
Massive Language Fashions (LLMs) have revolutionized the sector of pure language processing, permitting machines to know and generate human language. These fashions, reminiscent of GPT-4 and Gemini-1.5, are essential for in depth textual content processing purposes, together with summarization and query answering. Nevertheless, managing lengthy contexts stays difficult as a consequence of computational limitations and elevated prices. Researchers are, due to this fact, exploring progressive approaches to stability efficiency and effectivity.
A notable problem in processing prolonged texts is the computational burden and related prices. Conventional strategies typically want to enhance when coping with lengthy contexts, necessitating new methods to deal with this situation successfully. This drawback requires methodologies that stability excessive efficiency with value effectivity. One promising strategy is Retrieval Augmented Technology (RAG), which retrieves related data based mostly on a question and prompts LLMs to generate responses inside that context. RAG considerably expands a mannequin’s capability to entry data economically. Nevertheless, a comparative evaluation turns into important with developments in LLMs like GPT-4 and Gemini-1.5, which present improved capabilities in straight processing lengthy contexts.
Researchers from Google DeepMind and the College of Michigan launched a brand new technique referred to as SELF-ROUTE. This technique combines the strengths of RAG and long-context LLMs (LC) to route queries effectively utilizing mannequin self-reflection to determine whether or not to make use of RAG or LC based mostly on the character of the question. The SELF-ROUTE technique operates in two steps. Initially, the question and retrieved chunks are offered to the LLM to find out if the question is answerable. If deemed answerable, the RAG-generated reply is used. In any other case, the LC will probably be given the total context for a extra complete response. This strategy considerably reduces computational prices whereas sustaining excessive efficiency, successfully leveraging the strengths of each RAG and LC fashions.
The SELF-ROUTE analysis concerned three current LLMs: Gemini-1.5-Professional, GPT-4, and GPT-3.5-Turbo. The examine benchmarked these fashions utilizing LongBench and u221eBench datasets, specializing in query-based duties in English. The outcomes demonstrated that LC fashions constantly outperformed RAG in understanding lengthy contexts. For instance, LC surpassed RAG by 7.6% for Gemini-1.5-Professional, 13.1% for GPT-4, and three.6% for GPT-3.5-Turbo. Nevertheless, RAG’s cost-effectiveness stays a major benefit, significantly when the enter textual content significantly exceeds the mannequin’s context window measurement.
SELF-ROUTE achieved notable value reductions whereas sustaining comparable efficiency to LC fashions. As an illustration, the price was decreased by 65% for Gemini-1.5-Professional and 39% for GPT-4. The tactic additionally confirmed a excessive diploma of prediction overlap between RAG and LC, with 63% of queries having similar predictions and 70% displaying a rating distinction of lower than 10. This overlap means that RAG and LC typically make comparable predictions, each appropriate and incorrect, permitting SELF-ROUTE to leverage RAG for many queries and reserve LC for extra advanced instances.
The detailed efficiency evaluation revealed that, on common, LC fashions surpassed RAG by important margins: 7.6% for Gemini-1.5-Professional, 13.1% for GPT-4, and three.6% for GPT-3.5-Turbo. Apparently, for datasets with extraordinarily lengthy contexts, reminiscent of these in u221eBench, RAG typically carried out higher than LC, significantly for GPT-3.5-Turbo. This discovering highlights RAG’s effectiveness in particular use instances the place the enter textual content exceeds the mannequin’s context window measurement.
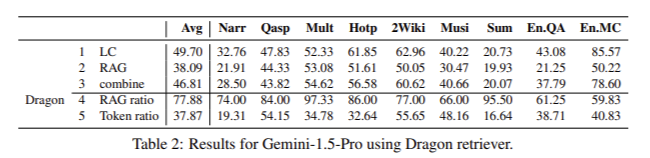
The examine additionally examined varied datasets to know the restrictions of RAG. Frequent failure causes included multi-step reasoning necessities, normal or implicit queries, and lengthy, advanced queries that problem the retriever. By analyzing these failure patterns, the analysis staff recognized potential areas for enchancment in RAG, reminiscent of incorporating chain-of-thought processes and enhancing question understanding strategies.

In conclusion, the excellent comparability of RAG and LC fashions highlights the trade-offs between efficiency and computational value in long-context LLMs. Whereas LC fashions exhibit superior efficiency, RAG stays viable as a consequence of its decrease value and particular benefits in dealing with in depth enter texts. The SELF-ROUTE technique successfully combines the strengths of each RAG and LC, attaining efficiency akin to LC at a considerably decreased value.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.



