
Imaginative and prescient-language fashions (VLMs) have gained important consideration on account of their potential to deal with varied multimodal duties. Nonetheless, the fast proliferation of benchmarks for evaluating these fashions has created a posh and fragmented panorama. This example poses a number of challenges for researchers. Implementing protocols for quite a few benchmarks is time-consuming, and deciphering outcomes throughout a number of analysis metrics turns into troublesome. The computational assets required to run all out there benchmarks are substantial, main many researchers to judge new fashions on solely a subset of benchmarks. This selective method creates blind spots in understanding mannequin efficiency and complicates comparisons between totally different VLMs. A standardized analysis framework is required to attract significant conclusions about the best methods for advancing VLM know-how. In the end, the sector wants a extra streamlined and complete method to benchmark these fashions.
Researchers from Meta FAIR, Univ Gustave Eiffel, CNRS, LIGM, and Brown College launched a complete framework UniBench, designed to deal with the challenges in evaluating VLMs. This unified platform implements 53 numerous benchmarks in a user-friendly codebase, overlaying a variety of capabilities from object recognition to spatial understanding, counting, and domain-specific medical and satellite tv for pc imagery functions. UniBench categorizes these benchmarks into seven varieties and seventeen finer-grained capabilities, permitting researchers to rapidly establish mannequin strengths and weaknesses in a standardized method.
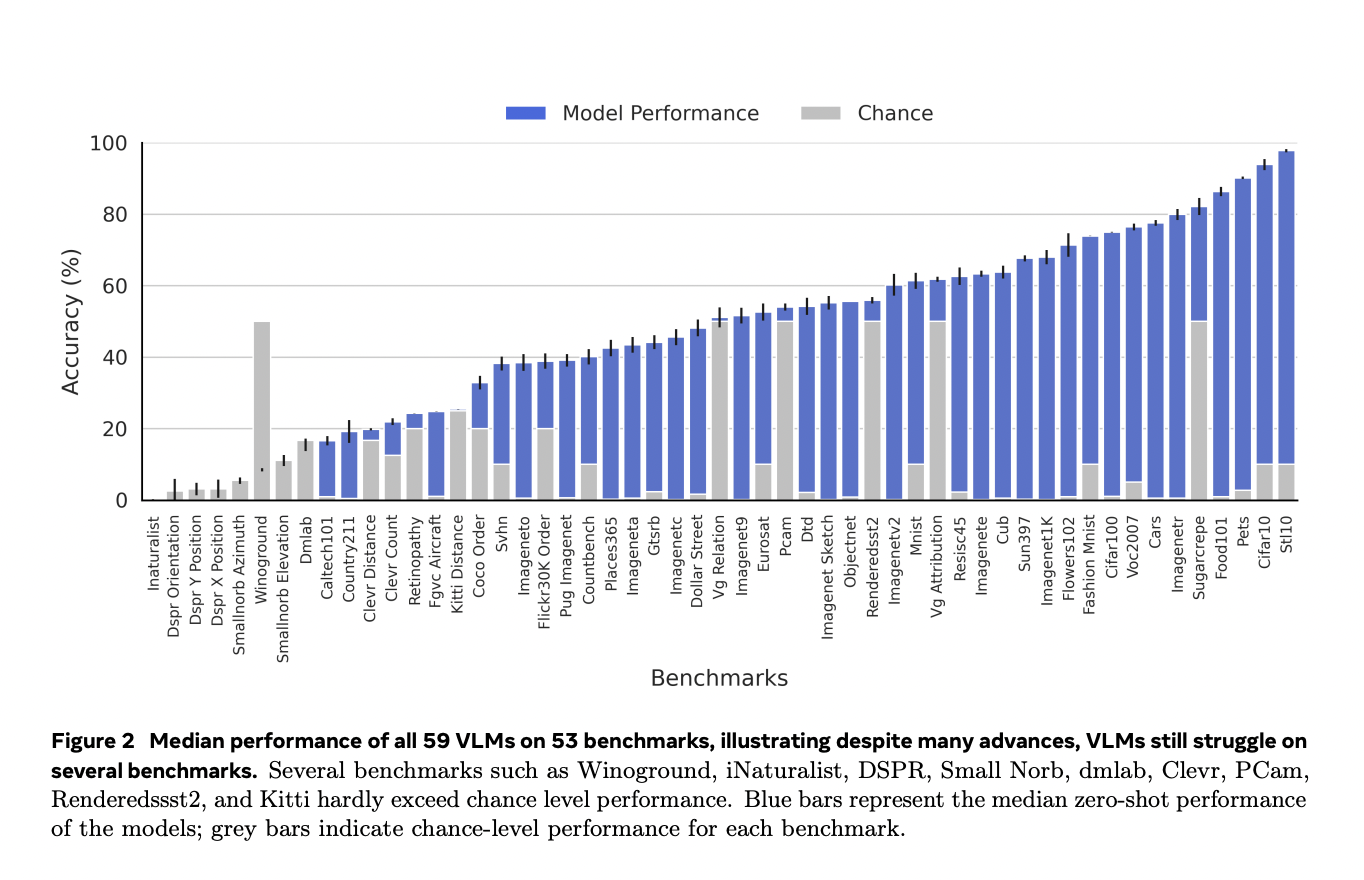
The utility of UniBench is demonstrated via the analysis of almost 60 overtly out there VLMs, encompassing varied architectures, mannequin sizes, coaching dataset scales, and studying aims. This systematic comparability throughout totally different axes of progress reveals that whereas scaling the mannequin dimension and coaching knowledge considerably improves efficiency in lots of areas, it presents restricted advantages for visible relations and reasoning duties. UniBench additionally uncovers persistent struggles in numerical comprehension duties, even for state-of-the-art VLMs.
