Tabular information, which dominates many genres, resembling healthcare, monetary, and social science functions, accommodates rows and columns with structured options, making it a lot simpler for information administration or evaluation. Nonetheless, the variety of tabular information, together with numerical, unconditional, and textual, brings large challenges to attaining strong and correct predictive efficiency. One other space for enchancment in successfully modeling and analyzing one of these information is the complexity of the relationships inside the information, significantly dependencies between rows and columns.
The primary problem in analyzing tabular information is that it is rather troublesome to deal with its heterogeneous construction. Conventional machine studying fashions keep far-off when contemplating the advanced relationships inside tabular datasets, particularly for giant and sophisticated datasets. These fashions require extra steering to generalize properly within the presence of a range of knowledge varieties and interdependencies of tabular information. This problem turns into much more advanced given the necessity for prime predictive accuracy and robustness, particularly in vital functions resembling well being care, the place the choices amongst information evaluation could be fairly consequential.
Totally different strategies have been utilized to beat these challenges of modeling tabular information. Early strategies relied largely on typical machine studying, most of which wanted quite a lot of characteristic engineering to mannequin the subtleties of the information. The recognized weak spot of those naturally lay of their lack of ability to scale in dimension and complexity of the enter dataset. Extra lately, strategies from NLP have been tailored for tabular information; extra particularly, transformer-based architectures are more and more carried out. These strategies began by coaching the transformers from scratch over tabular information, however this had the drawback of needing large quantities of coaching information with vital scalability points. In opposition to this backdrop, researchers started utilizing PLMs like BERT, which required much less information and supplied higher predictive efficiency.
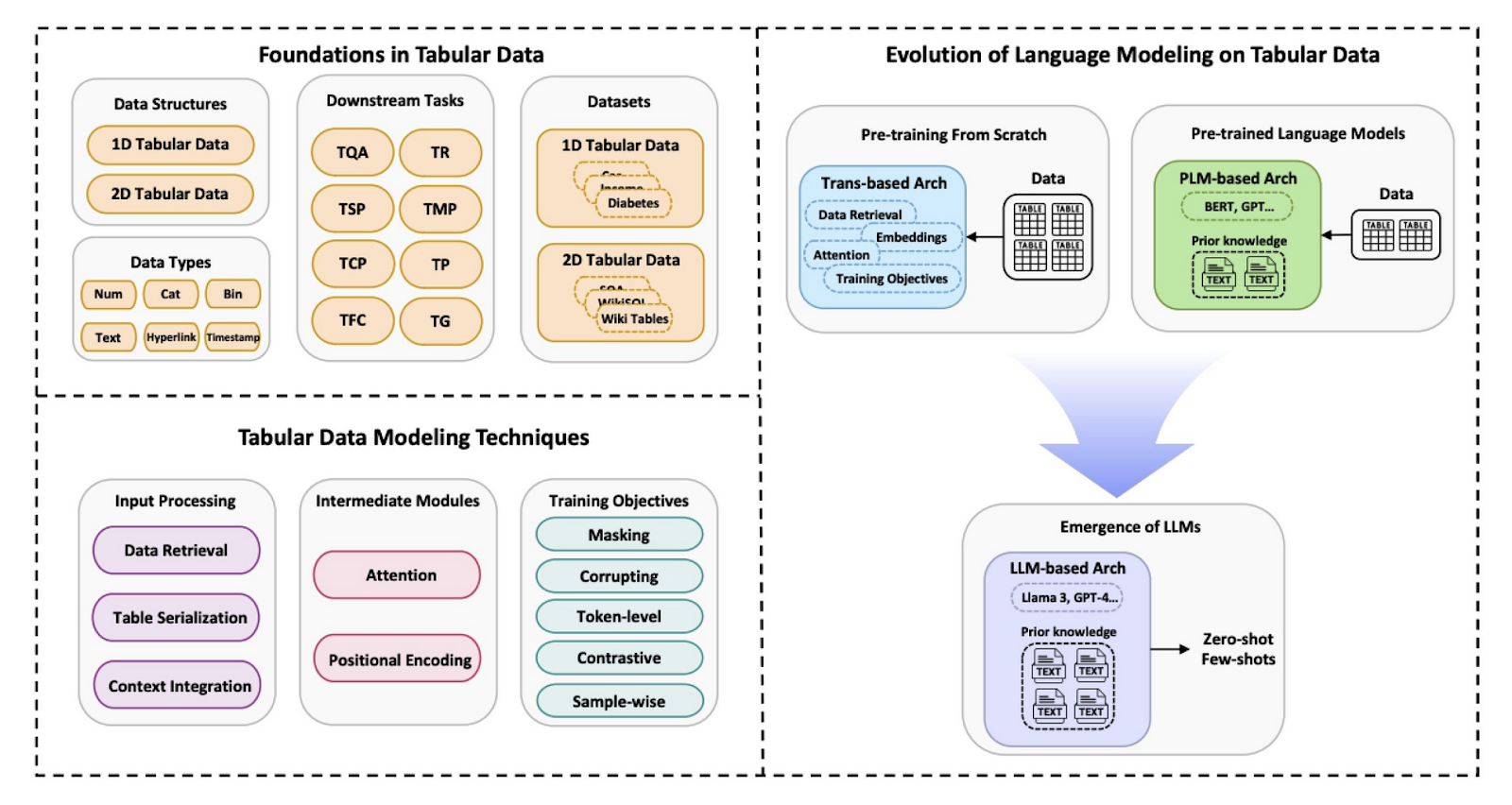
Researchers from the Nationwide College of Singapore supplied a complete survey of the assorted language modeling strategies developed for tabular information. The evaluate systematizes classification for literature and additional identifies a pattern shift from conventional machine studying fashions to superior strategies utilizing state-of-the-art LLMs like GPT and LLaMA. This analysis has emphasised the evolution of those fashions, exhibiting how LLMs have been radical within the discipline, taking it additional into extra refined functions in modeling tabular information. This work is necessary to fill a spot within the related literature by offering an in depth taxonomy of the tabular information buildings, key datasets, and varied modeling strategies.
The methodology proposed by the analysis group categorizes tabular information into two main classes: 1D and 2D. However, 1D tabular information often accommodates just one desk, with the primary work coming on the row degree, which, after all, is less complicated however crucial for duties like classification and regression. In distinction, 2D tabular information consists of a number of associated tables, requiring extra advanced modeling strategies for duties resembling desk retrieval and desk question-answering. The researchers delve into completely different methods for turning tabular information into varieties that their language mannequin can eat. These methods embrace flattening sequences, row processing, and integrating this data in prompts. By way of these strategies, the language fashions lever a extra profound understanding and processing skills of tabular information in direction of assured predictive outcomes.
The analysis reveals how robust the flexibility of nice massive language fashions is in most duties of tabular information. These fashions have demonstrated marked enchancment in understanding and processing advanced information buildings on capabilities resembling Desk Query Answering and Desk Semantic Parsing. The authors illustrate how LLMs allow a regular rise in all duties at greater ranges of accuracy and effectivity by exploiting pre-trained data and superior consideration mechanisms that set new tabular information modeling requirements throughout many functions.
In conclusion, the analysis has underscored the potential that NLP strategies have for successfully altering the very nature of tabular information evaluation within the presence of huge language fashions. By systematizing the evaluate and categorization of present strategies, researchers have proposed a really clear roadmap for future developments on this space. The proposed methodologies negate the intrinsic challenges of tabular information and open up new superior functions with ensures of relevance and effectiveness, together with when the complexity of knowledge rises.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.