
Giant Language Fashions (LLMs) face deployment challenges resulting from latency points brought on by reminiscence bandwidth constraints. Researchers use weight-only quantization to deal with this, compressing LLM parameters to decrease precision. This strategy improves latency and reduces GPU reminiscence necessities. Implementing this successfully requires customized mixed-type matrix-multiply kernels that transfer, dequantize, and course of weights effectively. Current kernels like bits and bytes, Marlin, and BitBLAS have proven vital speed-ups however are sometimes restricted to 4-bit quantization. Current developments in odd-bit and non-uniform quantization strategies spotlight the necessity for extra versatile kernels that may assist a wider vary of settings to maximise the potential of weight quantization in LLM deployment.
Researchers have tried to resolve the LLM deployment challenges utilizing weight-only quantization. Uniform quantization converts full-precision weights to lower-precision intervals, whereas non-uniform strategies like lookup desk (LUT) quantization supply extra flexibility. Current kernels like bits and bytes, Marlin, and BitBLAS transfer quantized weights from most important reminiscence to on-chip SRAM, performing matrix multiplications after de-quantizing to floating-point. These present vital speed-ups however typically specialise in 4-bit uniform quantization, with LUT-quantization kernels underperforming. Non-uniform strategies like SqueezeLLM and NormalFloat face trade-offs between lookup desk measurement and quantization granularity. Additionally, non-uniformly quantized operations can’t make the most of GPU accelerators optimized for floating-point calculations. This highlights the necessity for environment friendly kernels that may make the most of quantized representations to reduce reminiscence motion and GPU-native floating-point matrix multiplications, balancing the advantages of quantization with {hardware} optimization.
Researchers from Massachusetts Institute of Expertise, Excessive College of Arithmetic Plovdiv and Carnegie Mellon College, MBZUAI, Petuum Inc. introduce an modern strategy that, versatile lookup-table engine (FLUTE) for deploying weight-quantized LLMs, specializing in low-bit and non-uniform quantization. It addresses three most important challenges: dealing with sub-8-bit matrices, optimizing lookup table-based dequantization, and bettering workload distribution for small batches and low-bit-width weights. FLUTE overcomes these points by means of three key methods: offline weight restructuring, a shared-memory lookup desk for environment friendly dequantization, and Stream-Ok partitioning for optimized workload distribution. This strategy permits FLUTE to successfully handle the complexities of low-bit and non-uniform quantization in LLM deployment, bettering effectivity and efficiency in eventualities the place conventional strategies fall brief.
FLUTE is an modern strategy for, versatile mixed-type matrix multiplications in weight-quantized LLMs. It addresses key challenges in deploying low-bit and non-uniform quantized fashions by means of three most important methods:
- Offline Matrix Restructuring: FLUTE reorders quantized weights to optimize for Tensor Core operations, dealing with non-standard bit widths (e.g., 3-bit) by splitting weights into bit-slices and mixing them in registers.
- Vectorized Lookup in Shared Reminiscence: To optimize dequantization, FLUTE makes use of a vectorized lookup desk saved in shared reminiscence, accessing two parts concurrently. It additionally employs desk duplication to cut back financial institution conflicts.
- Stream-Ok Workload Partitioning: FLUTE implements Stream-Ok decomposition to evenly distribute workload throughout SMs, mitigating wave quantization points in low-bit and low-batch eventualities.
These improvements permit FLUTE to effectively fuse dequantization and matrix multiplication operations, optimizing reminiscence utilization and computational throughput. The kernel employs a complicated pipeline of knowledge motion between international reminiscence, shared reminiscence, and registers, using GPU {hardware} capabilities for max efficiency in weight-quantized LLM deployments.
FLUTE exhibits spectacular efficiency throughout varied matrix shapes on each A6000 and A100 GPUs. On the A6000, it often approaches the theoretical most speedup of 4x. This efficiency can be constant throughout totally different batch sizes, not like different LUT-compatible kernels which usually obtain comparable speedups solely at a batch measurement of 1 after which degrade quickly as batch measurement will increase. Additionally, FLUTE’s efficiency compares effectively even to Marlin, a kernel extremely specialised for FP16 enter and uniform-quantized INT4 weights. This demonstrates FLUTE’s means to effectively deal with each uniform and non-uniform quantization schemes.
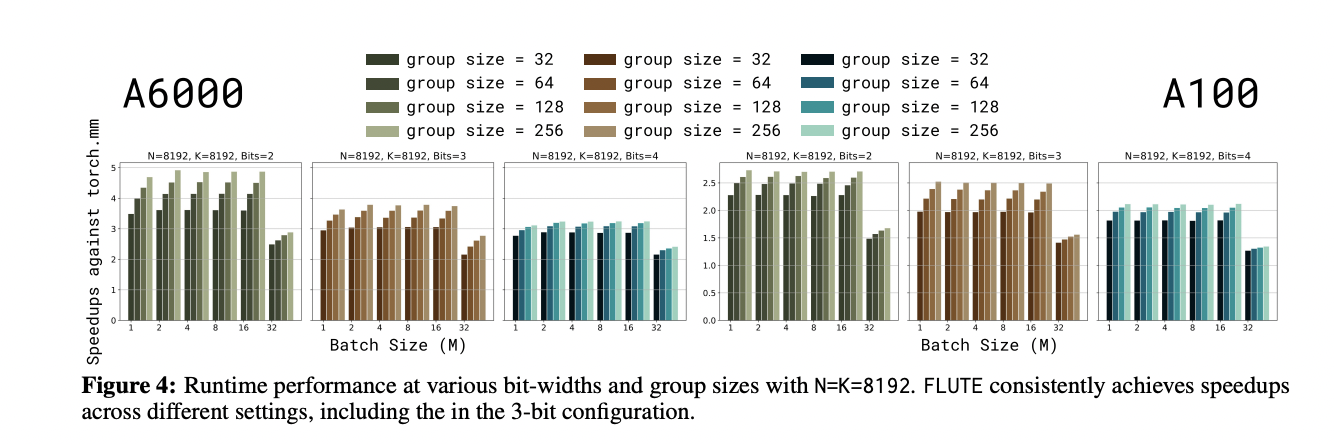
FLUTE demonstrates superior efficiency in LLM deployment throughout varied quantization settings. The realized NF quantization strategy outperforms customary strategies and combines effectively with AWQ. FLUTE’s flexibility permits for experiments with totally different bit widths and group sizes, practically matching 16-bit baseline perplexity with small group sizes. Finish-to-end latency assessments utilizing vLLM framework confirmed significant speedups throughout varied configurations, together with with Gemma-2 fashions. A gaggle measurement of 64 was discovered to stability high quality and velocity successfully. Total, FLUTE proves to be a flexible and environment friendly answer for quantized LLM deployment, providing improved efficiency throughout a number of eventualities.
