
A vital facet of AI analysis includes fine-tuning massive language fashions (LLMs) to align their outputs with human preferences. This fine-tuning ensures that AI techniques generate helpful, related, and aligned responses with consumer expectations. The present paradigm in AI emphasizes studying from human choice knowledge to refine these fashions, addressing the complexity of manually specifying reward features for varied duties. The 2 predominant methods on this space are on-line reinforcement studying (RL) and offline contrastive strategies, every providing distinctive benefits and challenges.
A central problem in fine-tuning LLMs to replicate human preferences is the restricted protection of static datasets. These datasets could must adequately symbolize the various and dynamic vary of human preferences in real-world purposes. The problem of dataset protection turns into notably pronounced when fashions are educated solely on pre-collected knowledge, probably resulting in suboptimal efficiency. This drawback underscores the necessity for strategies to successfully leverage static datasets and real-time knowledge to boost mannequin alignment with human preferences.
Current methods for choice fine-tuning in LLMs embrace on-line RL strategies, equivalent to Proximal Coverage Optimization (PPO), and offline contrastive strategies, like Direct Choice Optimization (DPO). On-line RL strategies contain a two-stage process the place a reward mannequin is educated on a set offline choice dataset, adopted by RL coaching utilizing on-policy knowledge. This strategy advantages from real-time suggestions however is computationally intensive. In distinction, offline contrastive strategies optimize insurance policies based mostly solely on pre-collected knowledge, avoiding the necessity for real-time sampling however probably affected by overfitting and restricted generalization capabilities.
Researchers from Carnegie Mellon College, Aurora Innovation, and Cornell College launched a novel methodology known as Hybrid Choice Optimization (HyPO). This hybrid strategy combines the facility of each on-line and offline methods, aiming to enhance mannequin efficiency whereas sustaining computational effectivity. HyPO integrates offline knowledge for preliminary choice optimization. It makes use of on-line unlabeled knowledge for Kullback-Leibler (KL) regularization, guaranteeing the mannequin stays near a reference coverage and higher generalizes past the coaching knowledge.
HyPO makes use of a classy algorithmic framework that leverages offline knowledge for the DPO goal and on-line samples to regulate the reverse KL divergence. The algorithm iteratively updates the mannequin’s parameters by optimizing the DPO loss whereas incorporating a KL regularization time period derived from on-line samples. This hybrid strategy successfully addresses the deficiencies of purely offline strategies, equivalent to overfitting and inadequate dataset protection, by incorporating the strengths of on-line RL strategies with out their computational complexity.
The efficiency of HyPO was evaluated on a number of benchmarks, together with the TL;DR summarization job and basic chat benchmarks like AlpacaEval 2.0 and MT-Bench. The outcomes had been spectacular, with HyPO reaching a win charge of 46.44% on the TL;DR job utilizing the Pythia 1.4B mannequin, in comparison with 42.17% for the DPO methodology. For the Pythia 2.8B mannequin, HyPO achieved a win charge of fifty.50%, considerably outperforming DPO’s 44.39%. Moreover, HyPO demonstrated superior management over reverse KL divergence, with values of 0.37 and a pair of.51 for the Pythia 1.4B and a pair of.8B fashions, respectively, in comparison with 0.16 and a pair of.43 for DPO.
Typically chat benchmarks, HyPO additionally confirmed notable enhancements. As an example, within the MT-Bench analysis, HyPO fine-tuned fashions achieved scores of 8.43 and eight.09 within the first and second flip averages, respectively, surpassing the DPO-fine-tuned fashions’ scores of 8.31 and seven.89. Equally, within the AlpacaEval 2.0, HyPO achieved 30.7% and 32.2% win charges for the first and 2nd turns, in comparison with DPO’s 28.4% and 30.9%.
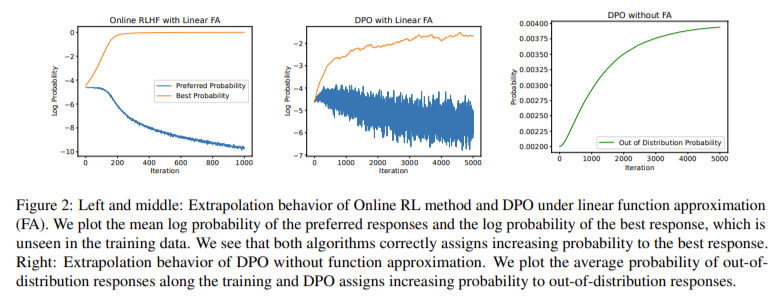
The empirical outcomes spotlight HyPO’s capacity to mitigate overfitting points generally noticed in offline contrastive strategies. For instance, when educated on the TL;DR dataset, HyPO maintained a imply validation KL rating considerably decrease than that of DPO, indicating higher alignment with the reference coverage and decreased overfitting. This capacity to leverage on-line knowledge for regularization helps HyPO obtain extra strong efficiency throughout varied duties.

In conclusion, the introduction of hybrid choice optimization (HyPO), which successfully combines offline and on-line knowledge, addresses the constraints of present strategies and enhances the alignment of enormous language fashions with human preferences. The efficiency enhancements demonstrated in empirical evaluations underscore the potential of HyPO to ship extra correct and dependable AI techniques.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.


