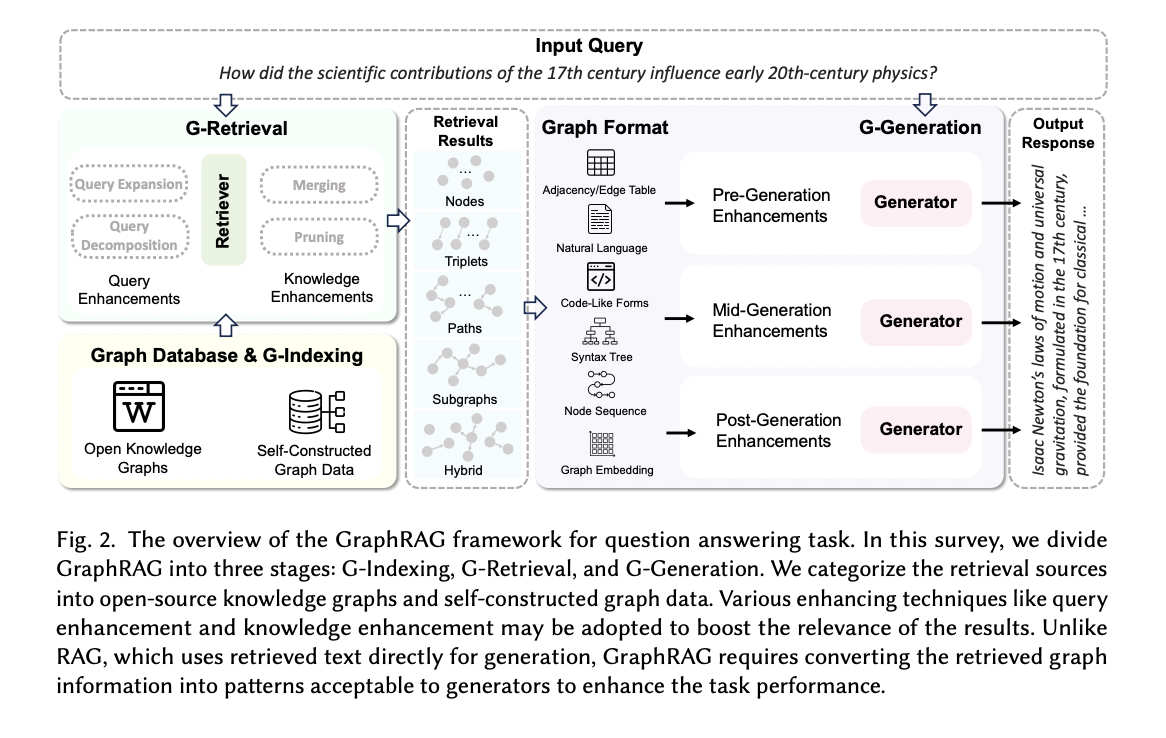
GraphRAG enhances language mannequin responses by retrieving related data from graph databases. The method includes three major phases: Graph-Primarily based Indexing (G-Indexing), Graph-Guided Retrieval (G-Retrieval), and Graph-Enhanced Era (G-Era). G-Indexing creates a graph database aligned with downstream duties. G-Retrieval extracts pertinent data from the database in response to consumer queries. G-Era synthesizes outputs primarily based on the retrieved graph information. This strategy is formalized mathematically to maximise the chance of producing the optimum reply given a question and graph information. The method effectively approximates complicated graph buildings to supply extra knowledgeable and correct responses.
GraphRAG’s efficiency closely will depend on the standard of its graph database. This basis includes choosing or establishing acceptable graph information, starting from open data graphs to self-constructed datasets, and implementing efficient indexing strategies to optimize retrieval and technology processes.
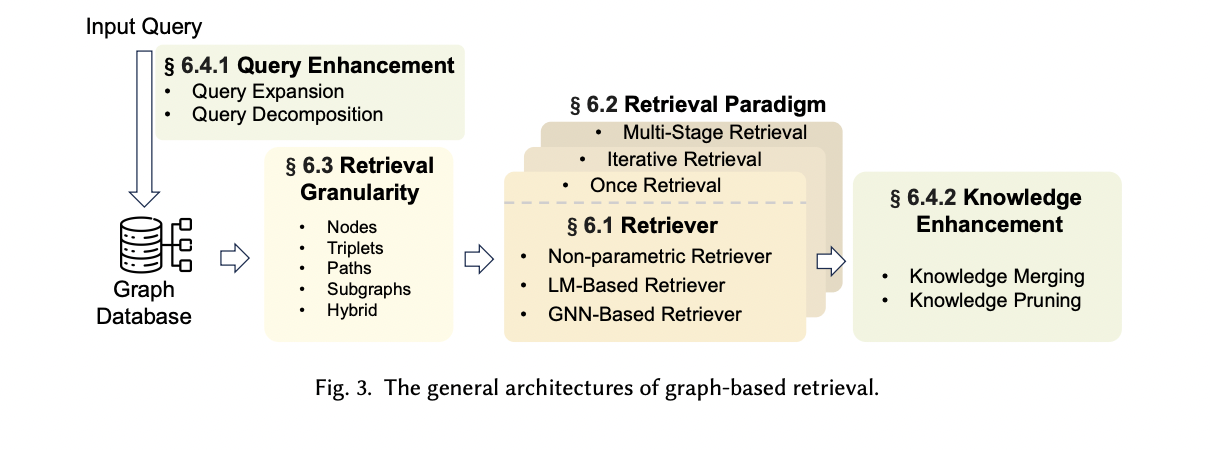
- Graph information utilized in GraphRAG may be categorized into two major sorts: Open Data Graphs and Self-Constructed Graph Information. Open Data Graphs embrace Basic Data Graphs (like Wikidata, Freebase, and DBpedia) and Area Data Graphs (similar to CMeKG for biomedical fields and Wiki-Films for the movie trade). Self-Constructed Graph Information is created from numerous sources to fulfill particular process necessities. For example, researchers have constructed doc graphs, entity-relation graphs, and task-specific graphs like patent-phrase networks. The selection of graph information considerably influences GraphRAG’s efficiency, with every kind providing distinctive benefits for various functions and domains.