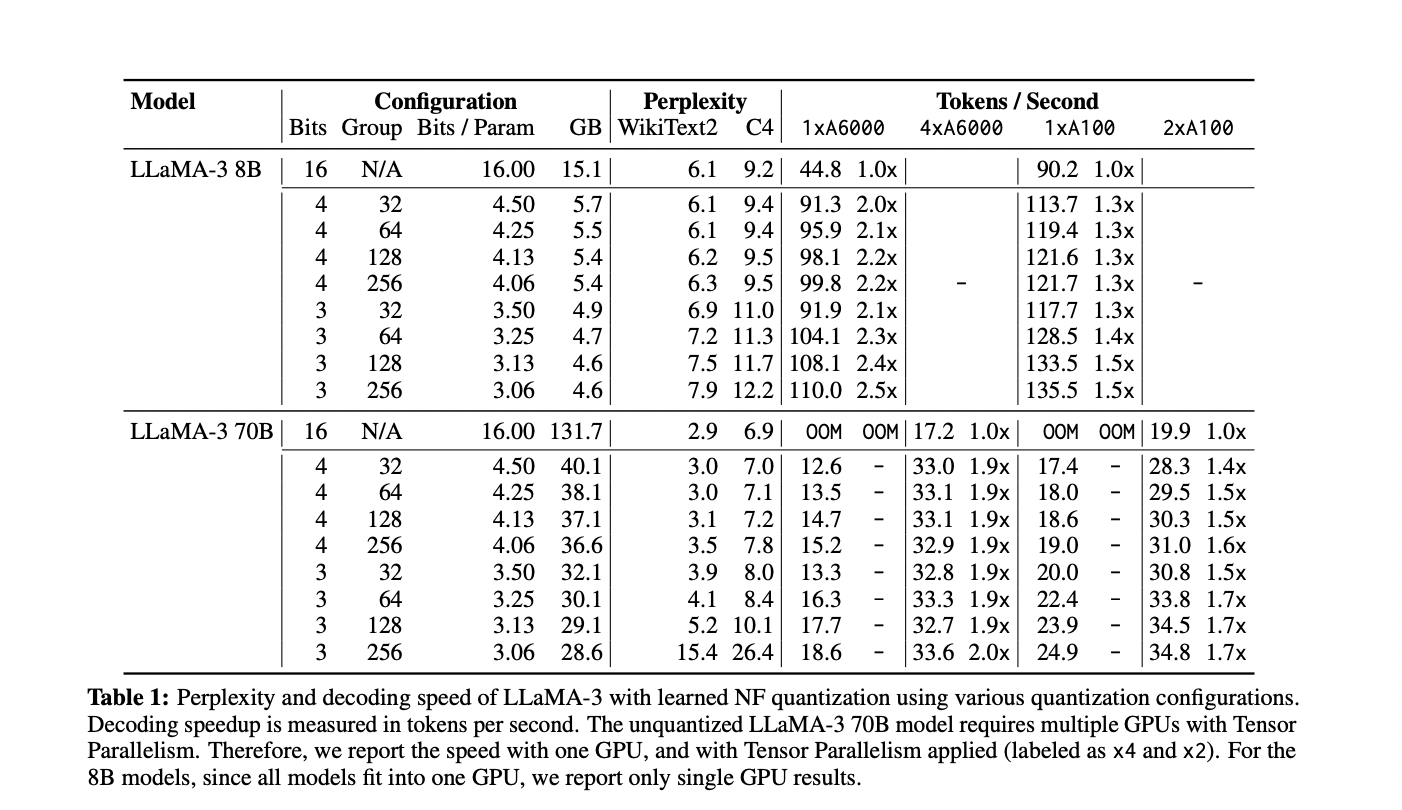
FLUTE is a CUDA kernel designed to speed up LLM inference by means of fused quantized matrix multiplications. It provides flexibility in mapping quantized to de-quantized values through lookup tables and helps varied bit widths and group sizes. FLUTE’s efficiency is demonstrated by means of kernel-level benchmarks and end-to-end evaluations on state-of-the-art LLMs like LLaMA-3 and Gemma-2. Examined on A6000 and A100 GPUs in single and tensor parallel setups, FLUTE exhibits effectivity throughout unquantized, 3-bit, and 4-bit configurations. This versatility and efficiency make FLUTE a promising answer for accelerating LLM inference utilizing superior quantization methods.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.



