Movement understanding has an necessary function in video-based cross-media evaluation and a number of information illustration studying. A bunch of researchers led by Hehe Fan has studied the issues of recognizing and predicting bodily movement utilizing deep neural networks (DNNs), specifically convolutional neural networks and recurrent neural networks. The scientists developed and examined a deep studying strategy based mostly on relative place change encoded as a sequence of vectors, and discovered that their technique outperformed current movement modeling frameworks.
In physics, movement is a relative change in place over time. To eradicate object and background components, scientists targeted on a super situation wherein a dot strikes in a two-dimensional (2D) aircraft. Two duties have been used to guage the flexibility of DNN architectures to mannequin movement: movement recognition and movement prediction. Consequently, a vector community (VecNet) was developed to mannequin relative place change. The important thing innovation of the scientists was to encode movement individually from place.
The group’s analysis was revealed within the journal Clever Computing.
The examine focuses on movement evaluation. Movement recognition is geared toward recognizing various kinds of actions from a sequence of observations. This may be seen as one of many crucial circumstances for motion recognition, since motion recognition will be divided into object recognition and movement recognition. For instance, to acknowledge the motion “open the door,” DNNs should acknowledge the thing “door” and the motion “open.” In any other case, the mannequin wouldn’t distinguish “open the door” from “open the window” or “open the door” from “shut the door.” Movement prediction is geared toward predicting future modifications in place after viewing a portion of the movement, i.e., the movement context, which will be thought-about one of many required circumstances for video predictions.
VecNet takes short-range movement as a vector. VecNet also can transfer the dot to the corresponding place given by the vector illustration. To realize perception into movement over time, lengthy short-term reminiscence (LSTM) was used to mixture or predict vector representations over time. The ensuing new VecNet+LSTM technique can successfully assist each recognition and prediction, proving that modeling relative place change is important for movement recognition and facilitates movement prediction.
Motion recognition is said to movement recognition as a result of it’s associated to movement. Since there is no such thing as a unambiguous present DNN structure for motion recognition, the researchers have in contrast and studied a subset of fashions masking many of the area.
The VecNet + LSTM strategy scored larger in movement recognition checks than six different well-liked DNN architectures from video research on relative place change modeling. A few of them turned out to be merely weaker, and a few have been fully unsuitable for the movement modeling job.
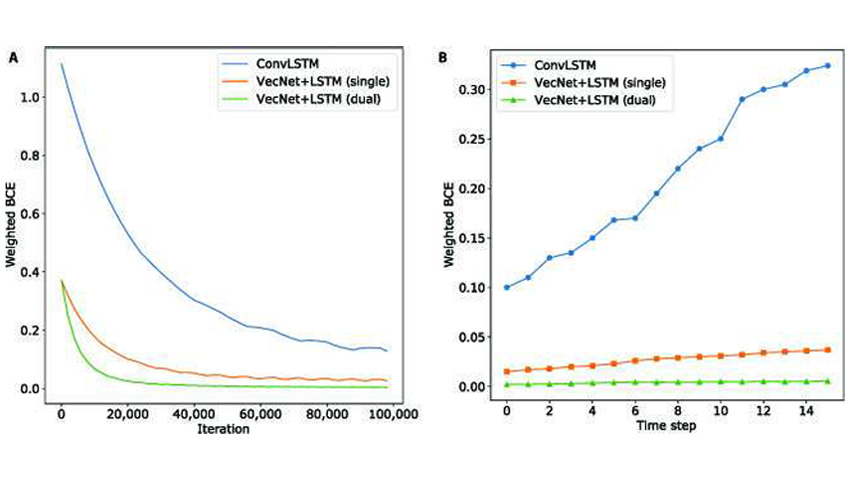
For instance, when in comparison with the ConvLSTM technique, the brand new technique was extra correct, required much less coaching time, and didn’t lose precision as shortly when making further predictions.
Experiments have demonstrated that the VecNet + LSTM technique is efficient for movement recognition and prediction. It confirms that using relative place change considerably improves movement modeling. With look or picture processing strategies, the supplied movement modeling technique can be utilized for basic video understanding that may be studied sooner or later.


