What Is Noindex?
Noindex is a rule that tells search engines like google like Google to not index a given webpage—to stop it from being saved in a database that’s drawn from to indicate search outcomes.
Because of this once you noindex a web page, search engines like google gained’t save that web page. And it will not present up in search outcomes when folks search for data on-line.
You would possibly noindex pages you do not need the general public to see. Like non-public content material or PDF pages in your web site.
On this publish, we’ll cowl the whole lot you might want to learn about utilizing the noindex rule successfully.
However first, let’s go over why it’s best to care concerning the noindex directive within the first place.
Why Is Noindexing Essential in website positioning?
The noindex rule helps you management which pages are listed by search engines like google. And that means that you can influence your web site’s SEO (website positioning) efficiency.
For instance, let’s say you may have skinny pages (people who provide little worth) that you just’re unable to take away for one purpose or one other.
Utilizing noindex guidelines on these low-quality pages can forestall them from negatively impacting your web site’s website positioning efficiency. And as an alternative focus search engines like google’ consideration on different, extra necessary pages.
That mentioned, you don’t wish to unintentionally noindex any necessary pages in your web site. Should you do, they gained’t rank in search outcomes. Harming your visibility and visitors.
So, all the time double-check your noindex implementation.
When to Use the Noindex Directive
Numerous sorts of content material are prime candidates for utilizing the noindex rule. These embody:
- Skinny pages: These pages do not provide a lot worth to customers, to allow them to hurt your website positioning efficiency
- Pages in a staging setting: These pages aren’t meant for the general public to see or use. They’re meant to your group to make updates and examine issues.
- Inside admin pages: These pages are meant for you and your group. So, you don’t need them to seem in search outcomes.
- Thanks pages: These pages are exhibited to customers after they’ve accomplished an motion like downloading one thing or making a purchase order. You do not need folks discovering these pages instantly from search outcomes as a result of it’d confuse them.
- Downloadable content material: These pages are assets that customers are supposed to entry by filling out a type. So, you don’t need potential prospects discovering them with out having to offer their contact data.
Methods to Noindex a Web page
Now that you recognize which pages must be noindexed, it’s time to get to the precise implementation.
There are two methods to implement the noindex rule:
- As an X-Robots-Tag within the HTTP response header, which is helpful for non-HTML recordsdata like PDFs, photos, and movies
- As a meta tag in your HTML, which is helpful for many webpages
Implementing a noindex rule by way of the HTTP header methodology is kind of technical and requires server-level modifications.
Mainly, you might want to add a line of code to considered one of your server configuration recordsdata (normally .htaccess).
For Apache servers (one of the vital broadly used internet servers), the code appears like this if you wish to noindex all PDF recordsdata throughout your whole web site.
<Information ~ ".pdf$">
Header set X-Robots-Tag "noindex"
</Information>
Given the complexity and potential dangers concerned, we advocate looking for assist from a developer. As a result of even a small syntax error can break your web site.
As for the meta tag noindex methodology, it is comparatively easier and might be carried out instantly in your pages’ HTML.
The tag goes within the <head> part and appears like this:
<meta identify="robots" content material="noindex">
Should you’re utilizing a content material administration system (CMS) like WordPress, you’ll be able to typically use website positioning plugins to implement noindex meta tags with out instantly enhancing code.
To try this utilizing the Yoast website positioning plugin, open the web page you wish to noindex within the editor, scroll all the way down to the Yoast website positioning part, and click on the “Superior” tab.
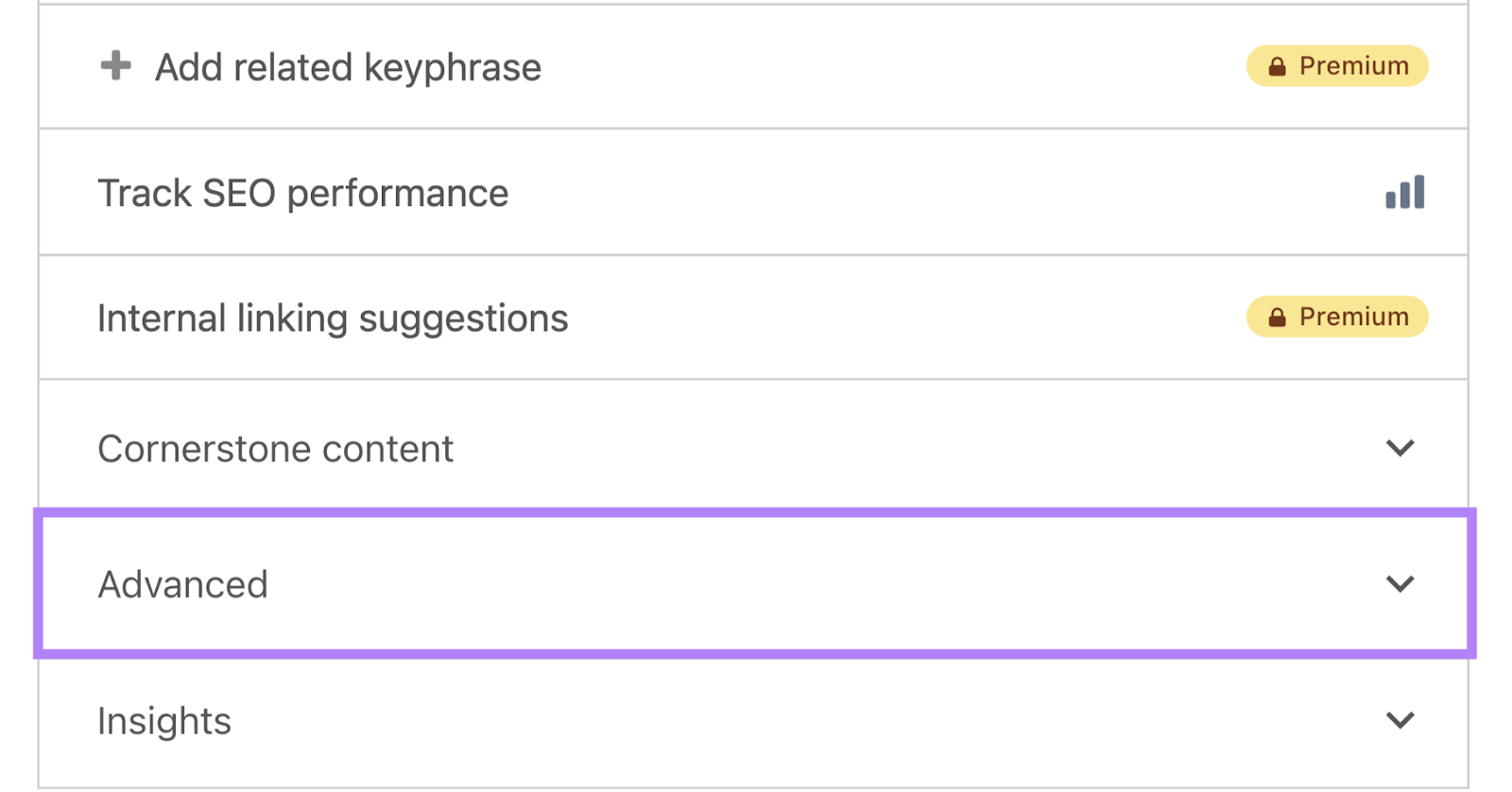
Underneath “Permit search engines like google to indicate this content material in search outcomes?,” choose “No” from the drop-down.
