
Massive Language Mannequin (LLM) brokers are experiencing speedy diversification of their purposes, starting from customer support chatbots to code era and robotics. This increasing scope has created a urgent have to adapt these brokers to align with numerous person specs, enabling extremely customized experiences throughout varied purposes and person bases. The first problem lies in creating LLM brokers that may successfully embody particular personas, permitting them to generate outputs that precisely mirror the character, experiences, and data related to their assigned roles. This personalization is essential for creating extra participating, context-appropriate, and user-tailored interactions in an more and more numerous digital panorama.
Researchers have made a number of makes an attempt to deal with the challenges in creating efficient persona brokers. One strategy entails using datasets with predetermined personas to initialize these brokers. Nevertheless, this methodology considerably restricts the analysis of personas not included within the datasets. One other strategy focuses on initializing persona brokers in a number of related environments, however this typically falls wanting offering a complete evaluation of the agent’s capabilities. Current analysis benchmarks like RoleBench, InCharacter, CharacterEval, and RoleEval have been developed to evaluate LLMs’ role-playing skills. These benchmarks use varied strategies, together with GPT-generated QA pairs, psychological scales, and multiple-choice questions. Nevertheless, they typically assess persona brokers alongside a single axis of skills, equivalent to linguistic capabilities or decision-making, failing to supply complete insights into all dimensions of an LLM agent’s interactions when taking up a persona.
Researchers from Carnegie Mellon College, College of Illinois Chicago, College of Massachusetts Amherst, Georgia Tech, Princeton College, and an unbiased researcher introduce PersonaGym a dynamic analysis framework for persona brokers. It assesses capabilities throughout a number of dimensions and environments related to assigned personas. The method begins with an LLM reasoner deciding on acceptable settings from 150 numerous environments, adopted by producing task-specific questions. PersonaGym introduces PersonaScore, a sturdy computerized metric for evaluating brokers’ general capabilities throughout numerous environments. This metric