Giant Language Fashions (LLMs) have revolutionized pure language processing, demonstrating distinctive efficiency throughout numerous duties. The Scaling Legislation means that as mannequin dimension will increase, LLMs develop emergent skills, enhancing their context understanding and lengthy sequence dealing with capabilities. This progress allows LLMs to generate coherent responses and energy functions like doc summarization, code era, and conversational AI. Nevertheless, LLMs face vital challenges when it comes to value and effectivity. The bills related to LLM era escalate with growing mannequin dimension and sequence size, affecting each the coaching and inference levels. Moreover, managing lengthy sequences presents computational burdens because of the quadratic complexity of the transformer consideration mechanism, which scales poorly with sequence size. These challenges necessitate the event of environment friendly LLM architectures and techniques to scale back reminiscence consumption, notably in long-context eventualities.
Present researchers have pursued numerous approaches to handle the computational challenges posed by LLMs, notably in long-context eventualities. KV cache eviction strategies like StreamingLLM, H2O, SnapKV, and FastGen intention to scale back reminiscence utilization by selectively retaining or discarding tokens primarily based on their significance. PyramidKV and PyramidInfer suggest adjusting KV cache sizes throughout completely different layers. KV cache quantization methods, similar to SmoothQuant and Q-Hitter, compress the cache whereas minimizing efficiency loss. Some research recommend completely different quantization methods for key and worth caches. Structured pruning of LLMs has additionally been explored, specializing in eradicating unimportant layers, heads, and hidden dimensions. Nevertheless, these strategies typically end in vital efficiency degradation or fail to take advantage of potential optimizations absolutely.
Researchers from Salesforce AI Analysis and The Chinese language College of Hong Kong suggest ThinK, a novel KV cache pruning methodology that approaches the duty as an optimization downside to reduce consideration weight reduction from pruning. It introduces a query-dependent criterion for assessing channel significance and selects vital channels greedily. The tactic is based on key observations from LLaMA3-8B mannequin visualizations: key cache channels present various magnitudes of significance, whereas worth cache lacks clear patterns. The singular worth decomposition of consideration matrices reveals that few singular values carry excessive vitality, indicating the eye mechanism’s low-rank nature. These insights recommend that key cache could be successfully approximated utilizing low-dimensional vectors. ThinK makes use of these findings to develop an environment friendly pruning technique focusing on the important thing cache’s channel dimension, probably decreasing reminiscence consumption whereas preserving mannequin efficiency.
ThinK is an progressive methodology for optimizing the KV cache in LLMs by pruning the channel dimension of the important thing cache. The strategy formulates the pruning process as an optimization downside, aiming to reduce the distinction between unique and pruned consideration weights. ThinK introduces a query-driven pruning criterion that evaluates channel significance primarily based on the interplay between the question and key vectors. This methodology makes use of a grasping algorithm to pick out an important channels, preserving the first info stream within the consideration computation.
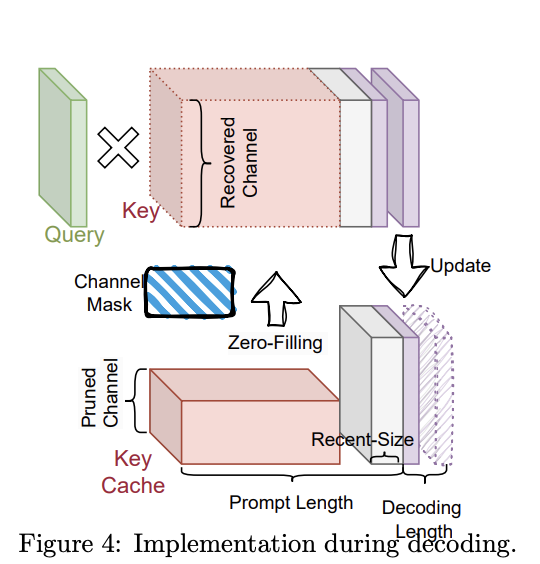
The implementation focuses on long-context eventualities and employs an statement window to scale back computational prices. ThinK maintains two classes of keys within the KV cache: pruned keys with decreased channel dimension and unpruned keys at unique dimension. A binary masks tracks pruned channels. Throughout decoding, pruned keys are zero-filled and concatenated with unpruned keys, or the question is pruned earlier than multiplication with the corresponding keys. This strategy could be built-in with optimization methods like FlashAttention, probably providing improved computational effectivity whereas sustaining mannequin efficiency.