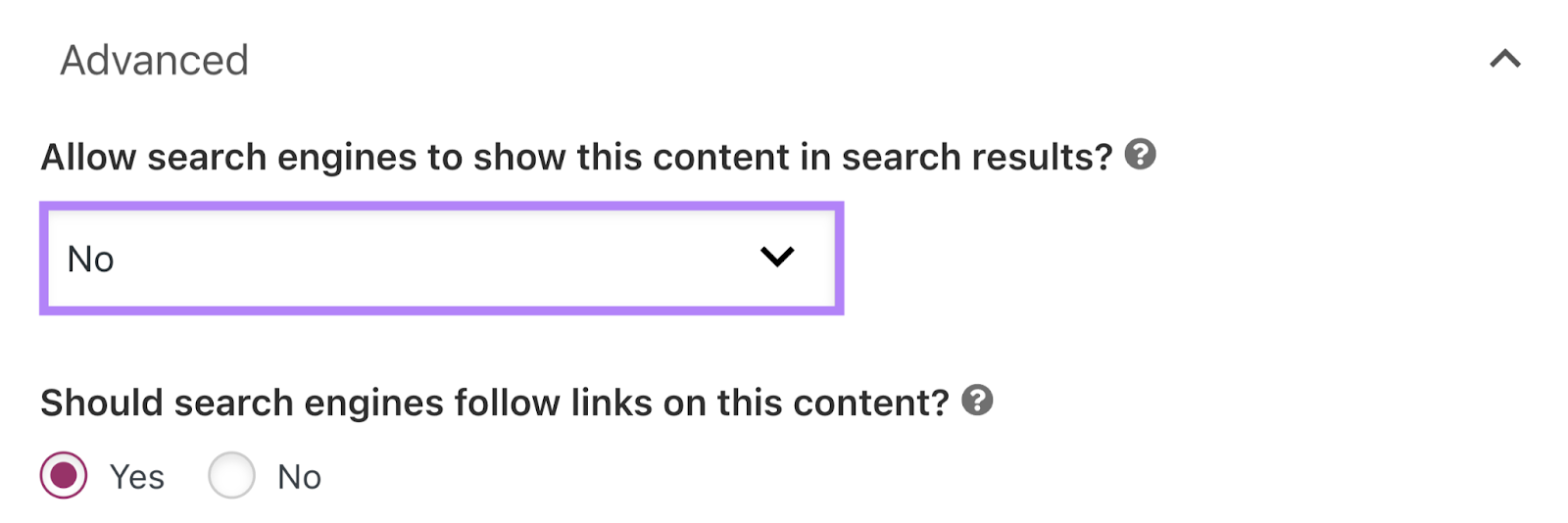
Then, save the publish.
To make use of the Rank Math website positioning plugin, open the web page you wish to modify within the editor, go to the Rank Math website positioning part, and click on the “Superior” tab.
Underneath “Robots Meta,” uncheck the field subsequent to “Index” and examine the one subsequent to “No Index” as an alternative.
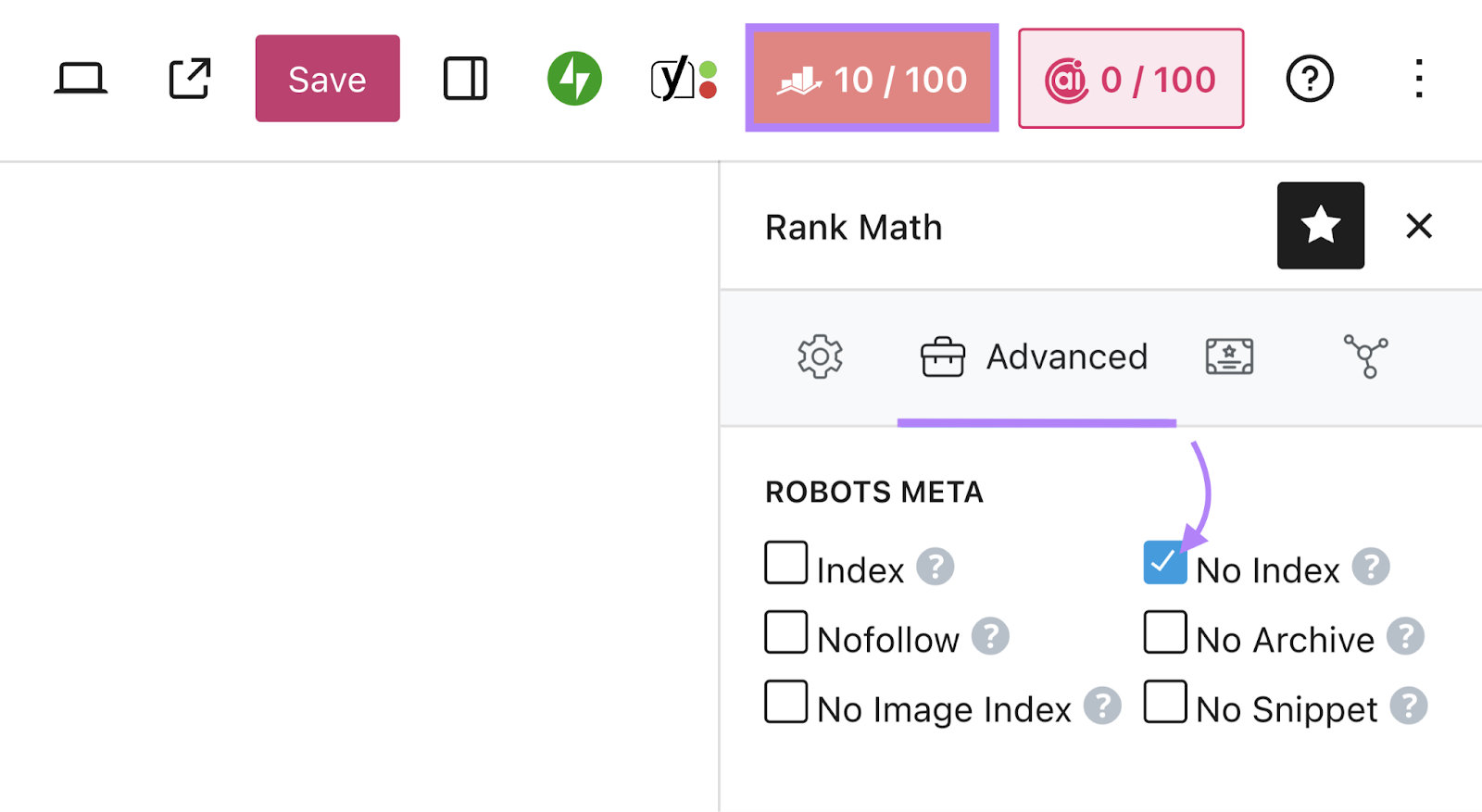
Save the publish to replace your settings.
