
Pure Language Processing (NLP), regardless of its progress, faces the persistent problem of hallucination, the place fashions generate incorrect or nonsensical info. Researchers have launched Retrieval-Augmented Era (RAG) techniques to mitigate this difficulty by incorporating exterior info retrieval to boost the accuracy of generated responses.
The issue, nevertheless, is the reliability and effectiveness of RAG techniques in offering correct responses throughout completely different domains. Present benchmarks primarily deal with common information however want to enhance in evaluating the efficiency of RAG fashions in specialised fields like finance, healthcare, and authorized sectors. This limitation arises from the problem in curating high-quality datasets that may comprehensively take a look at the fashions’ skill to deal with domain-specific info.
Present strategies for evaluating RAG techniques embody established NLP metrics reminiscent of F1, BLEU, ROUGE-L, and EM for reply era and Hit Price, MRR, and NDCG for retrieval evaluation. More moderen approaches use LLM-generated knowledge to guage contextual relevance, faithfulness, and informativeness. Nonetheless, these metrics typically lack the nuance required for assessing the generative capabilities of RAG techniques in vertical domains. Consequently, a extra strong analysis framework is important to handle these shortcomings and supply an in depth evaluation of RAG efficiency in specialised areas.
Researchers from Tsinghua College, Beijing Regular College, College of Chinese language Academy of Sciences, and Northeastern College launched the RAGEval framework to handle these challenges. This framework mechanically generates analysis datasets tailor-made to particular situations in varied vertical domains. The method begins by summarizing a schema from seed paperwork, producing numerous paperwork and setting up question-answering pairs based mostly on these configurations. The framework then evaluates the mannequin responses utilizing novel metrics specializing in factual accuracy.
The proposed technique, RAGEval, employs a “schema-configuration-document-QAR-keypoint” pipeline to make sure the robustness and reliability of the analysis course of. This entails producing a schema that encapsulates important domain-specific information, creating configurations from this schema, and producing numerous paperwork. These paperwork are then used to generate questions and reference solutions, forming QAR triples evaluated for completeness, hallucination, and irrelevance. This complete method ensures that the analysis datasets are wealthy in factual info and logical coherence.
A hybrid method is used to generate these configurations, combining rule-based and LLM-based strategies to assign values to the schema components. Rule-based strategies guarantee excessive accuracy and consistency, significantly for structured knowledge, whereas LLMs are used to generate extra advanced or numerous content material. This technique produces a variety of high-quality, numerous configurations, guaranteeing the generated paperwork are correct and contextually related.
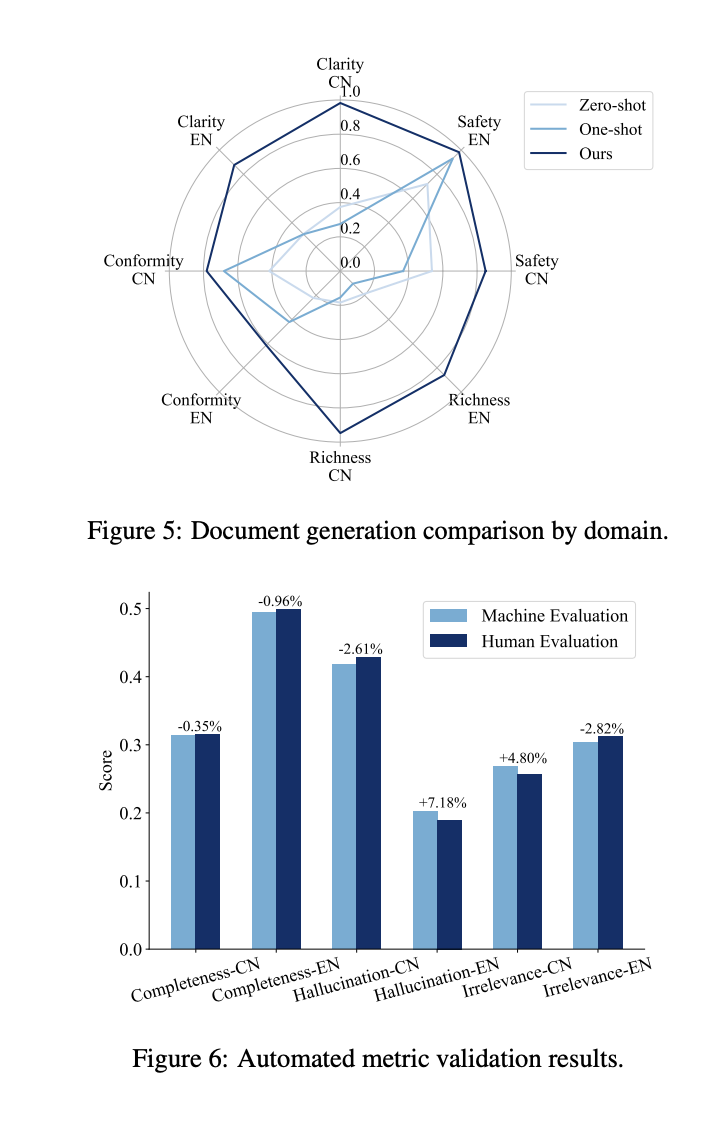
Experimental outcomes demonstrated that the RAGEval framework is extremely efficient in producing correct, protected, and wealthy content material throughout varied domains. The human analysis outcomes highlighted the robustness of this technique, displaying that the generated paperwork had been clear, particular, and intently resembled real-world paperwork. Furthermore, the validation of automated analysis metrics confirmed a excessive diploma of alignment with human judgment, confirming the reliability of those metrics in reflecting mannequin efficiency.