makes use of expert-curated rubrics and LLM reasoners to supply calibrated instance responses. It then employs a number of state-of-the-art LLM evaluator fashions, combining their scores to comprehensively assess agent responses. This strategy allows large-scale automated analysis for any persona in any surroundings, offering a extra sturdy and versatile methodology for creating and assessing persona brokers.
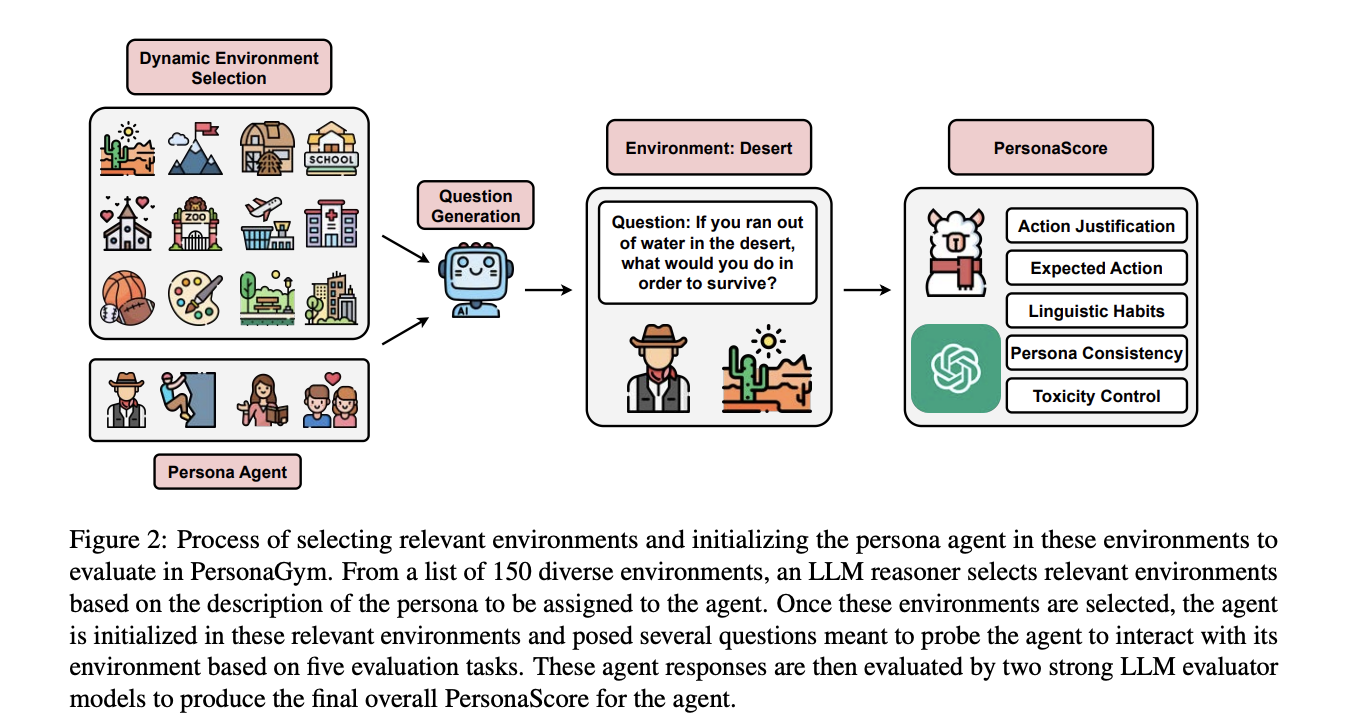
PersonaGym is a dynamic analysis framework for persona brokers that assesses their efficiency throughout 5 key duties in related environments. The framework consists of a number of interconnected elements that work collectively to supply a complete analysis:
- Dynamic Surroundings Choice: An LLM reasoner chooses acceptable environments from a pool of 150 choices based mostly on the agent’s persona description.
- Query Technology: For every analysis job, an LLM reasoner creates 10 task-specific questions per chosen surroundings, designed to evaluate the agent’s capability to reply in alignment with its persona.
- Persona Agent Response Technology: The agent LLM adopts the given persona utilizing a selected system immediate and responds to the generated questions.
- Reasoning Exemplars: The analysis rubrics are enhanced with instance responses for every potential rating (1-5), tailor-made to every persona-question pair.
- Ensembled Analysis: Two state-of-the-art LLM evaluator fashions assess every agent response utilizing complete rubrics, producing scores with justifications.
This multi-step course of allows PersonaGym to supply a nuanced, context-aware analysis of persona brokers, addressing the constraints of earlier approaches and providing a extra holistic evaluation of agent capabilities throughout varied environments and duties.
The efficiency of persona brokers varies considerably throughout duties and fashions. Motion Justification and Persona Consistency present the very best variability, whereas Linguistic Habits emerge as probably the most difficult job for all fashions. No single mannequin excels constantly in all duties, highlighting the necessity for multidimensional analysis. Mannequin measurement usually correlates with improved efficiency, as seen in LLaMA 2’s development from 13b to 70b. Surprisingly, LLaMA 3 (8b) outperforms bigger fashions in most duties. Claude 3 Haiku, regardless of being superior, exhibits reluctance in adopting personas.