Greatest Practices for Utilizing Noindex Guidelines
Listed below are some greatest practices to remember when you’re working with noindex directives.
1. Don’t Noindex Pages You Need to Seem in Search Outcomes
The noindex rule prevents a web page from getting listed and proven in search outcomes. So, in order for you a web page to be discovered by way of search, do not noindex it.
Use Semrush’s Website Audit instrument to be sure to haven’t unintentionally noindexed necessary pages.
Open the instrument, enter your area identify, and click on “Begin Audit.”
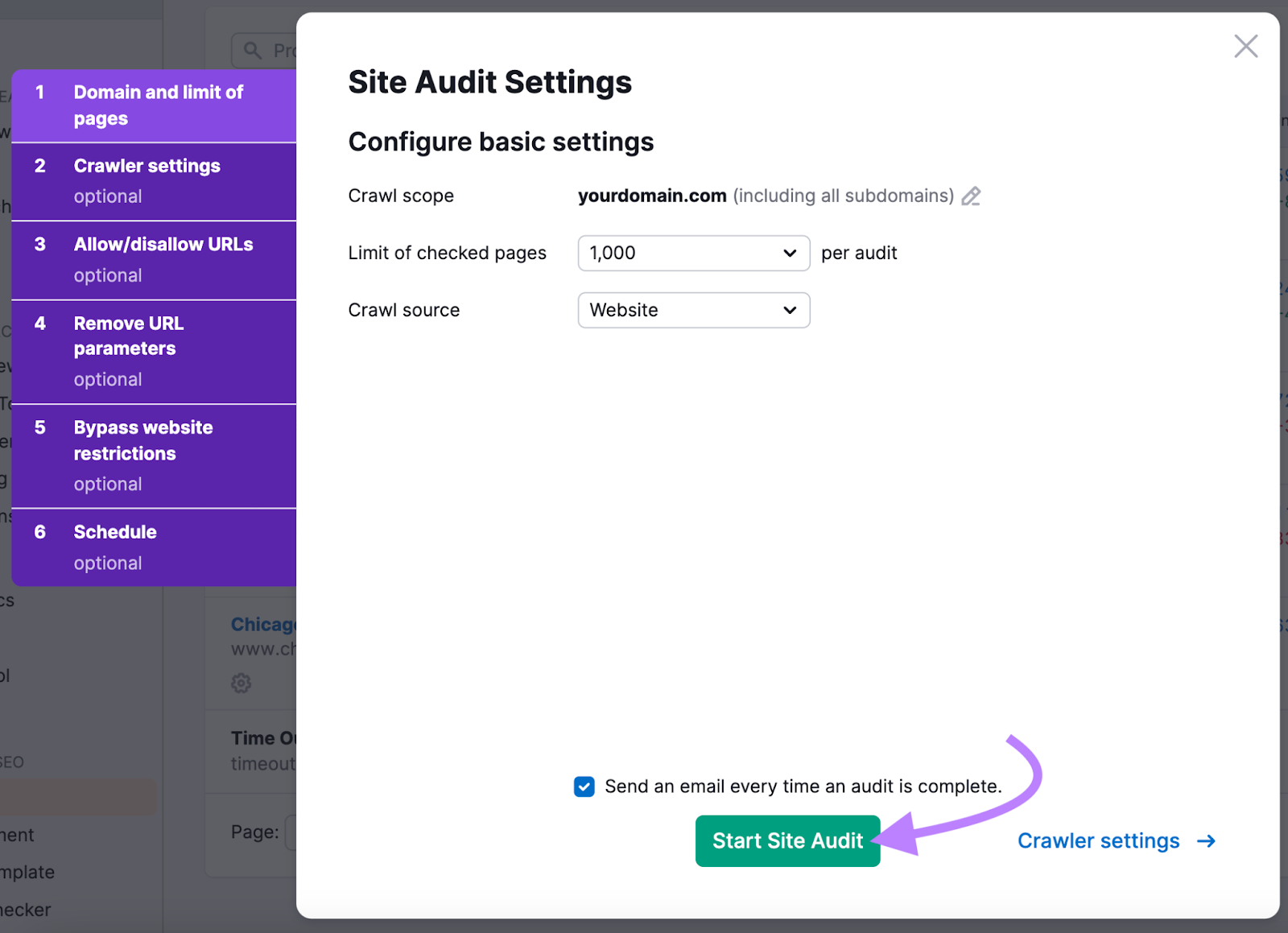
Comply with the prompts to configure your settings.
If you’re accomplished, click on “Begin Website Audit.”
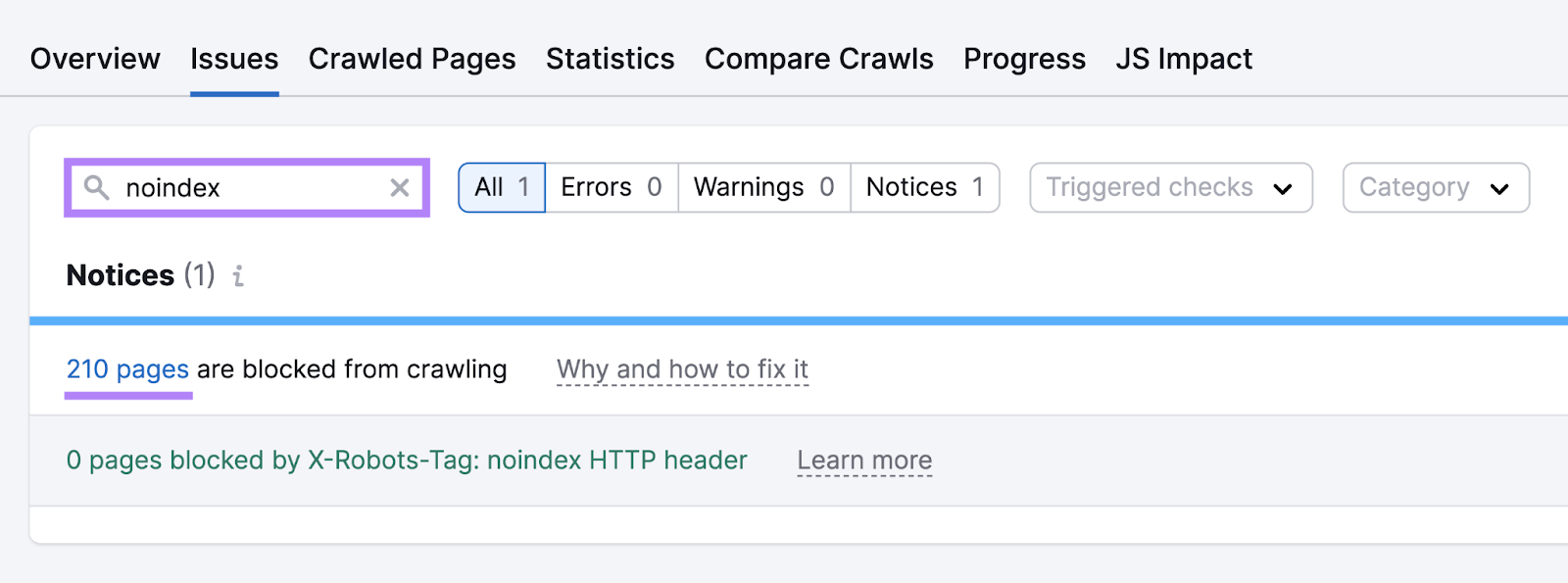
After the audit is full, head to the “Points” tab. And use the search bar to enter “noindex.”