- Graph-based indexing is essential for environment friendly question operations in GraphRAG, using three major strategies: graph indexing, textual content indexing, and vector indexing. Graph indexing preserves all the graph construction, enabling quick access to edges and neighboring nodes. Textual content indexing converts graph information into textual descriptions, permitting for text-based retrieval methods. Vector indexing transforms graph information into vector representations, facilitating speedy retrieval and environment friendly question processing. Every methodology presents distinctive benefits: graph indexing for structural data entry, textual content indexing for textual content material retrieval, and vector indexing for fast searches. In observe, a hybrid strategy combining these strategies is commonly most well-liked to optimize retrieval effectivity and effectiveness in GraphRAG programs.
The retrieval course of in GraphRAG is essential for extracting related graph information to reinforce output high quality. Nonetheless, it faces two main challenges: the exponential development of candidate subgraphs as graph dimension will increase and the problem in precisely measuring similarity between textual queries and graph information. To handle these points, researchers have targeted on optimizing numerous elements of the retrieval course of. This contains creating environment friendly retriever fashions, refining retrieval paradigms, figuring out acceptable retrieval granularity, and implementing enhancement methods. These efforts intention to enhance the effectivity and accuracy of graph information retrieval, in the end resulting in more practical and contextually related outputs in GraphRAG programs.
The technology stage in GraphRAG integrates retrieved graph information with the question to supply high-quality responses. This course of includes choosing acceptable technology fashions, reworking graph information into suitable codecs, and utilizing each the question and remodeled information as inputs. Moreover, generative enhancement methods are employed to accentuate query-graph interactions and enrich content material technology, additional enhancing the ultimate output.

- Generator choice in GraphRAG will depend on the downstream process. For discriminative duties, GNNs or discriminative language fashions can study information representations and map them to reply choices. Generative duties, nevertheless, require decoders to supply textual content responses. Whereas generative language fashions can be utilized for each process sorts, GNNs and discriminative fashions alone are inadequate for generative duties that necessitate textual content technology.
- When utilizing LMs as turbines in GraphRAG, graph translators are important to transform non-Euclidean graph information into LM-compatible codecs. This conversion course of sometimes ends in two major graph codecs: graph languages and graph embeddings. These codecs allow LMs to successfully course of and make the most of structured graph data, enhancing their generative capabilities and permitting for seamless integration of graph information within the technology course of.
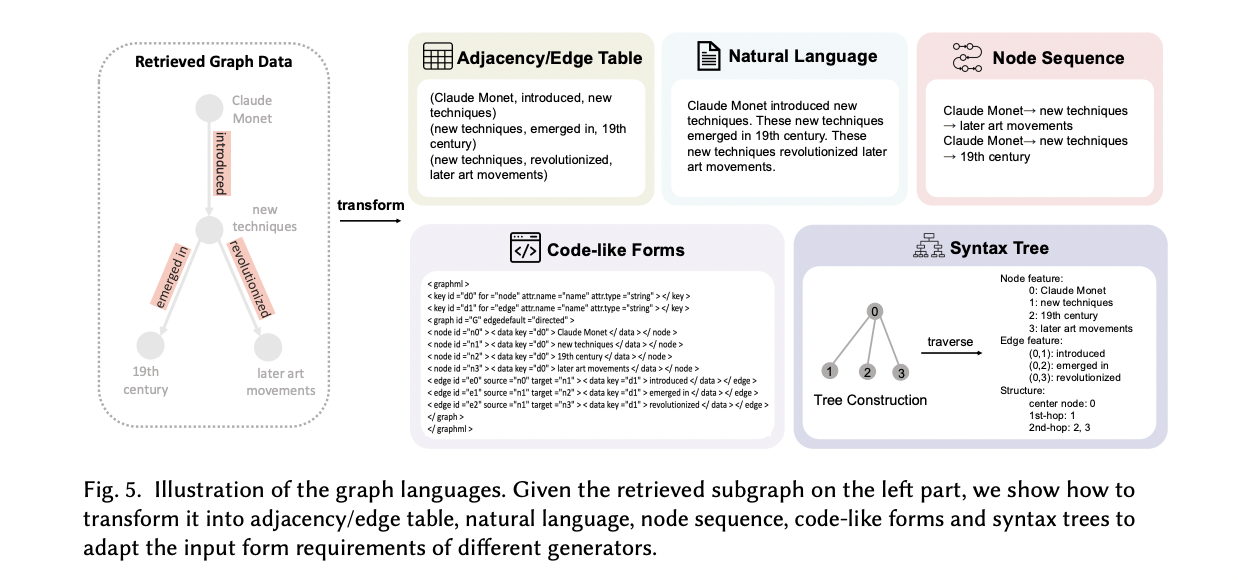
- Era enhancement methods in GraphRAG intention to enhance output high quality past fundamental graph information conversion and question integration. These methods are categorized into three phases: pre-generation, mid-generation, and post-generation enhancements. Every stage focuses on totally different elements of the technology course of, using numerous strategies to refine and optimize the ultimate response, in the end resulting in extra correct, coherent, and contextually related outputs.
