Massive language fashions (LLMs) have significantly altered the panorama of pure language processing, enabling machines to grasp and generate human language way more successfully than ever. Usually, these fashions are pre-trained on large and parallel corpora after which fine-tuned to attach them to human duties or preferences. Subsequently, This course of has led to nice advances within the subject that the LLMs have turn into very helpful instruments for various functions, from language translation to sentiment evaluation. Energetic analysis continues to be ongoing to handle the connection between pre-training and fine-tuning since this understanding will result in the additional optimization of the fashions for higher efficiency and utility.
One of many difficult points in coaching the LLMs is the tradeoff between the positive factors within the pre-training stage and the fine-tuning stage. Pre-training has been key in endowing fashions with a broad understanding of language, however it’s typically debatable how optimum this pre-training level is earlier than fine-tuning. Though that is mandatory generally for conditioning the mannequin for a particular process, it could actually generally result in a lack of prior realized data or embedding some biases that have been initially absent throughout the pre-training of the mannequin. It’s a delicate steadiness between conserving basic data and fine-tuning for particular process efficiency.
Present approaches take pre-training and fine-tuning as two separate steps: in pre-training, the mannequin is introduced with a large textual content dataset with an enormous vocabulary, which the mannequin learns to search out the underlying constructions and patterns of language. Superb-tuning continues coaching on smaller, task-specific datasets to make it concentrate on sure duties. A generic pre-training adopted by a task-specific fine-tuning strategy probably can solely fulfill a number of the potential synergies within the two phases. Researchers have began trying into whether or not a extra built-in strategy, during which fine-tuning is launched at a number of crossroads within the pre-training course of, would obtain higher efficiency.
A novel methodology by a analysis group from Johns Hopkins College explored the tradeoff between pre-training and fine-tuning. The authors additional seemed into how continuous pre-training would have an effect on the capabilities of fine-tuned fashions by way of fine-tuning many intermediate checkpoints of a pre-trained mannequin. The experiments have been carried out on big-data, pre-trained, large-scale fashions utilizing checkpoints from totally different phases of the pre-training course of. Superb-tuning checkpoints at varied factors of mannequin growth have been completed by way of a supervised and instruction-based strategy. This novel methodology helped the researchers examine how their mannequin operationalizes at totally different phases of the event course of relative to others, revealing the perfect methods for coaching LLMs.
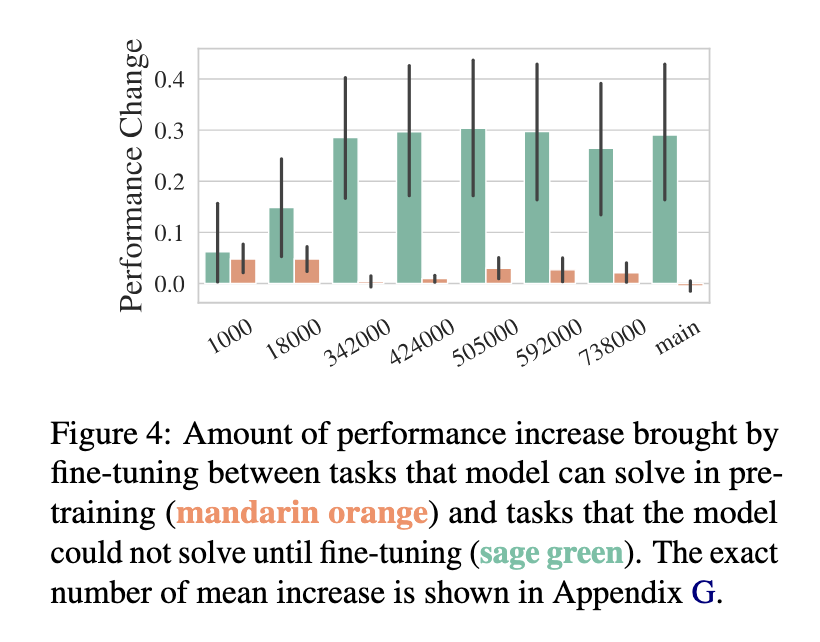
The methodology is deep and discusses the efficiency of the mannequin throughout a number of duties, reminiscent of pure language inference, paraphrase detection, and summarization, over 18 datasets. They concluded that continuous pre-training results in potential hidden methods within the mannequin, revealed solely after fine-tuning. Particularly, in duties to which the mannequin had underperformed at first in pre-training, vital enhancements could possibly be noticed after fine-tuning, with total enchancment for the duties being round within the vary of 10% to 30%. In distinction, features for which the mannequin labored satisfactorily within the pre-training part evidenced much less dramatic enhancements within the fine-tuning part, which means that fine-tuning advantages duties for which it has not adequately been realized beforehand.
Particular refined options related to the fine-tuning course of have been additionally revealed throughout the examine. Whereas fine-tuning typically enhances the mannequin’s efficiency, on the different finish, it causes the mannequin to neglect the already realized data as a result of, more often than not, this occurs when the fine-tuning goal is mismatched with the pre-training goal, the place this regards the duties, being in a roundabout way associated to the targets of fine-tuning. For instance, after fine-tuning a number of pure language inference duties, the mannequin deteriorates when evaluated on a paraphrase identification process. These behaviors have proven a tradeoff between enhancing the fine-tuned process and having extra basic capabilities. Experimentally, they present that this type of forgetting will be partly alleviated by persevering with the large pre-training steps throughout the fine-tuning phases, which protect the big mannequin’s data base.

The efficiency outcomes of the fine-tuned fashions have been fascinating. Within the pure language inference duties, the fine-tuned mannequin confirmed a prime efficiency of 25% in contrast with the pre-trained-only mannequin. The accuracy of the paraphrase detection process improved by 15%, whereas it improved by about 20% for each summarization duties. These outcomes strongly underscore the significance of fine-tuning about actually unlocking the complete potential of pre-trained fashions, particularly in instances whereby the baseline mannequin performs poorly.
In conclusion, this work by Johns Hopkins College researchers could be very fascinating in that it supplies perception into the dynamic relationship between pre-training and fine-tuning in extra LLMs. You will need to observe up after laying a robust basis in a preliminary stage; with out it, the fine-tuning modeling course of is not going to enhance the power of the mannequin. The analysis exhibits that the appropriate steadiness between these two phases exists in performances, promising additional new instructions for NLP. This new path will doubtlessly result in the effectiveness of coaching paradigms that concurrently apply pre-training and fine-tuning in a manner that advantages extra highly effective and versatile language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.