You’ll see the variety of pages blocked by noindex tags or robots.txt (this file tells search engines like google which pages ought to and shouldn’t be crawled). You’ll additionally see whether or not any pages are noindexed utilizing the X-Robots-Tag methodology.
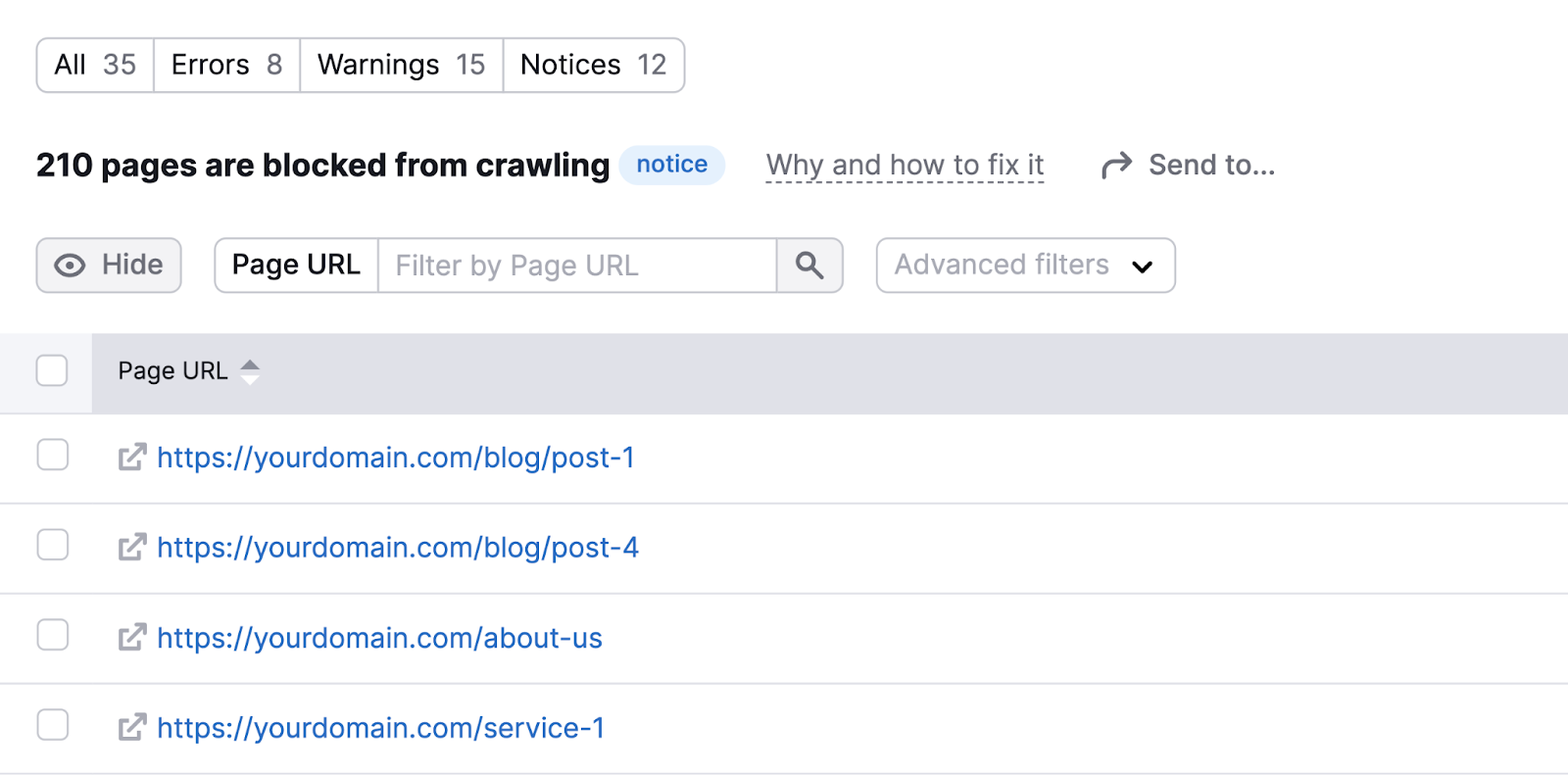
Click on the blue quantity in both difficulty to view the checklist of affected pages. And confirm that none of these pages have unintentionally been noindexed.
2. Don’t Attempt to Stop Indexing Utilizing Your Robots.txt File
The robots.txt file tells search engines like google which pages to crawl—not which pages to index.
Even for those who block a web page in robots.txt, search engines like google would possibly nonetheless index it in the event that they discover hyperlinks to it from different pages.
Plus, you really need search engines like google to have the ability to crawl your pages for them to see the noindex tag.
Examine your robots.txt file to verify it isn’t blocking pages you wish to noindex.
You are able to do this by visiting “[yourdomain.com]/robots.txt.”
Search for the “Disallow” directives in your robots.txt file.