GraphRAG coaching strategies are categorized into Coaching-Free and Coaching-Primarily based approaches. Coaching-free strategies, typically used with closed-source LLMs like GPT-4, depend on rigorously crafted prompts to manage retrieval and technology capabilities. Whereas using LLMs’ robust textual content comprehension skills, these strategies could produce sub-optimal outcomes on account of an absence of task-specific optimization. Coaching-based strategies contain fine-tuning fashions utilizing supervised indicators, probably enhancing efficiency by adapting to particular process targets. Joint coaching of retrievers and turbines goals to reinforce their synergy, boosting efficiency on downstream duties. This collaborative strategy makes use of the complementary strengths of each parts for extra strong and efficient ends in data retrieval and content material technology functions.
GraphRAG is utilized to varied downstream duties in pure language processing. These embrace Query Answering duties like KBQA and CommonSense Query Answering (CSQA), which check programs’ potential to retrieve and motive over structured data. Data Retrieval duties similar to Entity Linking and Relation Extraction profit from GraphRAG’s potential to make the most of graph buildings. Additionally, GraphRAG enhances efficiency actually verification, hyperlink prediction, dialogue programs, and recommender programs. In these functions, GraphRAG’s capability to extract and analyze structured data from graphs improves accuracy, contextual relevance, and the power to uncover latent relationships and patterns.
GraphRAG is extensively utilized throughout numerous domains on account of its potential to combine structured data graphs with pure language processing. In e-commerce, it enhances personalised suggestions and customer support by using user-product interplay graphs. Within the biomedical area, it improves medical decision-making by using disease-symptom-medication relationships. Tutorial and literature domains profit from GraphRAG’s potential to investigate analysis and ebook relationships. In authorized contexts, it aids in case evaluation and authorized session by using quotation networks. GraphRAG additionally finds functions in intelligence report technology and patent phrase similarity detection. These numerous functions reveal GraphRAG’s versatility in extracting and using structured data to reinforce decision-making and data retrieval throughout industries.
GraphRAG programs are evaluated utilizing two varieties of benchmarks: task-specific datasets and complete GraphRAG-specific benchmarks like STARK, GraphQA, GRBENCH, and CRAG. Analysis metrics fall into two classes: downstream process analysis and retrieval high quality evaluation. Downstream process metrics embrace Actual Match, F1 rating, BERT4Score, GPT4Score for KBQA, Accuracy for CSQA, and BLEU, ROUGE-L, METEOR for generative duties. Retrieval high quality is assessed utilizing metrics such because the ratio of reply protection to subgraph dimension, question relevance, range, and faithfulness scores. These metrics intention to supply a complete analysis of GraphRAG programs’ efficiency in each data retrieval and task-specific technology.
A number of industrial GraphRAG programs have been developed to make the most of large-scale graph information and superior graph database applied sciences. Microsoft’s GraphRAG makes use of LLMs to assemble entity-based data graphs and generate group summaries for enhanced Question-Centered Summarization. NebulaGraph’s system integrates LLMs with their graph database for extra exact search outcomes. Antgroup’s framework combines DB-GPT, OpenSPG, and TuGraph for environment friendly triple extraction and subgraph traversal. Neo4j’s NaLLM framework explores the synergy between their graph database and LLMs, specializing in pure language interfaces and data graph creation. Neo4j’s LLM Graph Builder automates data graph development from unstructured information. These programs reveal the rising industrial curiosity in combining graph applied sciences with giant language fashions for enhanced efficiency.
This survey gives a complete overview of GraphRAG know-how, systematically categorizing its basic methods, coaching methodologies, and functions. GraphRAG enhances data retrieval by using relational data from graph datasets, addressing the restrictions of conventional RAG approaches. As a nascent area, the survey outlines benchmarks, analyzes present challenges, and illuminates future analysis instructions. This complete evaluation presents precious insights into GraphRAG’s potential to enhance the relevance, accuracy, and comprehensiveness of data retrieval and technology programs.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