The experimental outcomes show the effectiveness of ThinK, a novel key cache pruning methodology, throughout two main benchmarks: LongBench and Needle-in-a-Haystack. Key findings embody:
- ThinK efficiently prunes key cache channels after making use of current compression strategies (H2O and SnapKV), decreasing reminiscence utilization whereas sustaining or barely enhancing efficiency on LLaMA3-8B. For Mistral-7B, it reduces reminiscence with minimal efficiency influence.
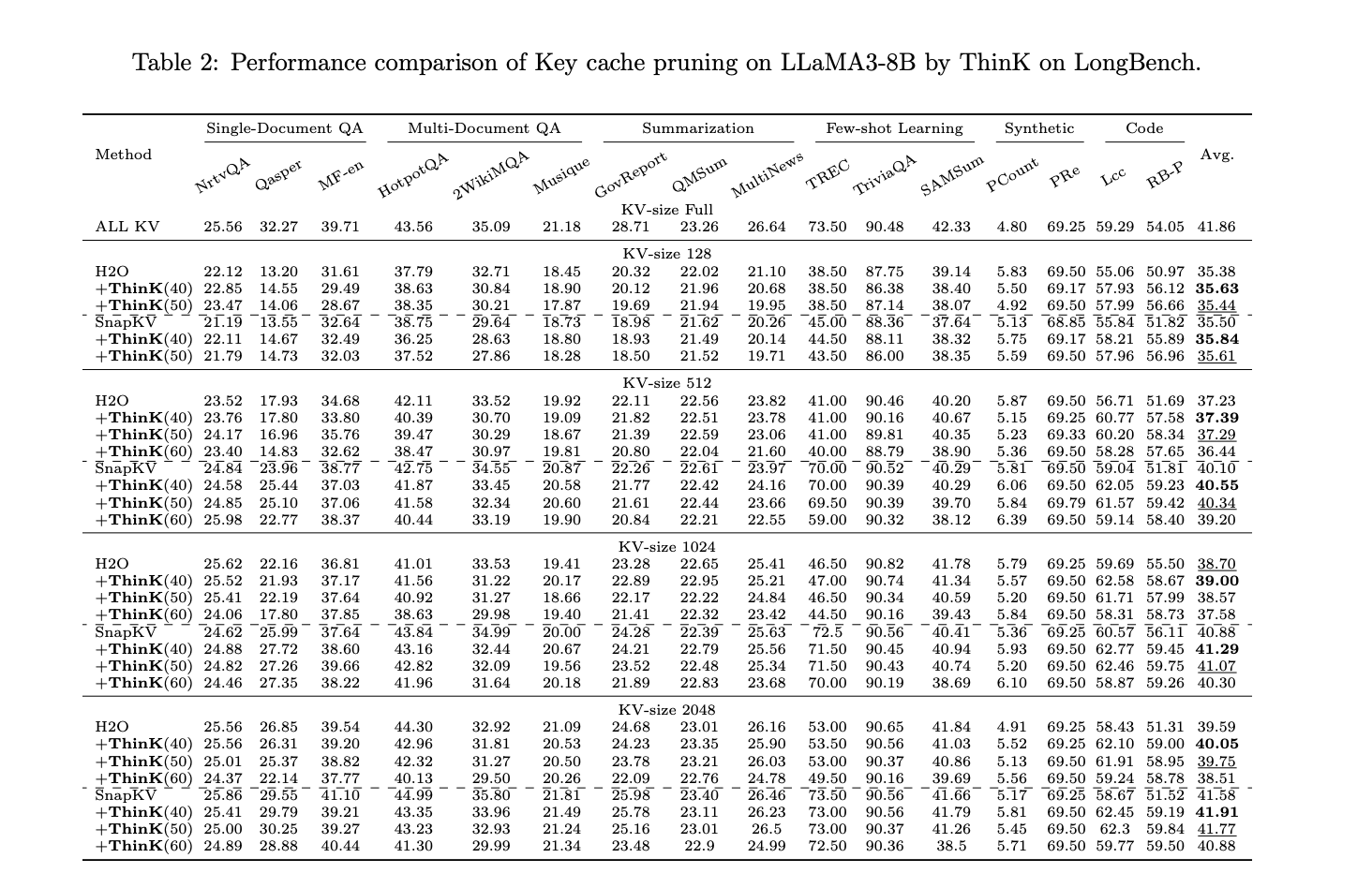
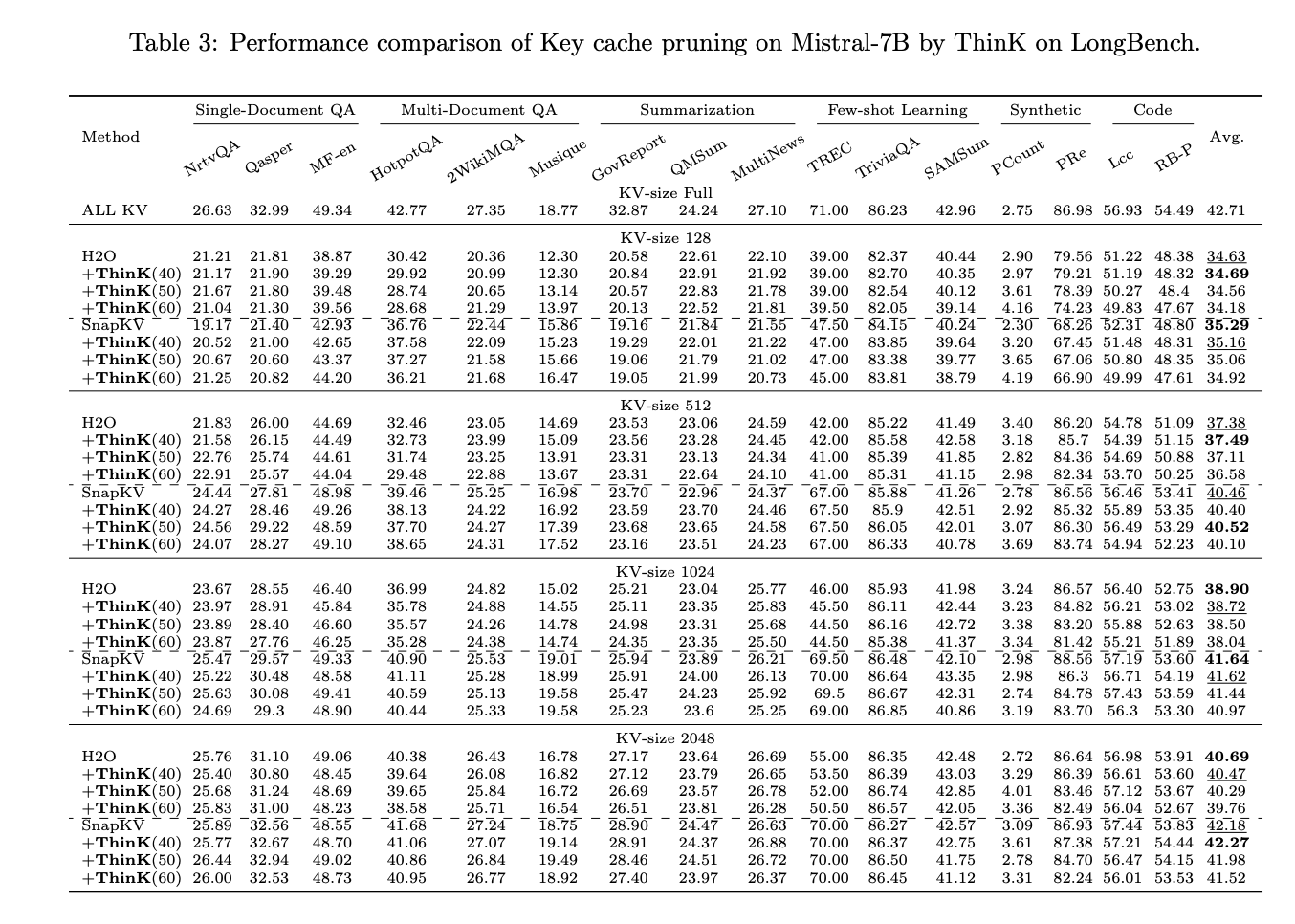
- Question-based channel pruning (ThinK) outperforms l1 and l2 norm-based pruning strategies, particularly at a 40% pruning ratio.
- Efficiency tends to be higher with smaller pruning ratios and bigger KV cache sizes. With a KV cache dimension of 2048 and 40% pruning, ThinK may even outperform full KV cache fashions in some circumstances.