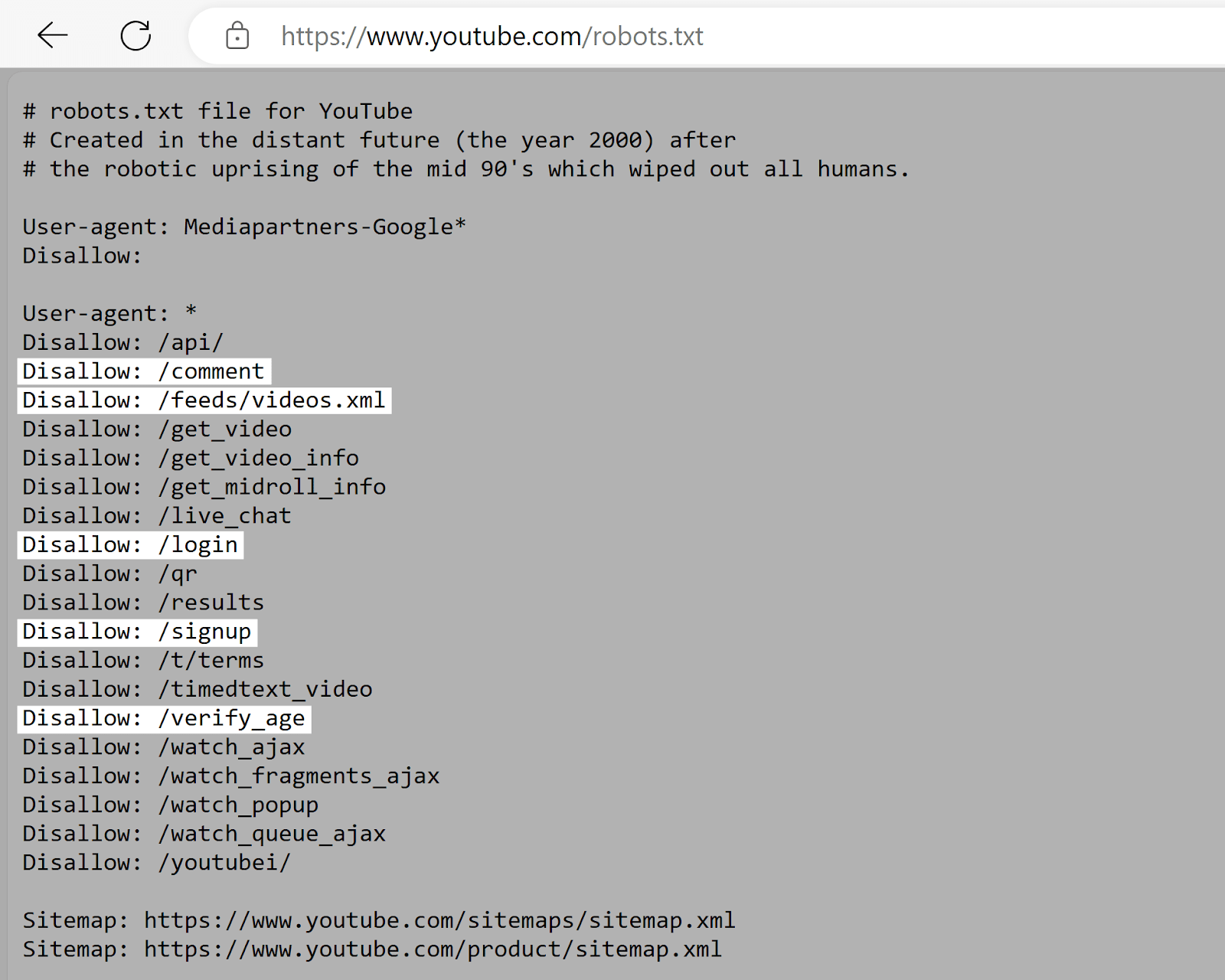
These inform search engines like google which pages or directories they should not entry. So, ensure that the pages you wish to noindex aren’t listed right here.
3. Take Steps to Deal with Nofollow Points That May Come up
Noindexing can hurt your website positioning if the webpages you’re blocking from showing in search outcomes are among the many solely hyperlinks pointing to a few of your different pages.
How?
Engines like google will solely comply with hyperlinks on a noindexed web page for some time. And ultimately deal with these hyperlinks as nofollow (i.e., that they shouldn’t be adopted or move rating energy).
If there are different pages in your web site with few inner hyperlinks and a few of these hyperlinks are out of your noindexed content material, it may change into tougher for search engines like google to search out these different pages.
So, they could not seem in search outcomes. Even in order for you them to.
Use Website Audit to search for the “# pages have just one incoming inner hyperlink” discover and click on the blue quantity.
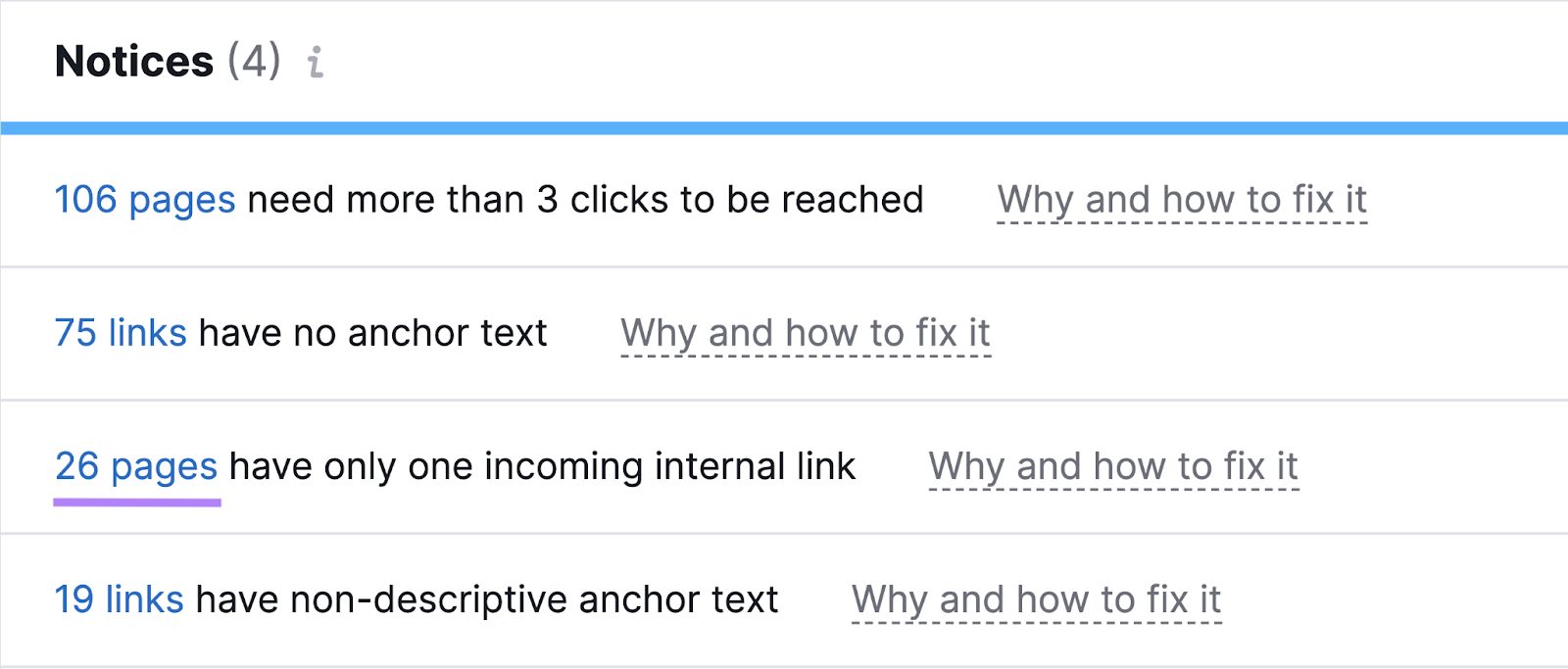
You’ll then see the affected pages.