To facilitate sensible use, UniBench gives a distilled set of consultant benchmarks that may be run rapidly on normal {hardware}. This complete but environment friendly method goals to streamline VLM analysis, enabling extra significant comparisons and insights into efficient methods for advancing VLM analysis.
UniBench demonstrates its utility via a complete analysis of 59 overtly out there VLMs, overlaying a variety of architectures, sizes, and coaching approaches. The framework assesses these fashions throughout 53 numerous benchmarks, categorized into seven varieties and seventeen capabilities. This systematic analysis reveals a number of key insights into VLM efficiency and areas for enchancment.
Outcomes present that scaling mannequin dimension and coaching knowledge considerably enhances efficiency in lots of areas, significantly in object recognition and scene understanding. Nonetheless, this scaling method presents restricted advantages for visible relations and reasoning duties. Additionally, even state-of-the-art VLMs battle with seemingly easy benchmarks involving numerical comprehension, equivalent to character recognition or counting, together with on well-established datasets like MNIST and SVHN.
The analysis highlights that giant open fashions, equivalent to Eva ViT-E/14, carry out properly as general-purpose VLMs. In distinction, specialised fashions like NegCLIP excel in particular duties, significantly visible relations. UniBench’s complete method permits for a nuanced understanding of mannequin strengths and weaknesses, offering invaluable insights for each researchers and practitioners in deciding on applicable fashions for particular functions or figuring out areas for future enchancment in VLM growth.

UniBench’s complete analysis of 59 VLMs throughout 53 numerous benchmarks reveals a number of key insights:
1. Efficiency varies broadly throughout duties. Whereas VLMs excel in lots of areas, they battle with sure benchmarks, performing close to or beneath random likelihood degree on duties like Winoground, iNaturalist, DSPR, Small Norb, dmlab, Clevr, PCam, Renderedssst2, and Kitti.
2. Scaling limitations: Growing mannequin dimension and coaching dataset dimension considerably improves efficiency in lots of areas, significantly object recognition and robustness. Nonetheless, this scaling method presents minimal advantages for visible relations and reasoning duties.
3. Stunning weaknesses: VLMs carry out poorly on historically easy duties like MNIST digit recognition. Even with top-5 accuracy, VLMs barely attain 90% on MNIST, whereas a primary 2-layer MLP achieves 99% accuracy.
4. Counting and numerical duties: VLMs constantly battle with quantity comprehension throughout a number of benchmarks, together with SVHN, CountBench, and ClevrCount.
5. Knowledge high quality over amount: Fashions skilled on 2 billion high-quality samples outperform these skilled on bigger datasets, emphasizing the significance of knowledge curation.
6. Tailor-made aims: Fashions like NegCLIP, with specialised studying aims, considerably outperform bigger fashions on relational understanding duties.
7. Mannequin suggestions: For general-purpose use, giant ViT encoders like Eva-2 ViT-E/14 present one of the best total efficiency. For particular duties like relations or counting, specialised fashions like NegCLIP are beneficial.
UniBench addresses the problem of complete VLM analysis by distilling its 53 benchmarks right into a consultant subset of seven, balancing thoroughness with effectivity. This method overcomes the computational calls for of a full analysis, which requires processing 6 million pictures over 2+ hours on an A100 GPU. Whereas ImageNet correlates with many benchmarks, it poorly represents 18 others, highlighting the necessity for numerous metrics. UniBench’s streamlined set, chosen to signify key axes of progress, runs in simply 5 minutes on a single A100 GPU for a ViT-B/32 mannequin. This environment friendly pipeline presents a sensible resolution for swift but complete VLM evaluation, enabling researchers and practitioners to achieve significant insights rapidly.
This examine introduces UniBench, a complete analysis framework for vision-language fashions that addresses the challenges of fragmented benchmarking within the area. It implements 53 numerous benchmarks, categorized into seven varieties and seventeen capabilities, permitting for systematic evaluation of 59 VLMs. Key findings reveal that whereas scaling mannequin dimension and coaching knowledge improves efficiency in lots of areas, it presents restricted advantages for visible relations and reasoning duties. Surprisingly, VLMs battle with easy numerical duties like MNIST digit recognition. UniBench additionally highlights the significance of knowledge high quality over amount and the effectiveness of tailor-made studying aims. To steadiness thoroughness with effectivity, UniBench presents a distilled set of seven consultant benchmarks, runnable in simply 5 minutes on a single GPU.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.



