
Giant language fashions (LLMs) have made important strides in mathematical reasoning and theorem proving, but they face appreciable challenges in formal theorem proving utilizing methods like Lean and Isabelle. These methods demand rigorous derivations that adhere to strict formal specs, posing difficulties even for superior fashions comparable to GPT-4. The core problem lies within the mannequin’s have to concurrently comprehend the syntax and semantics of formal methods whereas aligning summary mathematical reasoning with exact formal representations. This complicated activity requires a deep understanding of coding intricacies and mathematical ideas, creating a big hurdle for present AI methods in producing complicated formal proofs.
Researchers from DeepSeek-AI launched DeepSeek-Prover-V1.5, a unified strategy that mixes the strengths of proof-step and whole-proof era strategies by a sturdy truncate-and-resume mechanism. This technique begins with whole-proof era, the place the language mannequin produces full proof code primarily based on the concept assertion. The Lean prover then verifies this code. If an error is detected, the code is truncated on the first error message, and the efficiently generated portion serves as a immediate for the following proof section. The newest state from the Lean 4 prover is appended as a remark to the immediate to boost accuracy. The truncate-and-resume mechanism is built-in into the Monte-Carlo tree search (MCTS), permitting for versatile truncation factors decided by the tree search coverage. Additionally, a reward-free exploration algorithm is proposed to deal with the reward sparsity problem in proof search, assigning intrinsic motivation to the tree search agent for intensive exploration of the tactic state area.
This research presents the next contributions:
• Pre-Coaching: Enhanced base mannequin with additional coaching on arithmetic and code information, specializing in formal languages like Lean, Isabelle, and Metamath.
• Supervised Wonderful-Tuning: Improved Lean 4 code completion dataset by two information augmentation strategies:
1. Used DeepSeek-Coder V2 236B so as to add pure language chain-of-thought feedback.
2. Inserted intermediate tactic state data inside Lean 4 proof code.
• Reinforcement Studying: Employed GRPO algorithm for reinforcement studying from proof assistant suggestions (RLPAF), utilizing Lean prover verification outcomes as rewards.
• Monte-Carlo Tree Search: Superior tree search technique with:
1. Truncate-and-resume mechanism as state-action abstraction.
2. RMaxTS algorithm, using RMax technique for exploration in sparse-reward proof search.
3. Assigned intrinsic rewards to encourage various planning paths and intensive proof area exploration.
DeepSeek-Prover-V1.5 demonstrates important developments in formal theorem proving throughout a number of benchmarks. On the miniF2F-test dataset, DeepSeek-Prover-V1.5-RL achieved a 60.2% go price in a single-pass whole-proof era, marking a ten.2 share level enchancment over its predecessor. With a restricted sampling funds of 128 makes an attempt, it proved 51.6% of issues, outperforming different whole-proof era strategies and matching main tree search strategies. When enhanced with RMaxTS tree search, DeepSeek-Prover-V1.5-RL achieved a state-of-the-art 62.7% go price. Additionally, it surpassed the earlier finest outcome with considerably fewer samplings. On the ProofNet dataset, DeepSeek-Prover-V1.5-RL achieved go charges of twenty-two.6% and 25.3% in single-pass and RMaxTS-enhanced settings respectively, outperforming present strategies. These outcomes show DeepSeek-Prover-V1.5’s superior efficiency throughout totally different theorem-proving duties and methodologies.