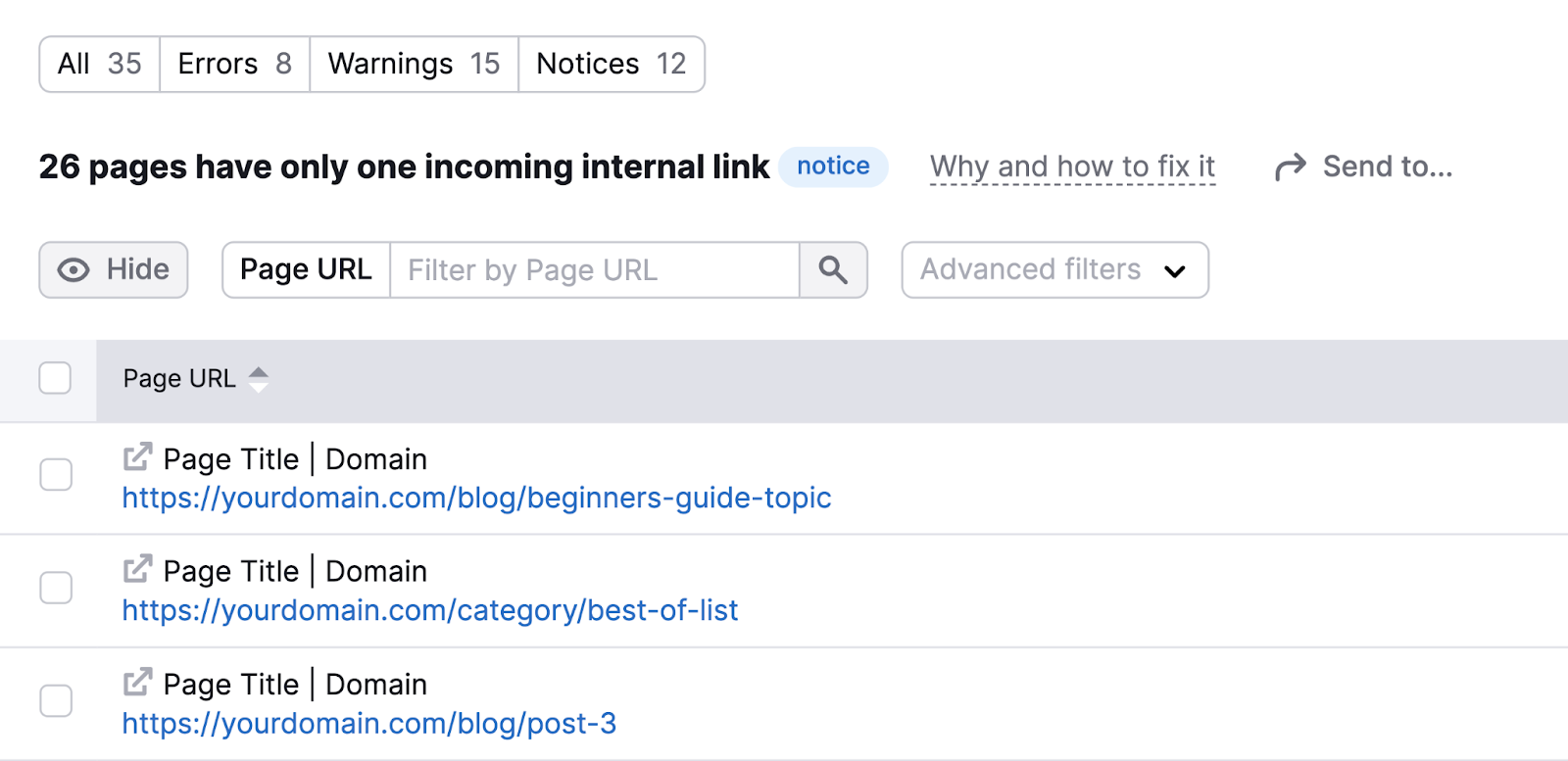
Work to include extra hyperlinks to those pages throughout your web site.
This can be a good thought even when the one incoming inner hyperlink isn’t from a noindexed web page.
4. Don’t Use a Noindex Directive for Duplicate Content material
Duplicate content material is when you may have two or extra pages which have precisely the identical or very comparable content material. Which makes it exhausting for search engines like google to determine which model to index and rank in search outcomes.
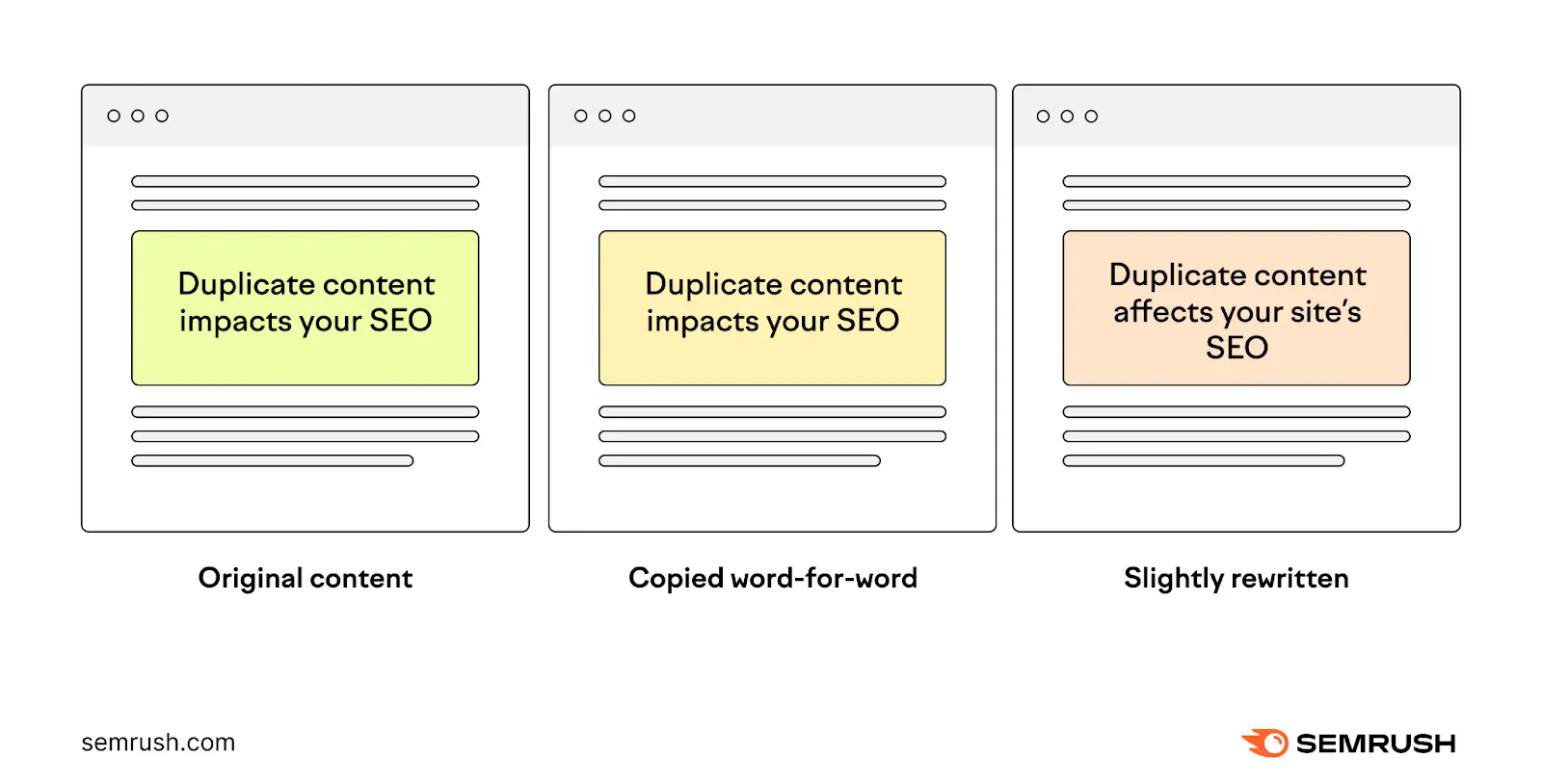
It’d appear to be utilizing noindex tags on duplicate pages is an efficient possibility, however this isn’t one of the best answer.