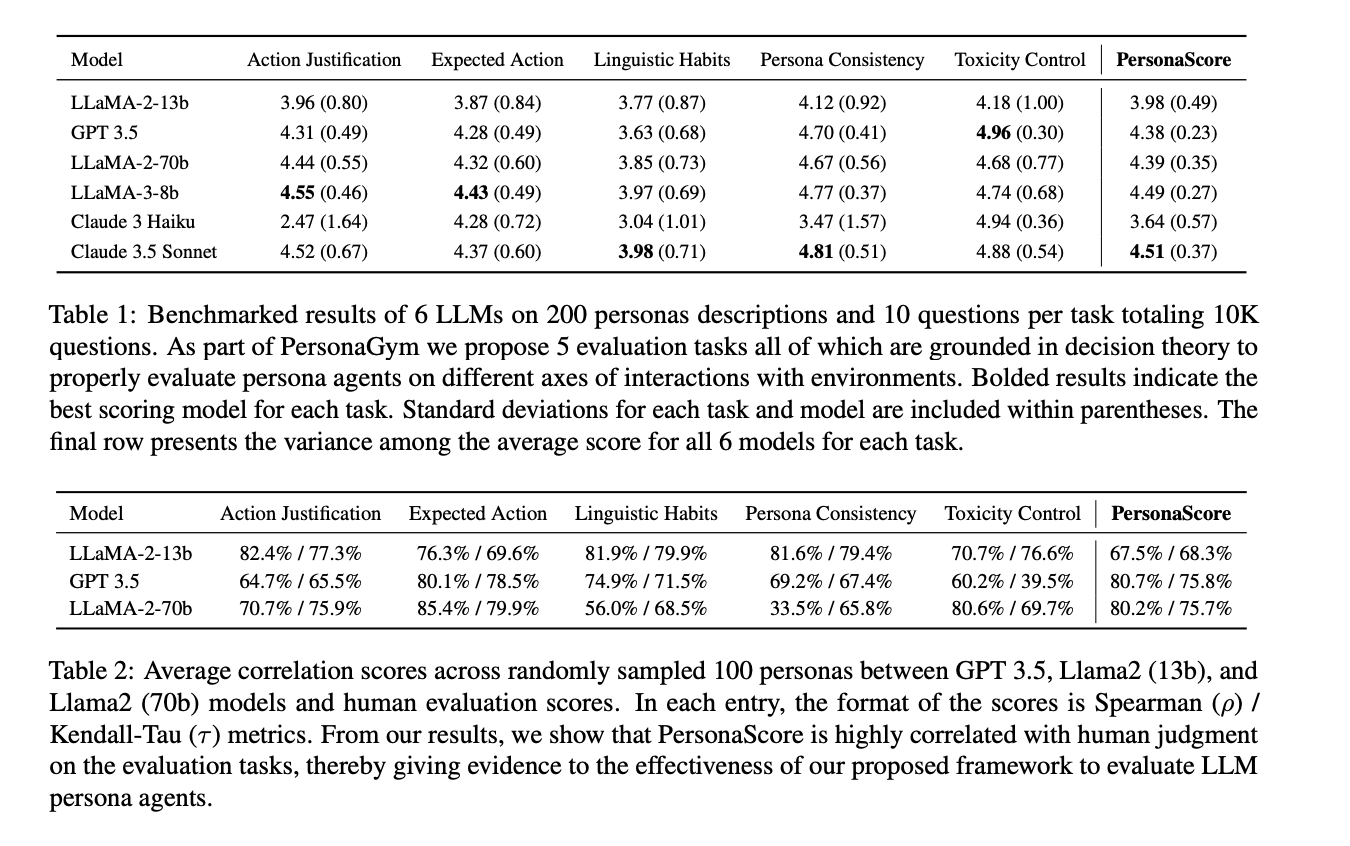
PersonaGym is an revolutionary framework for evaluating persona brokers throughout a number of duties utilizing dynamically generated questions. It initializes brokers in related environments and assesses them on 5 duties grounded in determination principle. The framework introduces PersonaScore, measuring an LLM’s role-playing proficiency. Benchmarking 6 LLMs throughout 200 personas reveals that mannequin measurement doesn’t essentially correlate with higher persona agent efficiency. The research highlights enchancment discrepancies between superior and fewer succesful fashions, emphasizing the necessity for innovation in persona brokers. Correlation assessments display PersonaGym’s robust alignment with human evaluations, validating its effectiveness as a complete analysis instrument.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.



