
Computational social science (CSS) leverages superior computational methods to research and interpret huge quantities of social knowledge. This subject more and more depends on pure language processing (NLP) strategies to deal with unstructured textual content knowledge. Nonetheless, whereas massive language fashions (LLMs) have revolutionized CSS by enabling speedy and complex textual content evaluation, their integration into sensible functions stays a fancy problem. This complexity arises from varied constraints, together with excessive prices, knowledge privateness considerations, and the restrictions imposed by community infrastructures, notably in resource-constrained or delicate environments.
As a consequence of these limitations, a major downside in CSS is deploying LLMs in real-world functions. LLMs require substantial computational sources and sometimes face obstacles associated to cost-effectiveness and knowledge safety, particularly when organizations depend on exterior APIs. Though highly effective, these fashions are solely typically dependable when utilized to out-of-domain knowledge. This unreliability is especially problematic for supervised studying fashions, that are important for a lot of CSS duties however demand in depth knowledge labeling—a time-consuming and costly course of. The necessity for an answer that balances the capabilities of LLMs with the practicalities of deploying fashions in constrained environments has turn into more and more pressing.
Present strategies for CSS duties, reminiscent of stance detection, misinformation identification, and beliefs classification, sometimes contain LLMs on account of their potential to carry out zero-shot classification. Nonetheless, these strategies have limitations. As an example, labeling a dataset like SemEval-16, which consists of two,814 knowledge factors, with a mannequin like GPT-4 may value over USD 30. LLMs need assistance with duties requiring excessive contextual understanding, typically resulting in poor generalization throughout completely different datasets. That is evident within the poor efficiency of cross-dataset stance detection fashions, which fail to generalize successfully regardless of aggregating various datasets. These challenges spotlight the necessity for different approaches to cut back reliance on LLMs whereas sustaining efficiency.
Researchers from the College of Washington, the Military Cyber Institute, and Carnegie Mellon College launched the Fast Edge Deployment for CSS Duties (RED-CT) system to handle these points. This revolutionary system is designed to shortly deploy edge classifiers utilizing LLM-labeled knowledge along side minimal human annotation. The system is particularly tailor-made to be used in environments the place sources are restricted, reminiscent of conditions with restricted community entry or the place value and knowledge privateness are vital considerations. RED-CT goals to optimize using LLMs by lowering their dependency whereas benefiting from their classification capabilities.
The RED-CT system employs a confidence-informed sampling technique that selects LLM-labeled knowledge for human annotation, considerably bettering the accuracy of edge classifiers. This method additionally integrates comfortable labels generated from LLM predictions, that are utilized through the coaching these classifiers. By specializing in the sting surroundings—the place sources like time, computational energy, and connectivity are constrained—RED-CT ensures that CSS duties may be carried out effectively with out over-reliance on LLMs. The modular design permits steady efficiency enchancment as LLMs and different system elements evolve, making it a strong answer for dynamic and difficult environments.
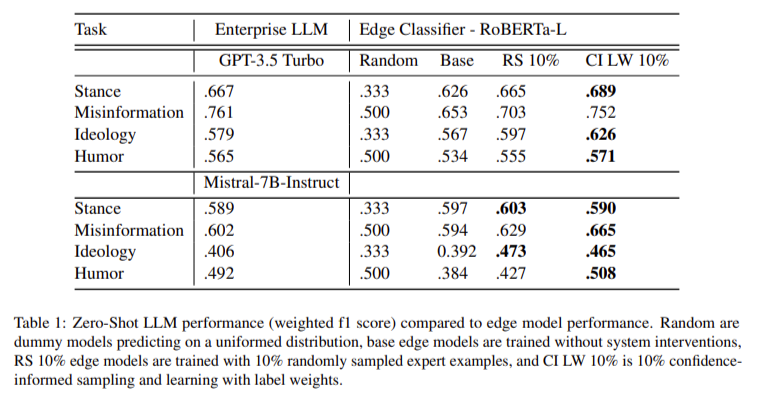
Concerning efficiency, the RED-CT system demonstrated outstanding outcomes throughout varied CSS duties. The researchers evaluated the system utilizing 4 CSS duties: stance detection, misinformation detection, ideology detection, and humor detection. The system outperformed LLM-generated labels in seven of the eight duties examined, with a median enchancment of 6.5% over base classifiers skilled with out system interventions. Particularly, the system confirmed important beneficial properties in duties like stance detection and misinformation identification, the place integrating expert-labeled knowledge and confidence-informed sampling performed a vital function. The RED-CT system’s potential to approximate and even surpass the efficiency of LLMs, notably when minimal human intervention is concerned, highlights its potential for real-world functions.

In conclusion, the RED-CT system affords a strong and environment friendly answer for deploying edge classifiers in CSS duties. By integrating LLM-labeled knowledge with human annotations and revolutionary sampling methods, this technique addresses the vital challenges of utilizing LLMs in constrained environments. The system reduces the dependency on LLMs and enhances efficiency in key areas, making it a priceless instrument for computational social scientists. The numerous enhancements in accuracy and effectivity demonstrated by RED-CT recommend that it may turn into a typical strategy for deploying machine studying fashions in environments with restricted sources, offering a sensible and scalable answer for CSS functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.