As a substitute, think about using canonical tags.
They inform search engines like google which model of a web page is the primary one and needs to be listed. Most significantly, in addition they consolidate rating energy from all variations to the primary web page.
5. Request a Recrawl if Noindexed Pages Nonetheless Seem in Search Outcomes
Noindexed pages would possibly nonetheless seem in search outcomes if Google hasn’t recrawled the web page because you added the noindex tag. However you’ll be able to velocity up the method by manually requesting a recrawl.
To do that, use Google Search Console (GSC).
Log in to GSC and click on “URL inspection” within the left-hand menu.
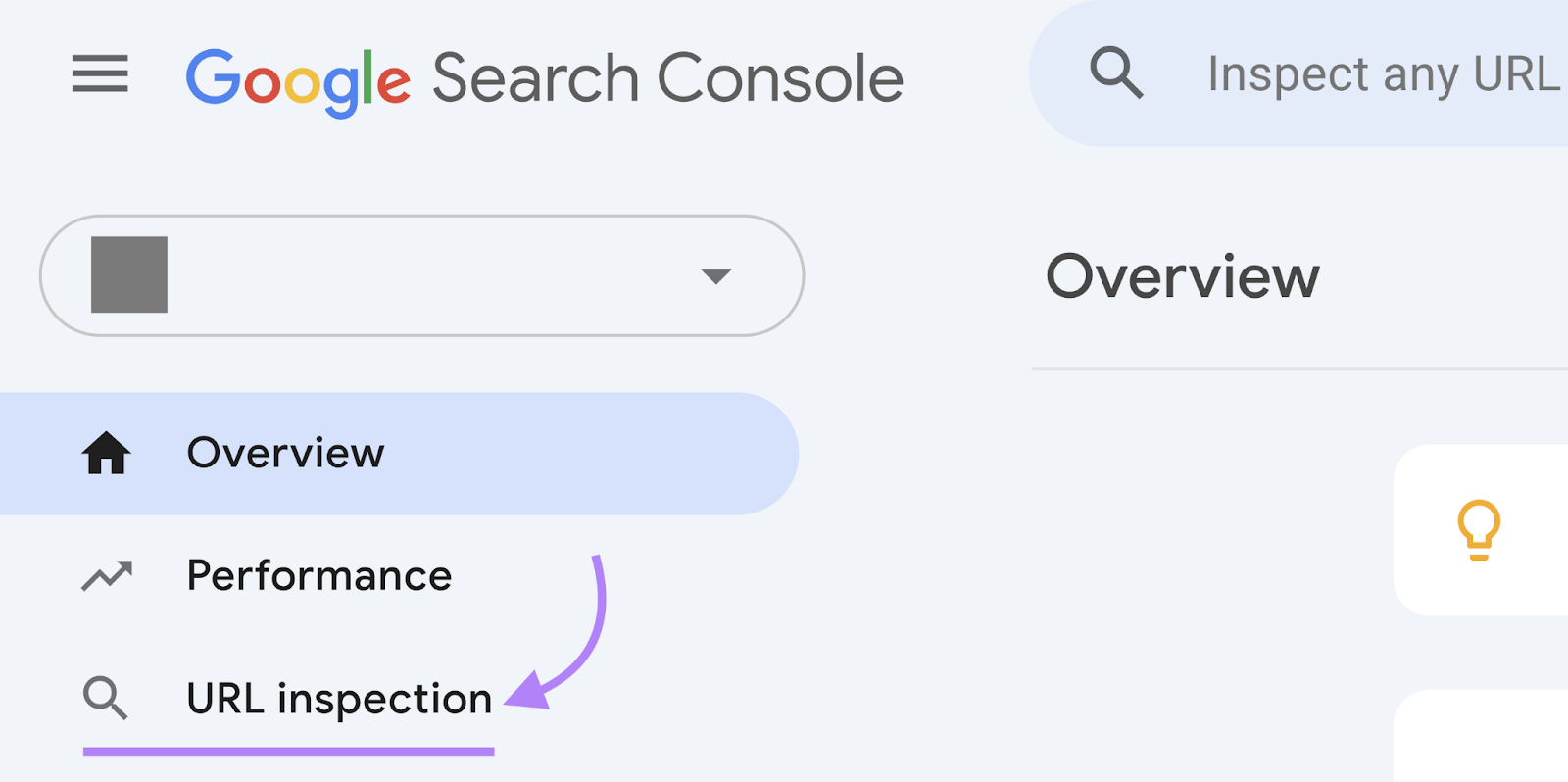
Now, paste the URL of the web page you need Google to recrawl. And hit return.

And click on “Request Indexing.”
