
Massive language fashions (LLMs) have gained vital consideration as highly effective instruments for varied duties, however their potential as general-purpose decision-making brokers presents distinctive challenges. To perform successfully as brokers, LLMs should transcend merely producing believable textual content completions. They should exhibit interactive, goal-directed habits to perform particular duties. This requires two crucial talents: actively searching for details about the duty and making choices that may be improved by means of “pondering” and verification at inference time. Present methodologies wrestle to attain these capabilities, significantly in advanced duties requiring logical reasoning. Whereas LLMs typically possess the mandatory information, they continuously fail to use it successfully when requested to appropriate their very own errors sequentially. This limitation highlights the necessity for a extra sturdy method to allow test-time self-improvement in LLM brokers.
Researchers have tried varied approaches to boost the reasoning and pondering capabilities of basis fashions for downstream functions. These strategies primarily give attention to growing prompting strategies for efficient multi-turn interplay with exterior instruments, sequential refinement of predictions by means of reflection, thought verbalization, self-critique and revision, or utilizing different fashions for response criticism. Whereas a few of these approaches present promise in bettering responses, they typically depend on detailed error traces or exterior suggestions to succeed.
Prompting strategies, though helpful, have limitations. Research point out that intrinsic self-correction guided solely by the LLM itself is usually infeasible for off-the-shelf fashions, even after they possess the required information to deal with the immediate. Wonderful-tuning LLMs to acquire self-improvement capabilities has additionally been explored, utilizing methods equivalent to coaching on self-generated responses, realized verifiers, search algorithms, contrastive prompting on unfavourable information, and iterated supervised or reinforcement studying.
Nonetheless, these present strategies primarily give attention to bettering single-turn efficiency quite than introducing the aptitude to boost efficiency over sequential turns of interplay. Whereas some work has explored fine-tuning LLMs for multi-turn interplay instantly through reinforcement studying, this method addresses completely different challenges than these posed by single-turn issues in multi-turn eventualities.
