Researchers from ETH Zurich discover simplifications within the design of deep Transformers, aiming to make them extra sturdy and environment friendly. Modifications are proposed by combining sign propagation idea and empirical observations, enabling the removing of varied elements from customary transformer blocks with out compromising coaching velocity or efficiency.
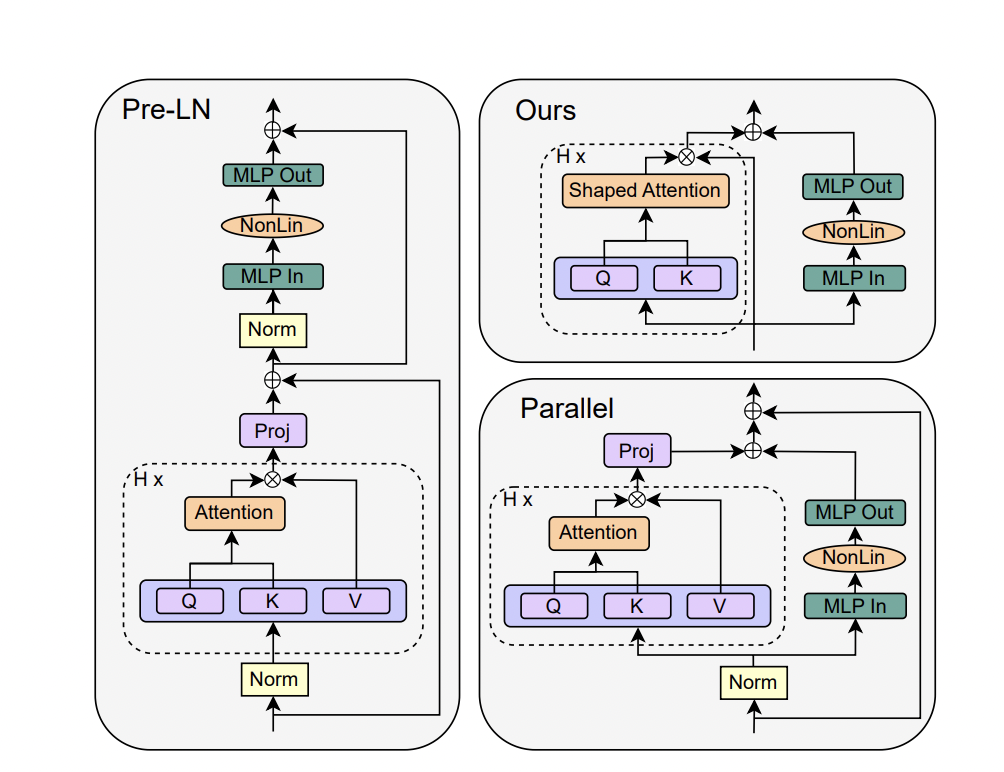
The analysis presents a research on simplifying transformer blocks in deep neural networks, particularly specializing in the usual transformer block. Drawing inspiration from sign propagation idea, it explores the association of an identical constructing blocks, incorporating consideration and MLP sub-blocks with skip connections and normalization layers. It additionally introduces the parallel block, which computes the MLP and a focus sub-blocks in parallel for improved effectivity.
The research examines the simplification of transformer blocks in deep neural networks, focusing particularly on the usual transformer block. It investigates the need of varied elements inside the block and explores the potential of eradicating them with out compromising coaching velocity. The motivation for simplification arises from the complexity of contemporary neural community architectures and the hole between idea and observe in deep studying.
The strategy combines sign propagation idea and empirical observations to suggest modifications for simplifying transformer blocks. The research carried out experiments on autoregressive decoder-only and BERT encoder-only fashions to evaluate the efficiency of the simplified transformers. It performs further experiments and ablations to check the influence of eradicating skip connections within the consideration sub-block and the ensuing sign degeneracy.
The analysis proposed modifications to simplify transformer blocks by eradicating skip connections, projection/worth parameters, sequential sub-blocks, and normalization layers. These modifications keep customary transformers’ coaching velocity and efficiency whereas reaching quicker coaching throughput and using fewer parameters. The research additionally investigated the influence of various initialization strategies on the efficiency of simplified transformers.
The proposed simplified transformers obtain comparable efficiency to plain transformers whereas utilizing 15% fewer parameters and experiencing a 15% improve in coaching throughput. The research presents simplified deep-learning architectures that may scale back the price of giant transformer fashions. The experimental outcomes assist the effectiveness of the simplifications throughout varied settings and emphasize the importance of correct initialization for optimum outcomes.
The really helpful future analysis is to research the effectiveness of the proposed simplifications on bigger transformer fashions, because the research primarily centered on comparatively small fashions in comparison with the most important transformers. It additionally suggests conducting a complete hyperparameter search to boost the efficiency of the simplified blocks, because the research solely tuned key hyperparameters and relied on default selections. It proposes exploring hardware-specific implementations of the simplified blocks to realize further enhancements in coaching velocity and efficiency doubtlessly.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to affix our 32k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E-mail Publication, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you happen to like our work, you’ll love our publication..
We’re additionally on Telegram and WhatsApp.
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and need to create new merchandise that make a distinction.