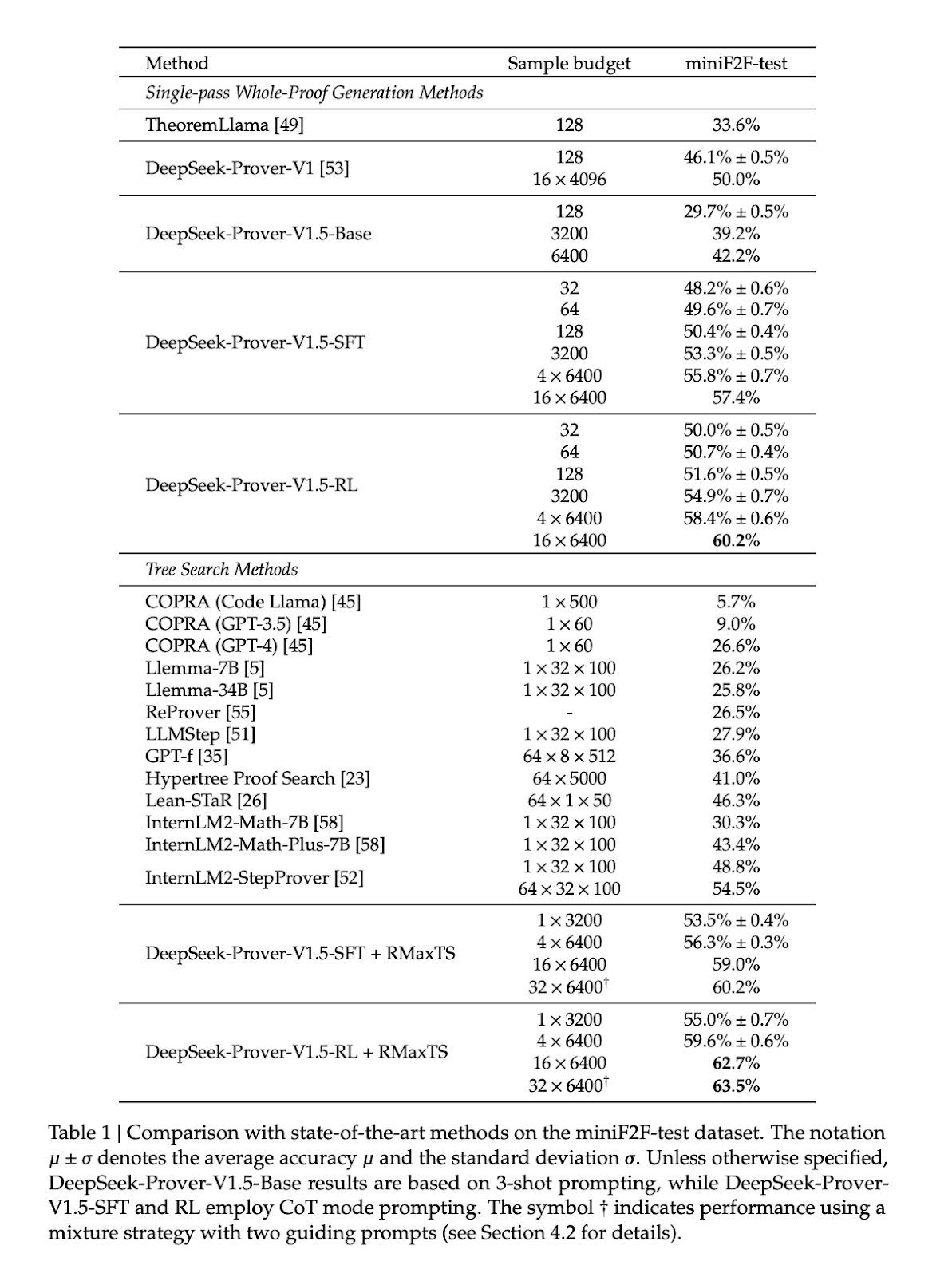
DeepSeek-Prover-V1.5, a 7 billion parameter language mannequin, units new benchmarks in formal theorem proving utilizing Lean 4. Constructed on DeepSeek-Prover-V1.5-Base, it undergoes specialised pre-training, complete supervised fine-tuning, and reinforcement studying through GRPO. The mannequin incorporates RMaxTS, an revolutionary Monte-Carlo tree search variant, to boost problem-solving by intensive exploration. This framework establishes an AlphaZero-like pipeline for formal theorem proving, using knowledgeable iteration and artificial information. Whereas the present focus is on exploration, future developments could embrace a critic mannequin for assessing incomplete proofs, addressing the exploitation side of reinforcement studying in theorem proving.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.