Researchers from Carnegie Mellon College, UC Berkeley, and MultiOn current RISE (Recursive IntroSpEction), a singular method to boost LLMs’ self-improvement capabilities. This technique employs an iterative fine-tuning process that frames single-turn prompts as multi-turn Markov determination processes. By incorporating ideas from on-line imitation studying and reinforcement studying, RISE develops methods for multi-turn information assortment and coaching. This method allows LLMs to recursively detect and proper errors in subsequent iterations, a functionality beforehand thought difficult to achieve. Not like conventional strategies specializing in single-turn efficiency, RISE goals to instill dynamic self-improvement in LLMs, probably revolutionizing their problem-solving talents in advanced eventualities.
RISE presents an modern method to fine-tune basis fashions for self-improvement over a number of turns. The strategy begins by changing single-turn issues right into a multi-turn Markov Choice Course of (MDP). This MDP building transforms prompts into preliminary states, with mannequin responses serving as actions. The following state is created by concatenating the present state, the mannequin’s motion, and a hard and fast introspection immediate. Rewards are primarily based on reply correctness. RISE then employs methods for information assortment and studying inside this MDP framework. The method makes use of both distillation from a extra succesful mannequin or self-distillation to generate improved responses. Lastly, RISE applies reward-weighted supervised studying to coach the mannequin, enabling it to boost its predictions over sequential makes an attempt.
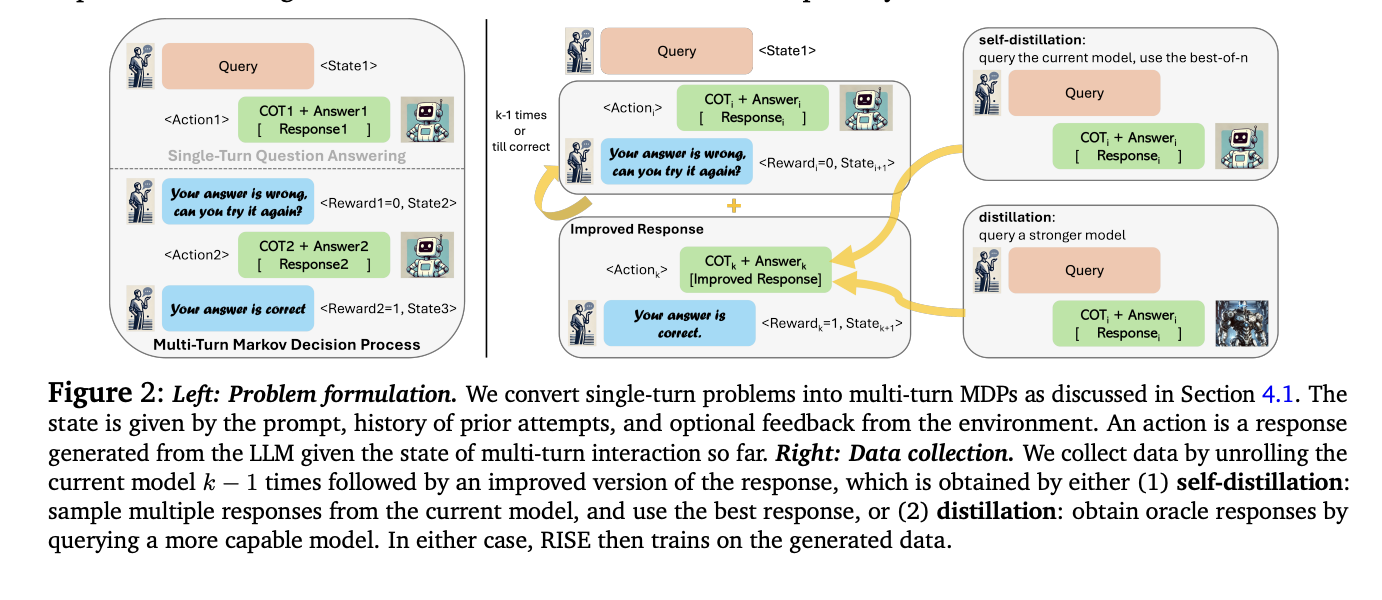
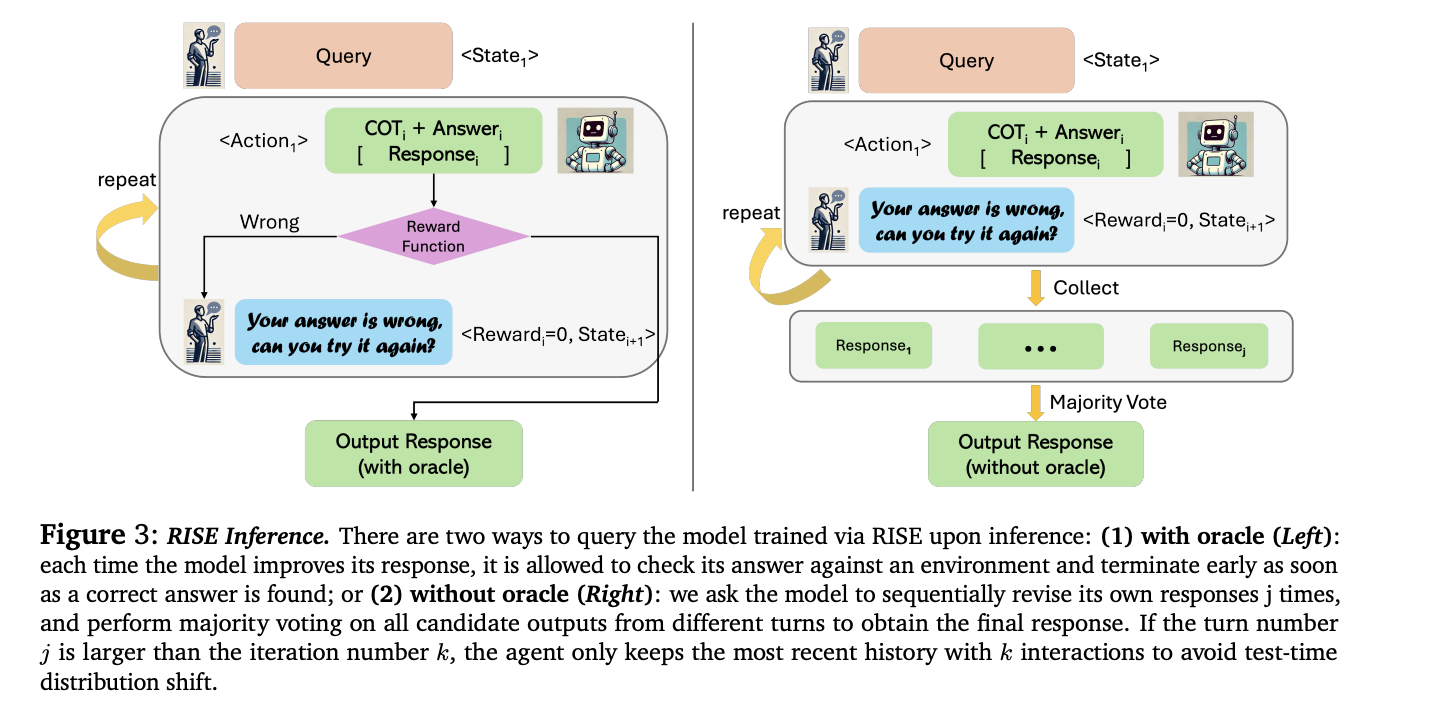
RISE demonstrates vital efficiency enhancements throughout a number of benchmarks. On GSM8K, RISE boosted the LLama2 base mannequin’s five-turn efficiency by 15.1% and 17.7% after one and two iterations respectively, with out utilizing an oracle. On MATH, enhancements of three.4% and 4.6% had been noticed. These good points surpass these achieved by different strategies, together with prompting-only self-refinement and normal fine-tuning on oracle information. Notably, RISE outperforms sampling a number of responses in parallel, indicating its capability to genuinely appropriate errors over sequential turns. The strategy’s effectiveness persists throughout completely different base fashions, with Mistral-7B + RISE outperforming Eurus-7B-SFT, a mannequin particularly fine-tuned for math reasoning. Additionally, a self-distillation model of RISE exhibits promise, bettering 5-turn efficiency even with fully self-generated information and supervision.