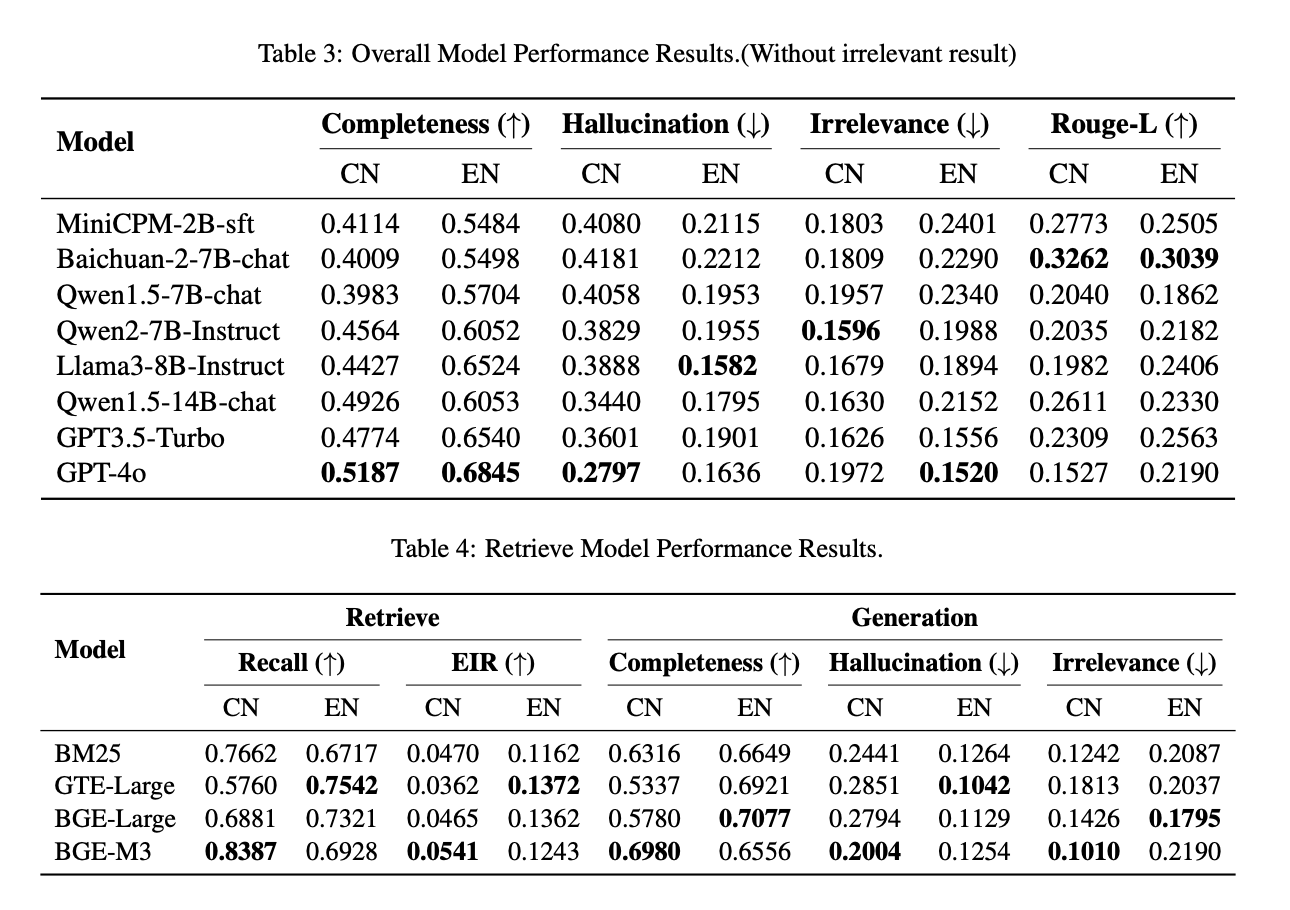
GPT-4o carried out higher total, attaining the best Completeness scores of 0.5187 for Chinese language and 0.6845 for English. Nonetheless, the hole with top-performing open-source fashions, reminiscent of Qwen1.5-14B-chat and Llama3-8B-Instruct, was comparatively small. Qwen1.5-14B-chat achieved a Completeness rating of 0.4926 in Chinese language, whereas Llama3-8B-Instruct scored 0.6524 in English. These outcomes counsel that with additional developments, open-source fashions have vital potential to shut the efficiency hole with proprietary fashions.
In conclusion, the RAGEval framework affords a sturdy answer for evaluating RAG techniques, addressing the constraints of current benchmarks by specializing in domain-specific factual accuracy. This method enhances the reliability of RAG fashions in varied industries and paves the way in which for future enhancements in proprietary and open-source fashions. For greatest outcomes, researchers and builders are inspired to leverage frameworks like RAGEval to make sure their fashions meet the particular wants of their software domains.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