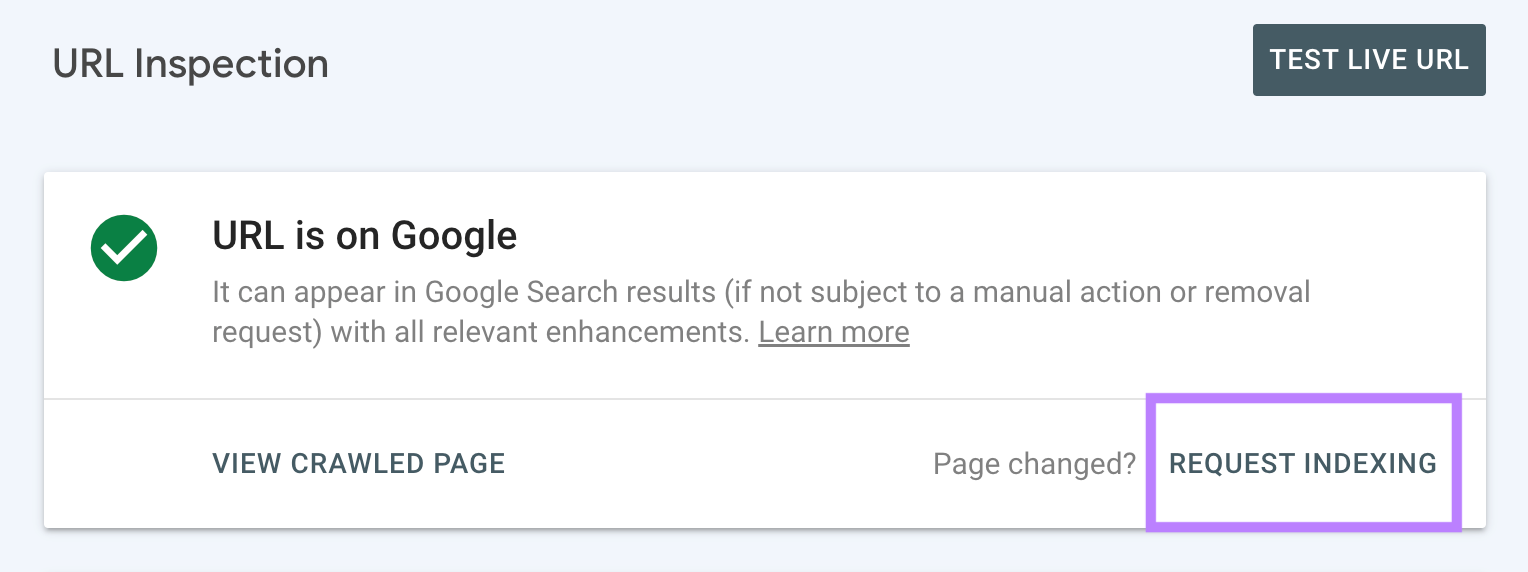
Google will then recrawl this web page.
6. Often Evaluation Your Noindexed Pages
It is necessary to examine your noindexed pages every now and then. As a result of errors can occur with out you noticing. Like if somebody in your group unintentionally noindexed a web page.
By monitoring your noindexed pages frequently, yow will discover and repair these errors shortly. So that you don’t see a dip in efficiency.
Preserve observe of your noindexed pages utilizing the Website Audit instrument.
To make issues even simpler, schedule common scans.
Simply go to the “Schedule” tab throughout setup. And choose the choice to observe your web site on a weekly foundation earlier than clicking “Begin Website Audit.”
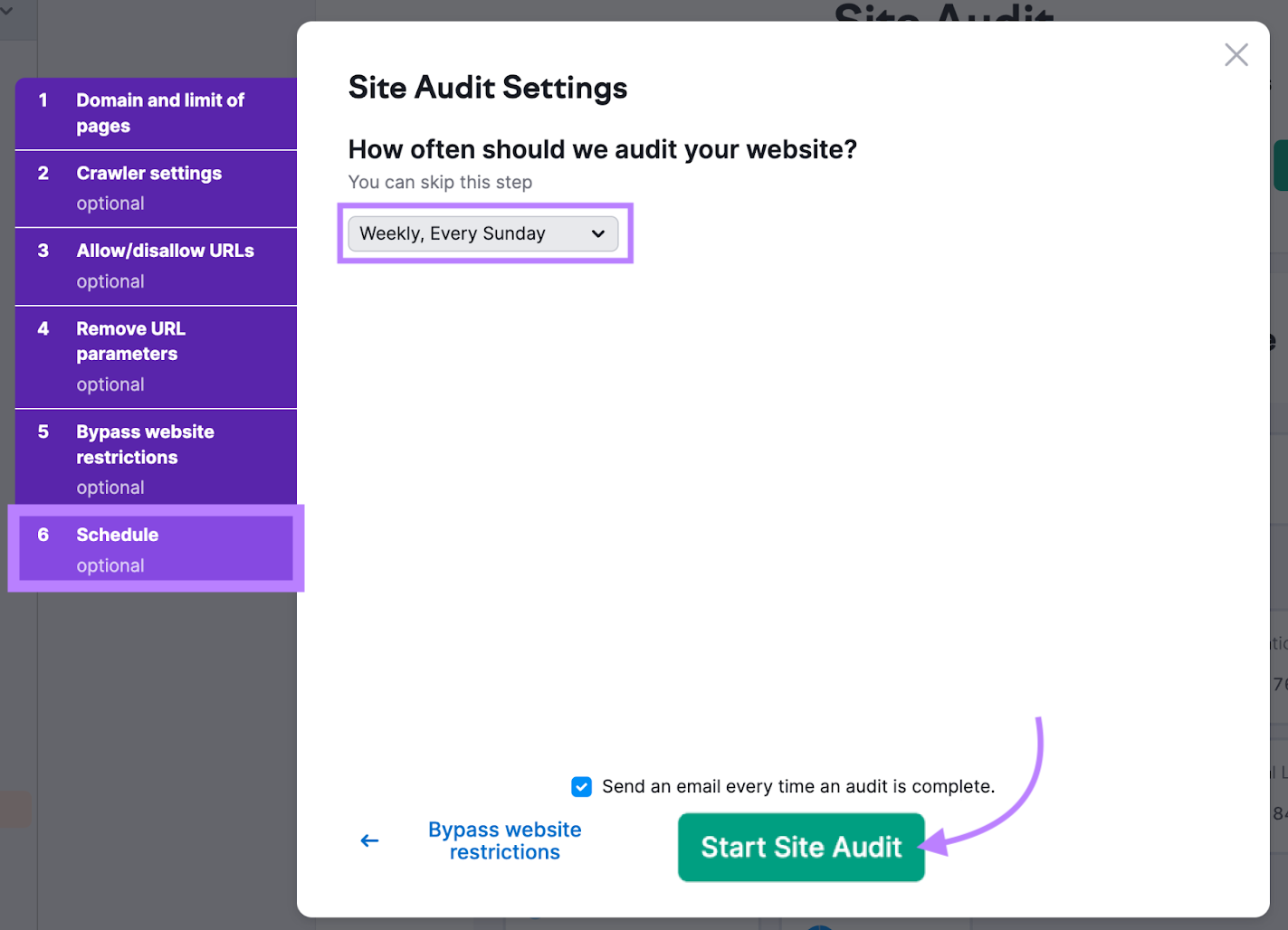
This audit will run on a weekly foundation. So you’ll be able to keep on high of any points which may crop up sooner or later.