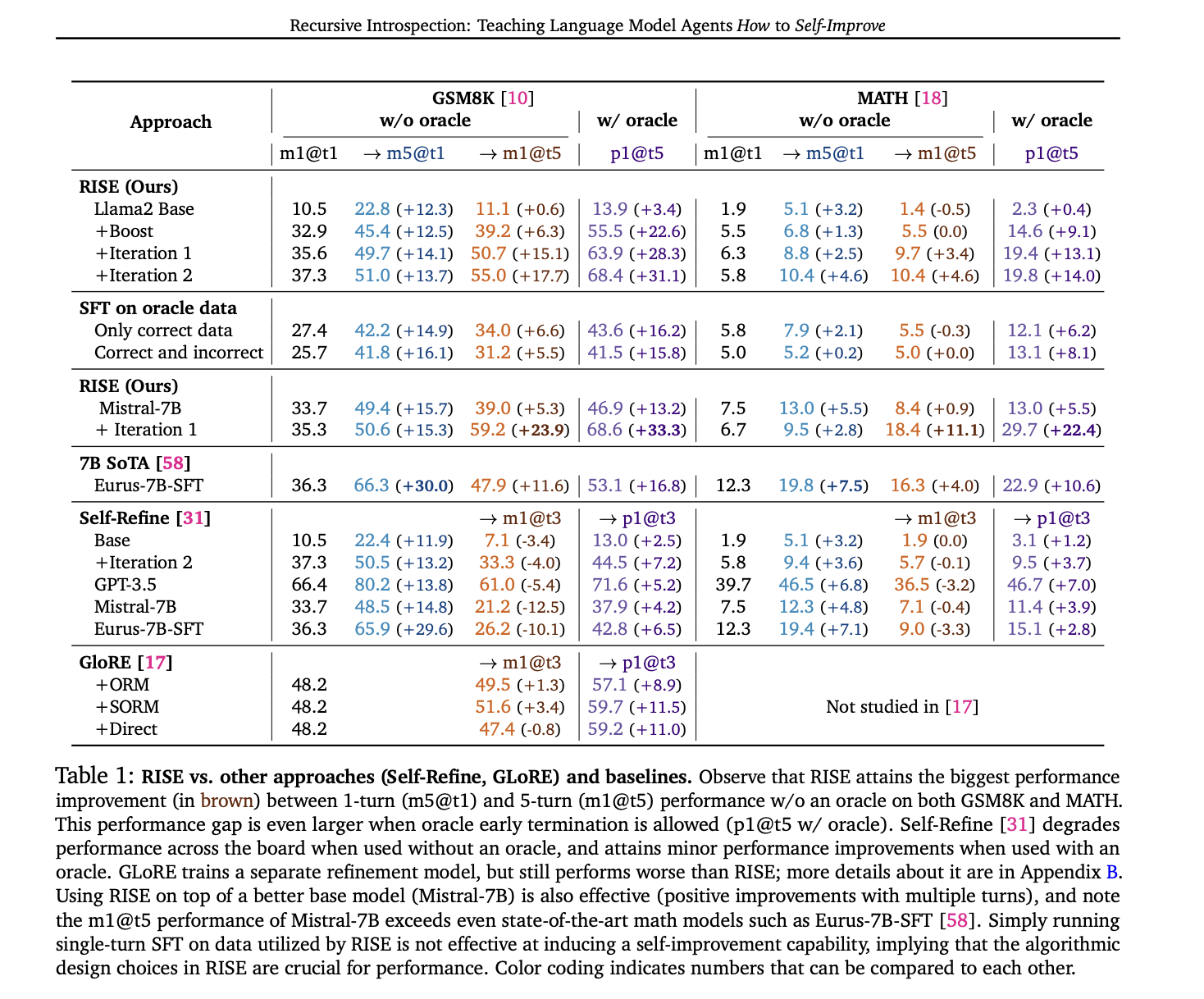
RISE introduces a singular method for fine-tuning Massive Language Fashions to enhance their responses over a number of turns. By changing single-turn issues into multi-turn Markov Choice Processes, RISE employs iterative reinforcement studying on on-policy rollout information, utilizing skilled or self-generated supervision. The strategy considerably enhances self-improvement talents of 7B fashions on reasoning duties, outperforming earlier approaches. Outcomes present constant efficiency good points throughout completely different base fashions and duties, demonstrating real sequential error correction. Whereas computational constraints presently restrict the variety of coaching iterations, particularly with self-generated supervision, RISE presents a promising route for advancing LLM self-improvement capabilities.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