- On the Needle-in-a-Haystack take a look at, ThinK maintains or improves accuracy in comparison with SnapKV at a 40% pruning ratio throughout completely different KV cache sizes. Greater pruning ratios (≥50%) present some accuracy drops, notably with smaller cache sizes.
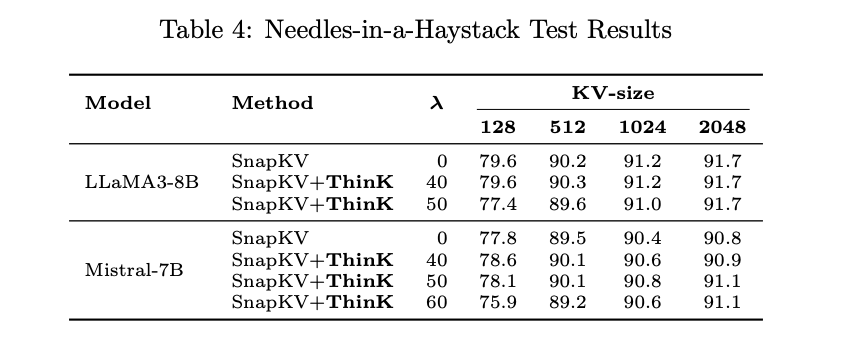
- Visualizations of the Needle-in-a-Haystack outcomes show ThinK’s robustness in sustaining retrieval capabilities throughout numerous token lengths and depths.
These outcomes recommend that ThinK is an efficient, model-agnostic methodology for additional optimizing KV cache compression, providing improved reminiscence effectivity with minimal efficiency trade-offs.
ThinK emerges as a promising development in optimizing Giant Language Fashions for long-context eventualities. By introducing query-dependent channel pruning for the important thing cache, this progressive methodology achieves a 40% discount in cache dimension whereas sustaining and even enhancing efficiency. ThinK’s compatibility with current optimization methods and its strong efficiency throughout numerous benchmarks, together with LongBench and Needle-in-a-Haystack checks, underscore its effectiveness and flexibility. As the sphere of pure language processing continues to evolve, ThinK’s strategy to balancing effectivity and efficiency addresses vital challenges in managing computational assets for LLMs. This methodology not solely enhances the capabilities of present fashions but additionally paves the best way for extra environment friendly and highly effective AI methods sooner or later, probably revolutionizing how we strategy long-context processing in language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.