
Excessive-fidelity waveform era, significantly in text-to-speech (TTS) and audio era functions, entails a number of essential challenges. Precisely producing natural-sounding audio stays a major problem, important for real-world deployment. Capturing the pure periodicity of high-resolution waveforms and producing high-quality output with out artifacts comparable to metallic sounds or hissing noises is tough. Moreover, gradual inference velocity limits the practicality of many high-quality generative fashions. Overcoming these challenges is significant for advancing AI capabilities in voice conversion, TTS, and basic audio synthesis.
Present waveform era approaches predominantly make the most of GAN-based fashions comparable to MelGAN, HiFi-GAN, and BigVGAN. These fashions generate high-quality waveforms quickly through the use of numerous discriminators to seize distinct audio sign traits. Nevertheless, they face substantial limitations, together with the need for intensive hyperparameter tuning, complicated loss capabilities, and susceptibility to train-inference mismatches, which may result in undesirable artifacts within the generated audio. Diffusion fashions like Multi-Band Diffusion (MBD) try to deal with high quality points by modeling frequency bands individually however endure from gradual era speeds and problem in capturing high-frequency info precisely, limiting their sensible utility in real-time or high-fidelity contexts.
A workforce of Researchers from Ajou College, Korea College, and KT Corp. suggest PeriodWave, a novel waveform era methodology that includes period-aware move matching. This method captures the periodic options of waveform alerts by together with a number of intervals within the estimation course of, thereby reflecting the pure periodicity of high-resolution waveforms. The core innovation entails utilizing move matching to estimate vector fields based mostly on optimum transport paths, guaranteeing quick and correct waveform era. The tactic additionally introduces a period-conditional common estimator, which permits parallel inference throughout completely different intervals, considerably bettering computational effectivity. Moreover, PeriodWave employs discrete wavelet rework (DWT) for frequency disentanglement, enhancing the mannequin’s functionality to generate correct high-frequency elements. This mix of methods represents a major development, providing a extra environment friendly and scalable answer for high-fidelity waveform era.
PeriodWave integrates a number of superior technical elements to realize superior efficiency. A time-conditional UNet-based construction is utilized for vector discipline estimation, essential for capturing the periodic options of waveform alerts. Enter alerts are reshaped into 2D information akin to completely different intervals, and period-aware characteristic extraction is carried out utilizing 2D convolutions and ResNet Blocks. The mannequin handles a number of intervals by using prime numbers to keep away from overlaps and guarantee complete characteristic extraction. For top-frequency modeling, DWT is used to separate the waveform into a number of frequency bands, with specialised estimators for every band. Moreover, FreeU is included to scale down high-frequency elements in skip connections, lowering noise and bettering total waveform high quality. The tactic is skilled on datasets comparable to LJSpeech and LibriTTS and optimized utilizing the AdamW optimizer.
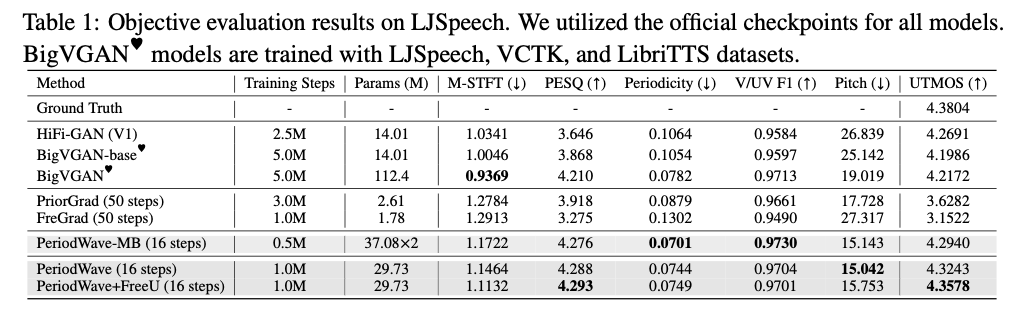
PeriodWave demonstrates superiority over current fashions in each goal and subjective metrics. On the LJSpeech dataset, it achieves exceptional efficiency enhancements throughout numerous metrics, together with M-STFT, PESQ, periodicity, and pitch accuracy, outperforming state-of-the-art fashions like BigVGAN and HiFi-GAN with considerably fewer coaching steps. For example, PeriodWave+FreeU achieves a PESQ rating of 4.293 and a pitch error distance of 15.753, surpassing BigVGAN’s PESQ rating of 4.210 and pitch error distance of 19.019. The power to generate high-quality waveforms with decreased coaching time (solely three days) highlights its effectivity. Moreover, it reveals robustness in out-of-distribution eventualities, performing properly on the MUSDB18-HQ dataset, which incorporates numerous audio varieties past speech, additional demonstrating versatility and robustness in real-world functions.
In conclusion, PeriodWave represents a groundbreaking development in waveform era, providing a novel period-aware move matching method that captures the pure periodicity of high-resolution alerts successfully. The tactic addresses limitations in current GAN-based and diffusion-based methods by introducing improvements comparable to multi-period estimation, DWT for frequency disentanglement, and FreeU for noise discount. Outcomes reveal that PeriodWave not solely enhances the standard of generated waveforms but in addition considerably reduces coaching time, making it an environment friendly and sensible answer for functions in TTS, audio era, and past. PeriodWave represents a major step ahead in AI-driven audio synthesis, offering a sturdy and scalable software able to probably changing typical neural vocoders in numerous functions.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.



