
Successfully aligning massive language fashions (LLMs) with human directions is a crucial problem within the discipline of AI. Present LLMs usually wrestle to generate responses which are each correct and contextually related to consumer directions, notably when counting on artificial knowledge. Conventional strategies, similar to mannequin distillation and human-annotated datasets, have their very own limitations, together with scalability points and an absence of information variety. Addressing these challenges is important for enhancing the efficiency of AI techniques in real-world purposes, the place they need to interpret and execute a variety of user-defined duties.
Present approaches to instruction alignment primarily depend on human-annotated datasets and artificial knowledge generated by means of mannequin distillation. Whereas human-annotated knowledge is excessive in high quality, it’s costly and troublesome to scale. However, artificial knowledge, usually produced by way of distillation from bigger fashions, tends to lack variety and will result in fashions that overfit to particular sorts of duties, thereby limiting their skill to generalize to new directions. These limitations, together with excessive prices and the “false promise” of distillation, hinder the event of sturdy, versatile LLMs able to dealing with a broad spectrum of duties.
A group of researchers from College of Washington and Meta Truthful suggest a novel technique often called “instruction back-and-forth translation.” This strategy enhances the era of artificial instruction-response pairs by integrating backtranslation with response rewriting. Initially, directions are generated from pre-existing responses extracted from large-scale net corpora. These responses are then refined by an LLM, which rewrites them to raised align with the generated directions. This modern technique leverages the wealthy variety of knowledge obtainable on the net whereas guaranteeing high-quality, instruction-following knowledge, marking a big development within the discipline.
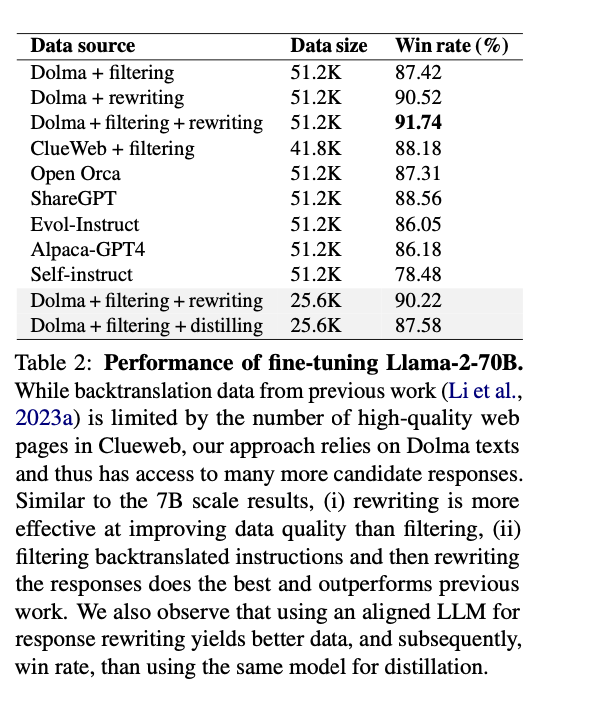
The strategy includes fine-tuning a base LLM on seed knowledge to create directions that match web-scraped responses. The Dolma corpus, a large-scale open-source dataset, supplies the supply of those responses. After producing the preliminary instruction-response pairs, a filtering step retains solely the best high quality pairs. An aligned LLM, similar to Llama-2-70B-chat, then rewrites the responses to additional improve their high quality. Nucleus sampling is employed for response era, with a deal with each filtering and rewriting to make sure knowledge high quality. Testing in opposition to a number of baseline datasets reveals superior efficiency for fashions fine-tuned on artificial knowledge generated by means of this method.
This new technique achieves vital enhancements in mannequin efficiency throughout numerous benchmarks. Fashions fine-tuned utilizing the Dolma + filtering + rewriting dataset attain a win fee of 91.74% on the AlpacaEval benchmark, surpassing fashions skilled on different prevalent datasets similar to OpenOrca and ShareGPT. Moreover, it outperforms earlier approaches utilizing knowledge from ClueWeb, demonstrating its effectiveness in producing high-quality, various instruction-following knowledge. The improved efficiency underscores the success of the back-and-forth translation approach in producing better-aligned and extra correct massive language fashions.
In conclusion, the introduction of this new technique for producing high-quality artificial knowledge marks a big development in aligning LLMs with human directions. By combining back-translation with response rewriting, researchers have developed a scalable and efficient strategy that improves the efficiency of instruction-following fashions. This development is essential for the AI discipline, providing a extra environment friendly and correct resolution for instruction alignment, which is important for deploying LLMs in sensible purposes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.



